Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss
作者: Xinyu Zhang, Zicheng Duan, Dong Gong, Lingqiao Liu
分类: cs.CV
发布日期: 2025-01-13
备注: Project page: https://zhangxinyu-xyz.github.io/SimulateMotion.github.io/
💡 一句话要点
提出基于运动一致性损失的免训练运动引导视频生成方法,提升时序一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 运动引导 时序一致性 免训练 扩散模型
📋 核心要点
- 现有运动引导视频生成方法难以在免训练条件下保持良好的时序一致性和运动控制精度。
- 通过捕捉参考视频的帧间特征相关模式,并设计运动一致性损失来引导生成过程,实现精确运动控制。
- 实验结果表明,该方法在提高时序一致性的同时,保持了免训练的优势,并达到了新的性能水平。
📝 摘要(中文)
本文旨在解决运动引导视频生成中时序一致性问题。现有方法通常依赖额外的控制模块或推理时微调,而最近的研究表明,无需改变模型架构或额外训练即可实现有效的运动引导。尽管如此,现有的免训练方法难以维持帧间一致的时序连贯性或准确遵循引导运动。为此,我们提出了一种简单而有效的解决方案,将基于初始噪声的方法与一种新颖的运动一致性损失相结合,后者是我们的关键创新。具体而言,我们捕获视频扩散模型中间特征的帧间特征相关模式,以表示参考视频的运动模式。然后,我们设计了一种运动一致性损失,以在生成的视频中保持相似的特征相关模式,并利用该损失在潜在空间中的梯度来引导生成过程,从而实现精确的运动控制。该方法在各种运动控制任务中提高了时序一致性,同时保留了免训练设置的优势。大量实验表明,我们的方法为高效、时序连贯的视频生成树立了新标准。
🔬 方法详解
问题定义:现有运动引导视频生成方法,特别是免训练方法,在保持生成视频的时序一致性方面存在困难。它们要么无法准确地遵循引导运动,要么在帧与帧之间产生不连贯的视觉效果。这些问题限制了这些方法在实际应用中的可用性。
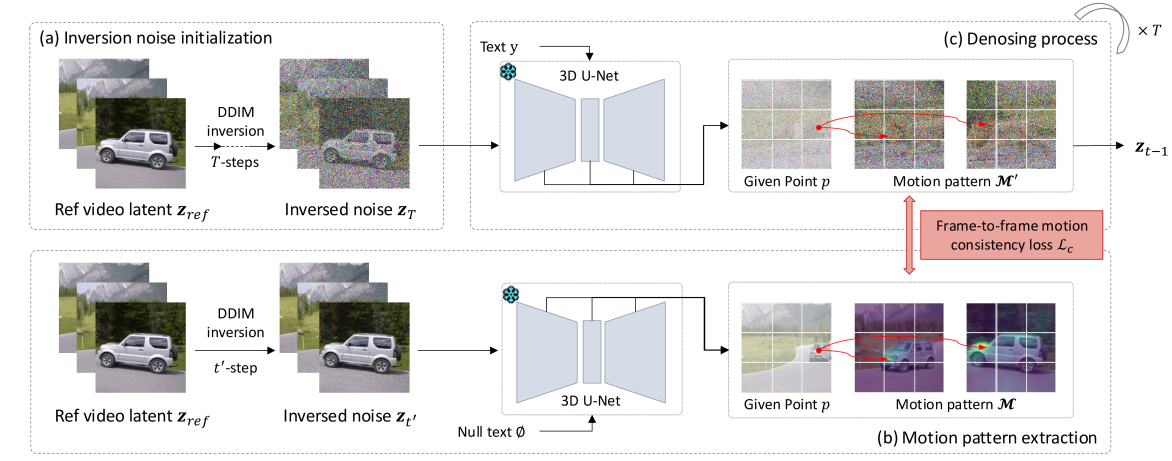
核心思路:本文的核心思路是利用参考视频的运动模式来指导生成过程,并确保生成的视频具有相似的运动模式,从而实现时序一致性。通过在视频扩散模型的中间特征中捕获帧间特征相关模式,并设计运动一致性损失来鼓励生成的视频保持这些模式,可以有效地实现这一目标。
技术框架:该方法基于一个预训练的视频扩散模型。首先,使用参考视频提取中间特征的帧间相关模式。然后,在生成视频时,计算生成视频的中间特征的帧间相关模式,并使用运动一致性损失来衡量其与参考视频的相似度。最后,利用运动一致性损失的梯度来引导生成过程,从而生成具有时序一致性的视频。
关键创新:该方法最关键的创新在于提出了运动一致性损失。该损失函数能够有效地衡量生成视频和参考视频之间的运动模式相似度,并利用该相似度来指导生成过程。与现有方法相比,该方法无需额外的训练或微调,即可实现有效的运动引导和时序一致性。
关键设计:运动一致性损失的具体形式是基于中间特征的帧间相关矩阵的差异。具体来说,对于参考视频和生成视频,分别计算其中间特征的帧间相关矩阵,然后计算这两个矩阵之间的L2距离。该L2距离即为运动一致性损失。在生成过程中,通过反向传播该损失的梯度,可以调整生成视频的中间特征,使其更接近参考视频的运动模式。
🖼️ 关键图片


📊 实验亮点
该方法在多个运动控制任务上取得了显著的性能提升,尤其是在时序一致性方面。实验结果表明,该方法能够生成具有高度时序一致性的视频,并且能够准确地遵循引导运动。与其他免训练方法相比,该方法在视觉质量和运动控制精度方面均有明显优势。具体性能数据未知,但论文强调该方法设立了新的标准。
🎯 应用场景
该研究成果可广泛应用于视频编辑、特效制作、游戏开发等领域。例如,可以用于生成具有特定运动模式的视频内容,或者将一个视频的运动风格迁移到另一个视频上。此外,该方法还可以用于视频修复和增强,提高视频的质量和观赏性。未来,该技术有望在虚拟现实、增强现实等新兴领域发挥重要作用。
📄 摘要(原文)
In this paper, we address the challenge of generating temporally consistent videos with motion guidance. While many existing methods depend on additional control modules or inference-time fine-tuning, recent studies suggest that effective motion guidance is achievable without altering the model architecture or requiring extra training. Such approaches offer promising compatibility with various video generation foundation models. However, existing training-free methods often struggle to maintain consistent temporal coherence across frames or to follow guided motion accurately. In this work, we propose a simple yet effective solution that combines an initial-noise-based approach with a novel motion consistency loss, the latter being our key innovation. Specifically, we capture the inter-frame feature correlation patterns of intermediate features from a video diffusion model to represent the motion pattern of the reference video. We then design a motion consistency loss to maintain similar feature correlation patterns in the generated video, using the gradient of this loss in the latent space to guide the generation process for precise motion control. This approach improves temporal consistency across various motion control tasks while preserving the benefits of a training-free setup. Extensive experiments show that our method sets a new standard for efficient, temporally coherent video generation.