Aligning First, Then Fusing: A Novel Weakly Supervised Multimodal Violence Detection Method
作者: Wenping Jin, Li Zhu, Jing Sun
分类: cs.CV
发布日期: 2025-01-13 (更新: 2025-03-14)
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种弱监督多模态暴力检测方法,通过模态对齐提升检测精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱监督学习 多模态融合 暴力检测 语义特征对齐 视频理解
📋 核心要点
- 现有弱监督多模态暴力检测方法主要关注模态融合,忽略了模态间差异带来的信息互补。
- 该方法通过语义特征对齐,将信息量较少的模态特征映射到RGB特征空间,充分利用各模态信息。
- 实验表明,该方法在XD-Violence数据集上取得了显著效果,平均精度达到86.07%。
📝 摘要(中文)
本文提出了一种新颖的弱监督多模态暴力检测方法,旨在利用视频级别的标签来识别视频中的暴力片段。与现有方法侧重于设计多模态融合模型以解决模态差异不同,本文利用暴力事件表示中固有的模态差异,提出了一种多模态语义特征对齐方法。该方法将局部、瞬时和信息量较少的模态(如音频和光流)的语义特征稀疏地映射到信息量更大的RGB语义特征空间。通过迭代过程,识别合适的非零特征匹配子空间,并在此基础上对齐特定模态的事件表示,从而在后续的模态融合阶段充分利用所有模态的信息。在此基础上,设计了一个新的弱监督暴力检测框架,包括用于提取单模态语义特征的单模态多示例学习、多模态对齐、多模态融合和最终检测。在基准数据集上的实验结果表明了该方法的有效性,在XD-Violence数据集上实现了86.07%的平均精度(AP)。
🔬 方法详解
问题定义:现有的弱监督多模态暴力检测方法主要集中在设计复杂的模态融合策略,以弥合不同模态之间的差异。然而,这些方法往往忽略了不同模态在表示暴力事件时所具有的互补性,例如音频可能捕捉到尖叫声,光流可能捕捉到快速运动,而RGB模态则提供更全面的视觉信息。因此,如何有效利用不同模态的差异性信息,是当前方法的一个痛点。
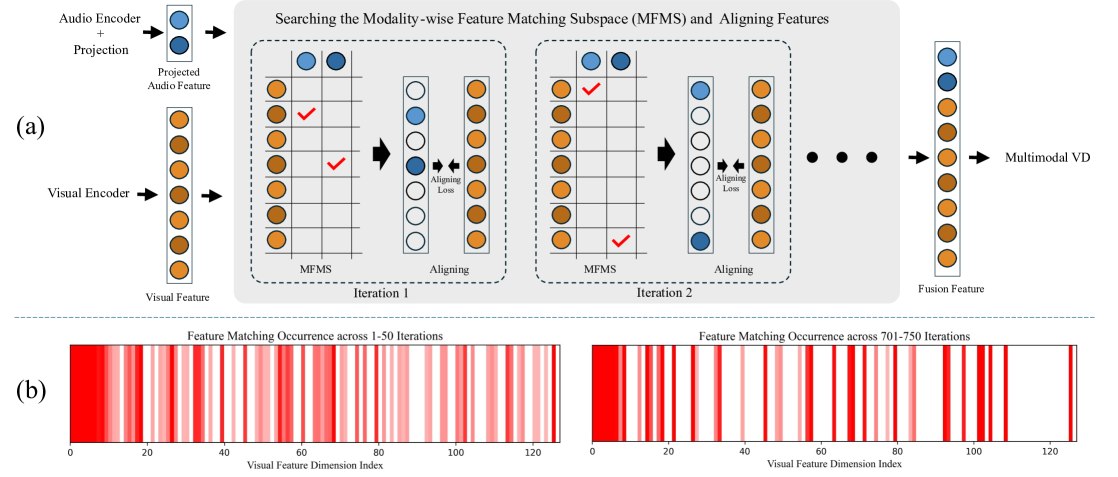
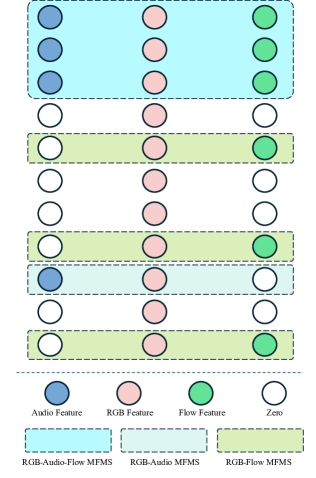
核心思路:本文的核心思路是首先对齐不同模态的语义特征,然后再进行融合。具体来说,将信息量较少、局部性较强的模态(如音频和光流)的特征,映射到信息量更大、全局性更强的RGB模态的特征空间中。通过这种方式,可以有效地利用不同模态的互补信息,提高暴力检测的准确性。这种“先对齐,后融合”的策略,旨在更好地利用模态间的差异性,而不是简单地消除差异。
技术框架:该框架主要包含四个阶段:1) 单模态多示例学习:使用多示例学习从每个模态中提取语义特征。2) 多模态对齐:将音频和光流等模态的特征对齐到RGB模态的特征空间。3) 多模态融合:将对齐后的多模态特征进行融合,得到最终的视频表示。4) 最终检测:使用分类器对视频表示进行分类,判断视频是否包含暴力事件。
关键创新:该方法最重要的创新点在于提出了多模态语义特征对齐方法。与现有方法直接融合不同模态的特征不同,该方法首先将不同模态的特征对齐到一个共同的语义空间,然后再进行融合。这种对齐操作能够更好地利用不同模态的互补信息,提高暴力检测的准确性。此外,该方法采用稀疏映射的方式进行特征对齐,可以有效地减少计算量,提高算法的效率。
关键设计:在多模态对齐阶段,使用迭代的方式寻找合适的非零特征匹配子空间。具体来说,首先随机初始化一个映射矩阵,然后通过迭代的方式更新该矩阵,使得对齐后的特征之间的距离最小化。损失函数的设计目标是最小化对齐后特征之间的距离,同时保证映射矩阵的稀疏性。在单模态特征提取阶段,使用了多示例学习,每个视频被分割成多个片段,只有包含暴力事件的片段才会被认为是正例。
🖼️ 关键图片

📊 实验亮点
该方法在XD-Violence数据集上取得了显著的性能提升,平均精度(AP)达到了86.07%。相较于现有的弱监督多模态暴力检测方法,该方法在精度上有明显的优势。实验结果表明,该方法提出的多模态语义特征对齐方法能够有效地利用不同模态的互补信息,提高暴力检测的准确性。代码已开源,方便研究人员复现和进一步研究。
🎯 应用场景
该研究成果可应用于智能监控、视频内容审核、社会安全等领域。例如,在公共场所的监控系统中,该方法可以自动检测暴力事件,及时发出警报,从而提高社会安全性。在视频网站的内容审核中,该方法可以自动识别包含暴力内容的视频,减少人工审核的工作量。此外,该方法还可以用于分析社交媒体上的视频内容,了解社会暴力事件的发生情况。
📄 摘要(原文)
Weakly supervised violence detection refers to the technique of training models to identify violent segments in videos using only video-level labels. Among these approaches, multimodal violence detection, which integrates modalities such as audio and optical flow, holds great potential. Existing methods in this domain primarily focus on designing multimodal fusion models to address modality discrepancies. In contrast, we take a different approach; leveraging the inherent discrepancies across modalities in violence event representation to propose a novel multimodal semantic feature alignment method. This method sparsely maps the semantic features of local, transient, and less informative modalities ( such as audio and optical flow ) into the more informative RGB semantic feature space. Through an iterative process, the method identifies the suitable no-zero feature matching subspace and aligns the modality-specific event representations based on this subspace, enabling the full exploitation of information from all modalities during the subsequent modality fusion stage. Building on this, we design a new weakly supervised violence detection framework that consists of unimodal multiple-instance learning for extracting unimodal semantic features, multimodal alignment, multimodal fusion, and final detection. Experimental results on benchmark datasets demonstrate the effectiveness of our method, achieving an average precision (AP) of 86.07% on the XD-Violence dataset. Our code is available at https://github.com/xjpp2016/MAVD.