Localization-Aware Multi-Scale Representation Learning for Repetitive Action Counting
作者: Sujia Wang, Xiangwei Shen, Yansong Tang, Xin Dong, Wenjia Geng, Lei Chen
分类: cs.CV
发布日期: 2025-01-13
备注: Accepted by IEEE VCIP2024
💡 一句话要点
提出LMRL框架,通过定位感知多尺度表示学习提升重复动作计数精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 重复动作计数 多尺度表示学习 前景定位 视频分析 周期性动作
📋 核心要点
- 现有重复动作计数方法易受噪声干扰,导致计数性能下降,尤其是在真实场景中。
- 提出LMRL框架,通过引入前景定位优化目标,学习更鲁棒和高效的视频特征表示。
- 实验结果表明,该方法能有效降低噪声影响,显著提升重复动作计数精度,且具有良好的可扩展性。
📝 摘要(中文)
本文提出了一种用于重复动作计数(RAC)的定位感知多尺度表示学习(LMRL)框架。现有RAC方法主要依赖原始帧间相似性表示进行周期预测,易受动作中断和不一致等噪声干扰。为了获得更鲁棒和高效的视频特征,本文将前景定位优化目标引入相似性表示学习。LMRL框架包含多尺度周期感知表示(MPR)和重复前景定位(RFL)两个模块。MPR采用尺度特定设计,适应不同的动作频率,学习更灵活的时间相关性。RFL通过粗略识别周期性动作并结合全局语义信息来增强表示。这两个模块可以联合优化,从而产生更具辨别力的周期性动作表示。该方法显著降低了噪声的影响,提高了计数精度。该框架具有可扩展性,适用于不同类型的视频内容。在RepCountA和UCFRep数据集上的实验结果表明,该方法能有效处理重复动作计数。
🔬 方法详解
问题定义:重复动作计数(RAC)旨在无需示例的情况下,估计视频中类别无关的动作发生次数。现有方法主要依赖原始帧间相似性,易受动作中断、不一致等噪声干扰,导致周期预测不准确,计数性能受限。
核心思路:通过引入前景定位优化目标,增强视频特征表示的鲁棒性和区分性。具体而言,通过多尺度周期感知表示(MPR)学习不同频率的动作模式,并通过重复前景定位(RFL)模块关注周期性动作区域,抑制背景噪声。
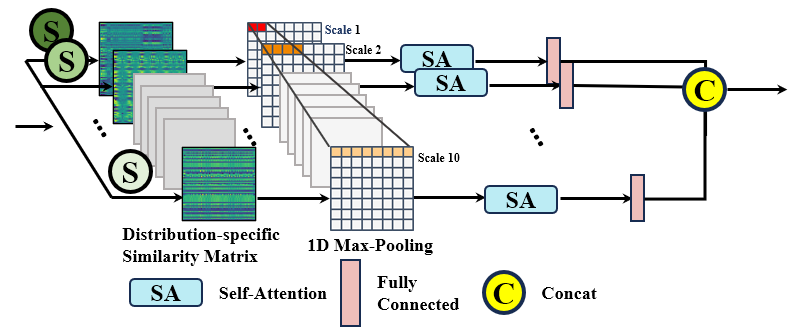
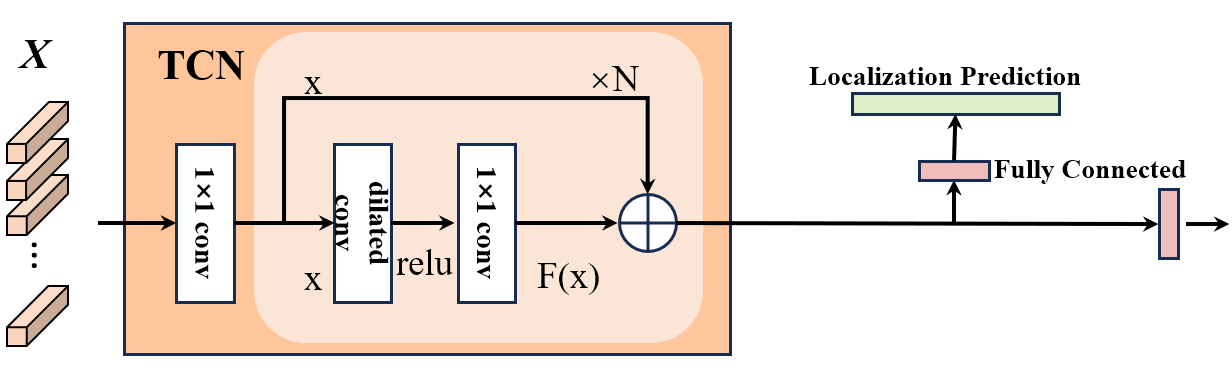
技术框架:LMRL框架包含两个主要模块:MPR和RFL。MPR首先提取多尺度特征,然后利用周期感知模块学习不同时间尺度的动作相关性。RFL模块则通过粗略定位重复动作区域,并结合全局语义信息,进一步增强特征表示。这两个模块联合优化,最终用于重复动作计数。
关键创新:将前景定位优化引入到相似性表示学习中,从而使模型能够更关注周期性动作本身,减少背景噪声的干扰。多尺度周期感知表示(MPR)的设计能够适应不同频率的动作,提高模型的泛化能力。
关键设计:MPR模块采用多分支结构,每个分支处理不同尺度的特征。RFL模块使用弱监督学习方法,通过预测像素级别的重复性得分来定位前景区域。损失函数包括周期预测损失、前景定位损失和全局语义一致性损失,共同优化整个框架。
🖼️ 关键图片
📊 实验亮点
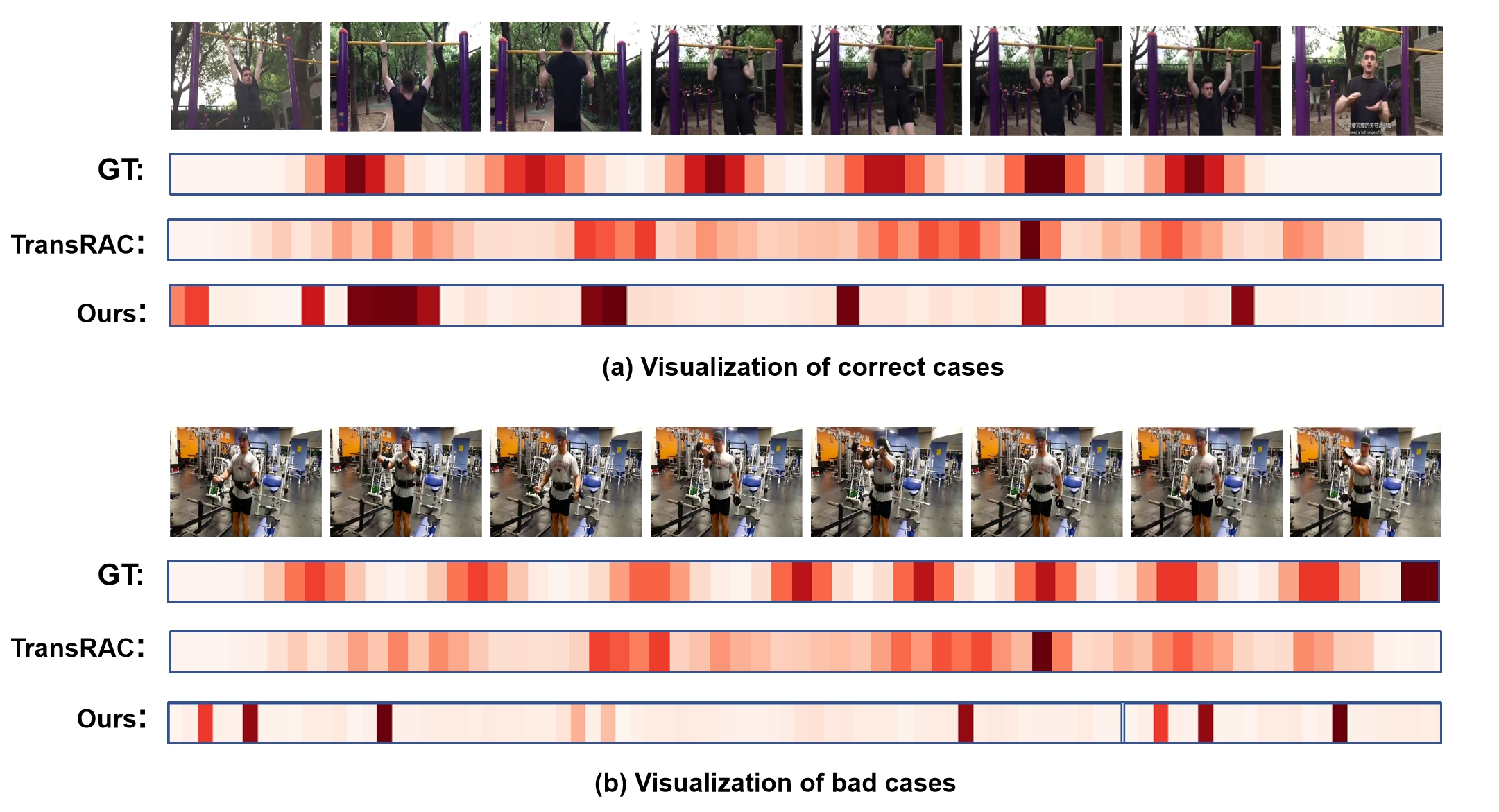
在RepCountA和UCFRep数据集上的实验结果表明,所提出的LMRL框架能够有效提升重复动作计数精度。相较于现有方法,该方法在两个数据集上均取得了显著的性能提升,证明了其在处理噪声和复杂场景下的优越性。具体提升幅度数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于视频监控、运动分析、工业自动化等领域。例如,在视频监控中,可以自动统计特定动作的发生次数,如人群计数、车辆计数等。在运动分析中,可以用于分析运动员的训练动作,评估训练效果。在工业自动化中,可以用于检测生产线上重复性操作的次数,提高生产效率。
📄 摘要(原文)
Repetitive action counting (RAC) aims to estimate the number of class-agnostic action occurrences in a video without exemplars. Most current RAC methods rely on a raw frame-to-frame similarity representation for period prediction. However, this approach can be significantly disrupted by common noise such as action interruptions and inconsistencies, leading to sub-optimal counting performance in realistic scenarios. In this paper, we introduce a foreground localization optimization objective into similarity representation learning to obtain more robust and efficient video features. We propose a Localization-Aware Multi-Scale Representation Learning (LMRL) framework. Specifically, we apply a Multi-Scale Period-Aware Representation (MPR) with a scale-specific design to accommodate various action frequencies and learn more flexible temporal correlations. Furthermore, we introduce the Repetition Foreground Localization (RFL) method, which enhances the representation by coarsely identifying periodic actions and incorporating global semantic information. These two modules can be jointly optimized, resulting in a more discerning periodic action representation. Our approach significantly reduces the impact of noise, thereby improving counting accuracy. Additionally, the framework is designed to be scalable and adaptable to different types of video content. Experimental results on the RepCountA and UCFRep datasets demonstrate that our proposed method effectively handles repetitive action counting.