Skip Mamba Diffusion for Monocular 3D Semantic Scene Completion
作者: Li Liang, Naveed Akhtar, Jordan Vice, Xiangrui Kong, Ajmal Saeed Mian
分类: cs.CV, cs.AI
发布日期: 2025-01-13
备注: Accepted by AAAI 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Skip Mamba扩散模型,用于单目3D语义场景补全,显著提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D语义场景补全 单目视觉 扩散模型 状态空间模型 Mamba 深度学习 自动驾驶 机器人
📋 核心要点
- 现有3D语义场景补全方法在复杂现实环境中,需要处理多模态数据,模型复杂且性能提升有限。
- 论文提出Skip Mamba扩散模型,在变分自编码器的潜在空间中进行扩散建模,高效处理长序列数据。
- 实验表明,该方法在SemanticKITTI和SSCBench-KITTI360数据集上,显著优于其他单目方法,并与立体方法竞争。
📝 摘要(中文)
本文提出了一种新颖的神经模型,利用状态空间和扩散生成建模的最新进展,实现了卓越的单目图像3D语义场景补全性能。该技术在变分自编码器的条件潜在空间中处理数据,并使用创新的状态空间技术进行扩散建模。该神经网络的关键组成部分是所提出的Skimba(Skip Mamba)去噪器,它擅长高效处理长序列数据。Skimba扩散模型是3D场景补全网络不可或缺的一部分,它结合了三重Mamba结构、维度分解残差和沿三个方向变化的不同膨胀率。我们还采用了该网络的一个变体,用于该方法的后续语义分割阶段。在标准SemanticKITTI和SSCBench-KITTI360数据集上的大量评估表明,我们的方法不仅大幅优于其他单目技术,而且在性能上与立体方法相比也具有竞争力。代码已在https://github.com/xrkong/skimba上提供。
🔬 方法详解
问题定义:论文旨在解决单目图像的3D语义场景补全问题。现有方法通常需要复杂的多模态数据处理,计算成本高昂,且在真实场景中性能受限。单目图像的3D场景补全面临着严重的深度信息缺失和遮挡问题,导致几何和语义信息的推断非常困难。
核心思路:论文的核心思路是利用状态空间模型(SSM)Mamba的高效长序列建模能力,结合扩散模型强大的生成能力,在变分自编码器的潜在空间中进行3D场景的补全。通过在低维潜在空间中进行扩散过程,降低了计算复杂度,同时利用Mamba模型捕获场景中的长程依赖关系。
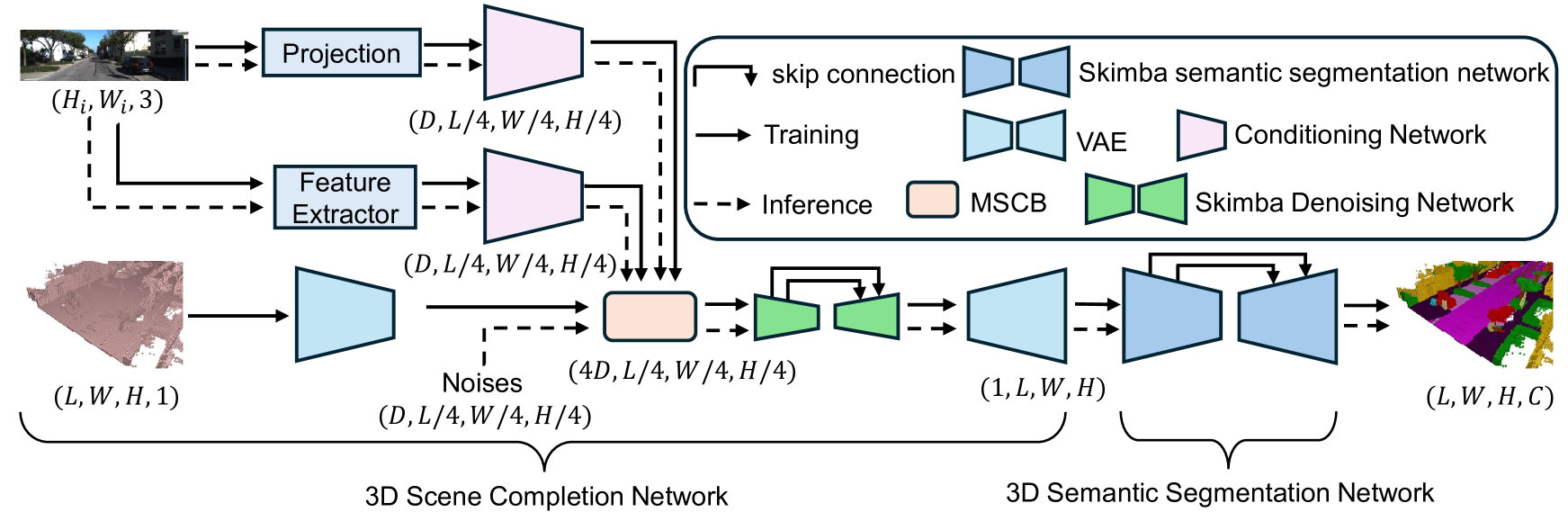
技术框架:整体框架包含三个主要阶段:1) 使用变分自编码器(VAE)将单目图像编码到低维潜在空间;2) 在潜在空间中使用Skip Mamba扩散模型进行3D场景补全,该模型通过逐步去噪的方式生成完整的3D场景表示;3) 使用解码器将补全后的潜在表示解码回3D体素空间,并进行语义分割。
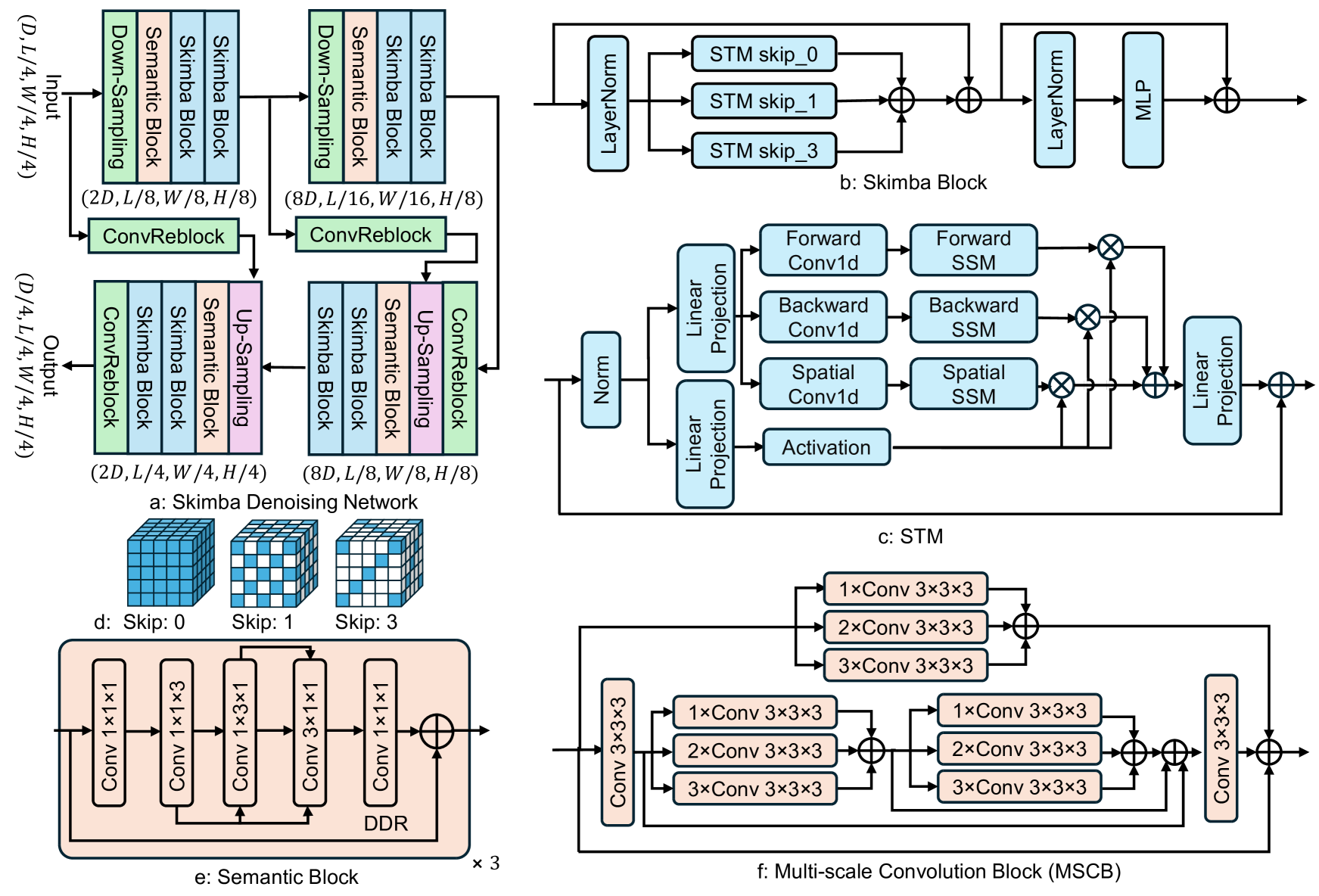
关键创新:论文的关键创新在于提出了Skip Mamba扩散模型,该模型结合了Mamba模型的高效长序列建模能力和扩散模型的生成能力。Skip Mamba模型采用三重Mamba结构,并引入了维度分解残差和沿三个方向变化的不同膨胀率,从而能够更有效地捕获3D场景中的复杂结构和长程依赖关系。
关键设计:Skip Mamba模型的核心是Mamba块,它是一种基于选择机制的状态空间模型。论文采用了三重Mamba结构,即在每个残差块中堆叠三个Mamba层,以增强模型的表达能力。维度分解残差是指将残差连接分解为沿三个维度的独立残差连接,从而减少参数量并提高训练效率。不同膨胀率的设计允许模型在不同尺度上捕获场景信息。损失函数包括VAE的重构损失和扩散模型的负对数似然损失。
🖼️ 关键图片
📊 实验亮点
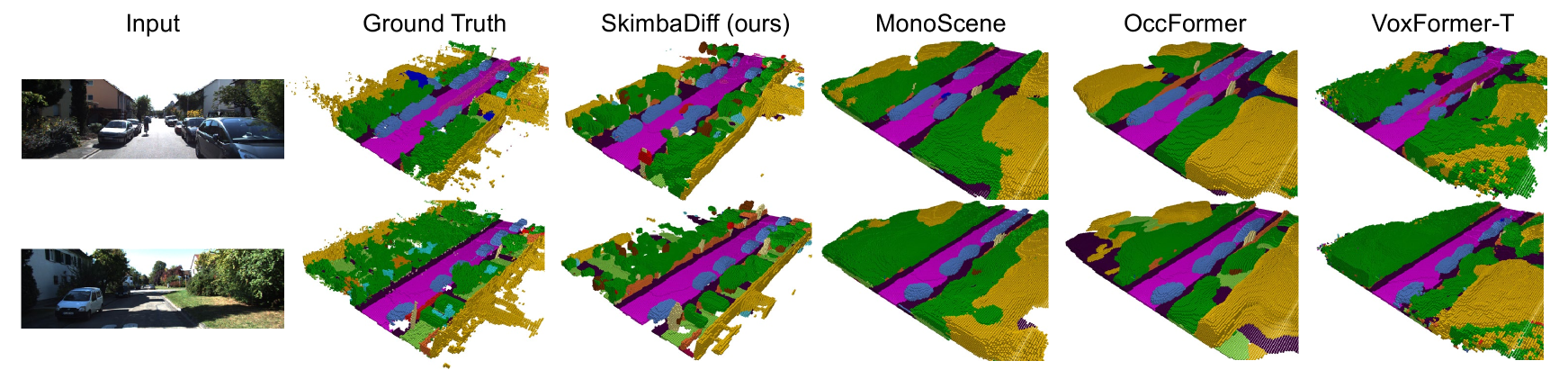
实验结果表明,该方法在SemanticKITTI和SSCBench-KITTI360数据集上取得了显著的性能提升。在SemanticKITTI数据集上,该方法在3D语义场景补全任务上优于其他单目方法,并且与一些立体方法相比也具有竞争力。具体而言,该方法在IoU等指标上取得了显著提升,表明其能够更准确地补全场景中的几何和语义信息。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实等领域。在自动驾驶中,可以利用单目摄像头补全周围环境的3D信息,提高感知能力和安全性。在机器人导航中,可以帮助机器人理解周围环境,规划更合理的路径。在虚拟现实中,可以生成更逼真的3D场景,提升用户体验。
📄 摘要(原文)
3D semantic scene completion is critical for multiple downstream tasks in autonomous systems. It estimates missing geometric and semantic information in the acquired scene data. Due to the challenging real-world conditions, this task usually demands complex models that process multi-modal data to achieve acceptable performance. We propose a unique neural model, leveraging advances from the state space and diffusion generative modeling to achieve remarkable 3D semantic scene completion performance with monocular image input. Our technique processes the data in the conditioned latent space of a variational autoencoder where diffusion modeling is carried out with an innovative state space technique. A key component of our neural network is the proposed Skimba (Skip Mamba) denoiser, which is adept at efficiently processing long-sequence data. The Skimba diffusion model is integral to our 3D scene completion network, incorporating a triple Mamba structure, dimensional decomposition residuals and varying dilations along three directions. We also adopt a variant of this network for the subsequent semantic segmentation stage of our method. Extensive evaluation on the standard SemanticKITTI and SSCBench-KITTI360 datasets show that our approach not only outperforms other monocular techniques by a large margin, it also achieves competitive performance against stereo methods. The code is available at https://github.com/xrkong/skimba