Matching-Free Depth Recovery from Structured Light
作者: Zhuohang Yu, Kai Wang, Kun Huang, Juyong Zhang
分类: cs.CV
发布日期: 2025-01-13 (更新: 2025-06-25)
备注: 13 pages, 10 figures
💡 一句话要点
提出一种无匹配的结构光深度恢复方法,提升几何精度和训练速度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 结构光 深度估计 无匹配 体素网格 可微渲染 自监督学习 三维重建
📋 核心要点
- 传统结构光深度估计依赖图像匹配,易受噪声和遮挡影响,精度和鲁棒性受限。
- 利用密度体素网格和自监督可微渲染,避免图像匹配,直接优化场景几何表示。
- 实验表明,该方法在合成和真实场景中均优于基于匹配的方法,且训练速度更快。
📝 摘要(中文)
本文提出了一种新的单目结构光系统深度估计方法。与依赖图像匹配的现有方法不同,该技术采用密度体素网格来表示场景几何,并通过自监督可微体积渲染进行训练。该方法利用结构光系统中投影图案导出的颜色场进行渲染,从而实现几何场的独立优化,加速收敛并提高结果质量。此外,集成了归一化设备坐标(NDC)、畸变损失和独特的基于表面的颜色损失,以增强几何保真度。实验结果表明,在少量样本场景中,该方法在几何性能方面优于当前的基于匹配的技术,在合成场景和真实场景中,平均估计深度误差降低了约30%。此外,该方法的训练速度比以前使用隐式表示的无匹配方法快约三倍。
🔬 方法详解
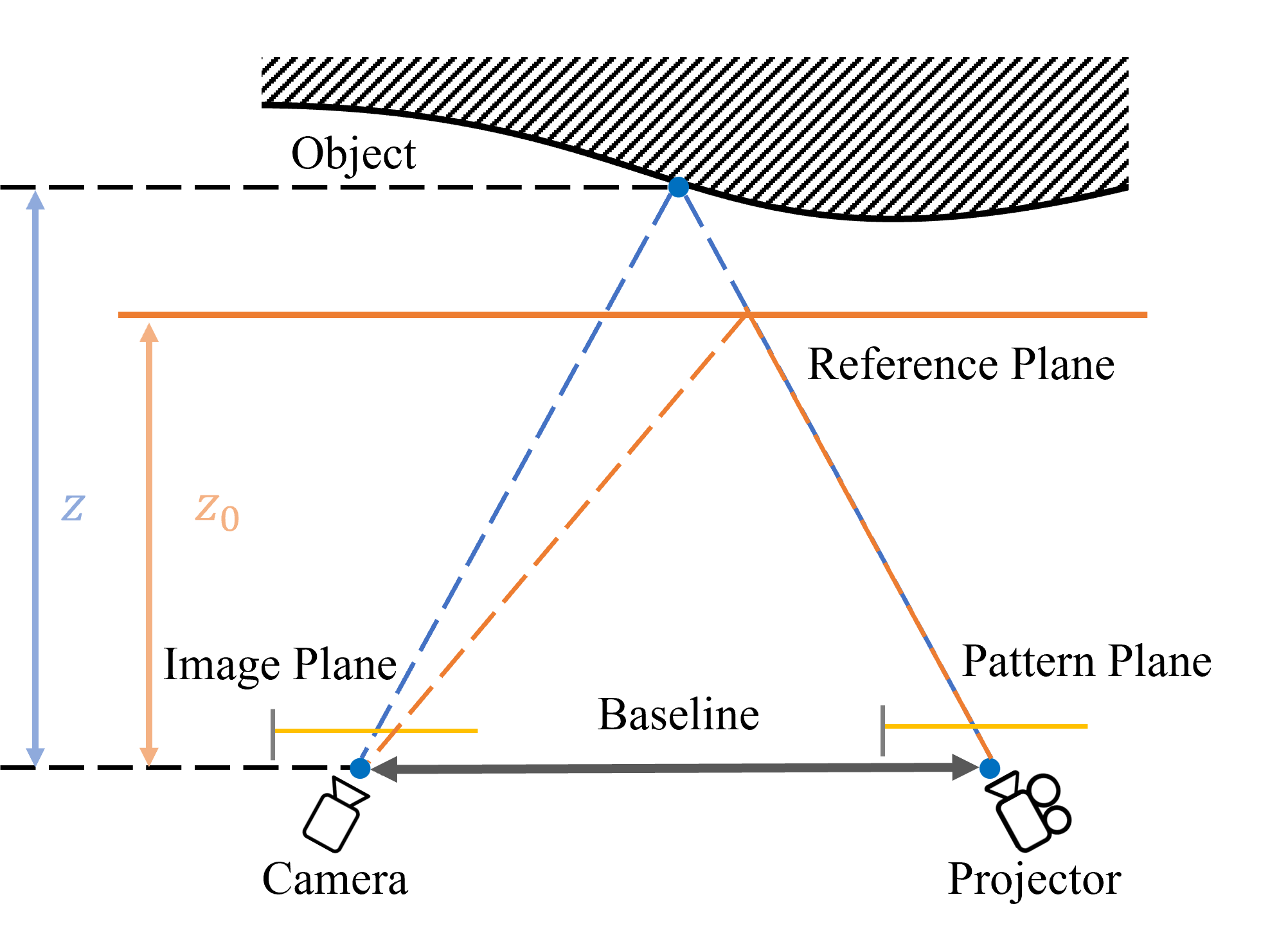
问题定义:现有结构光深度估计方法通常依赖于图像匹配,通过寻找投影图案在不同图像中的对应关系来恢复深度。然而,图像匹配容易受到噪声、遮挡和光照变化的影响,导致深度估计精度下降,尤其是在纹理缺失或复杂场景中。此外,匹配过程本身也比较耗时。
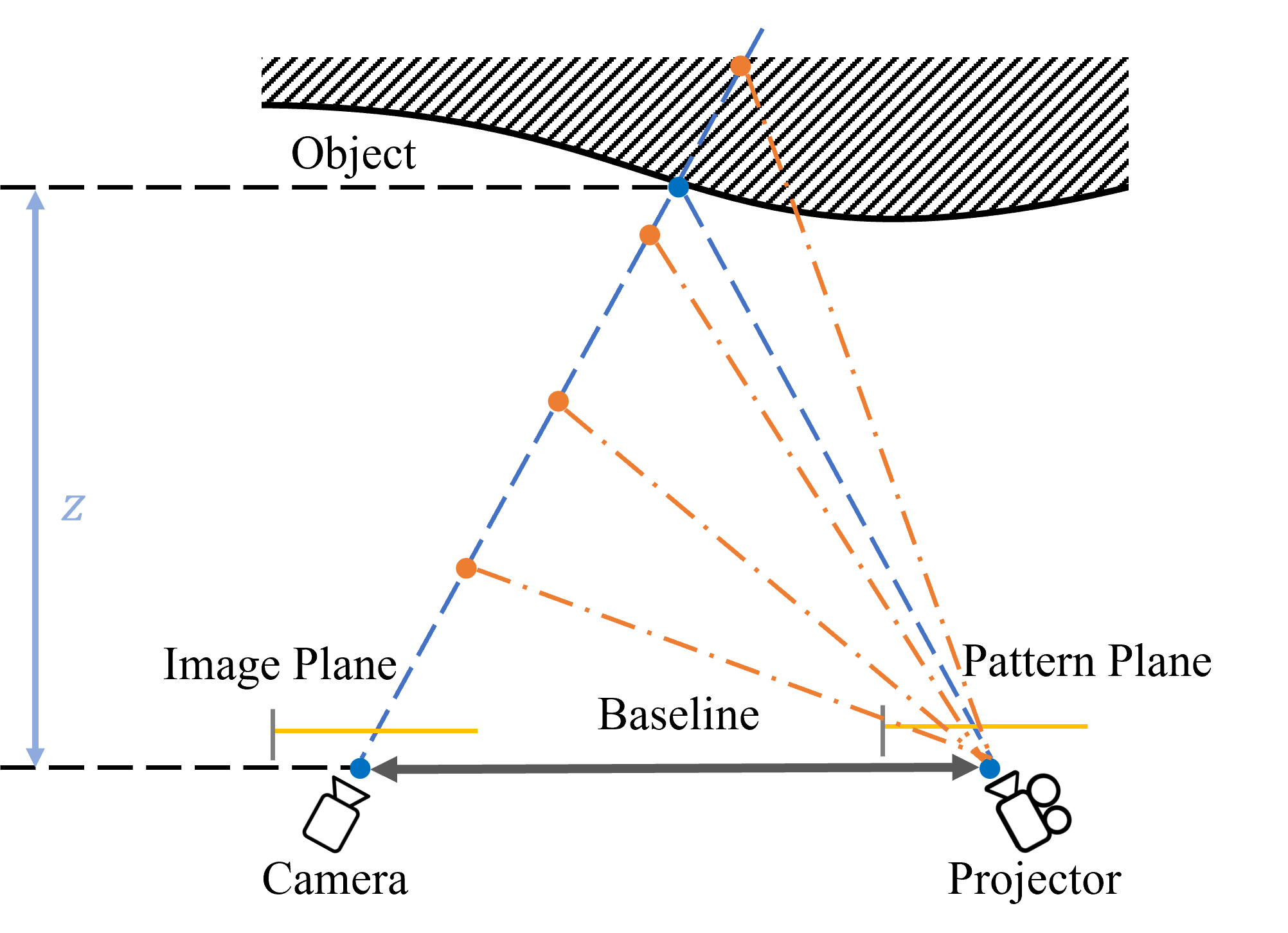
核心思路:本文的核心思路是避免图像匹配,直接从单目结构光图像中学习场景的几何表示。具体来说,使用密度体素网格来表示场景几何,并通过自监督可微体积渲染来训练该网格。通过优化渲染图像与输入图像之间的差异,可以间接地优化场景几何,从而实现深度估计。
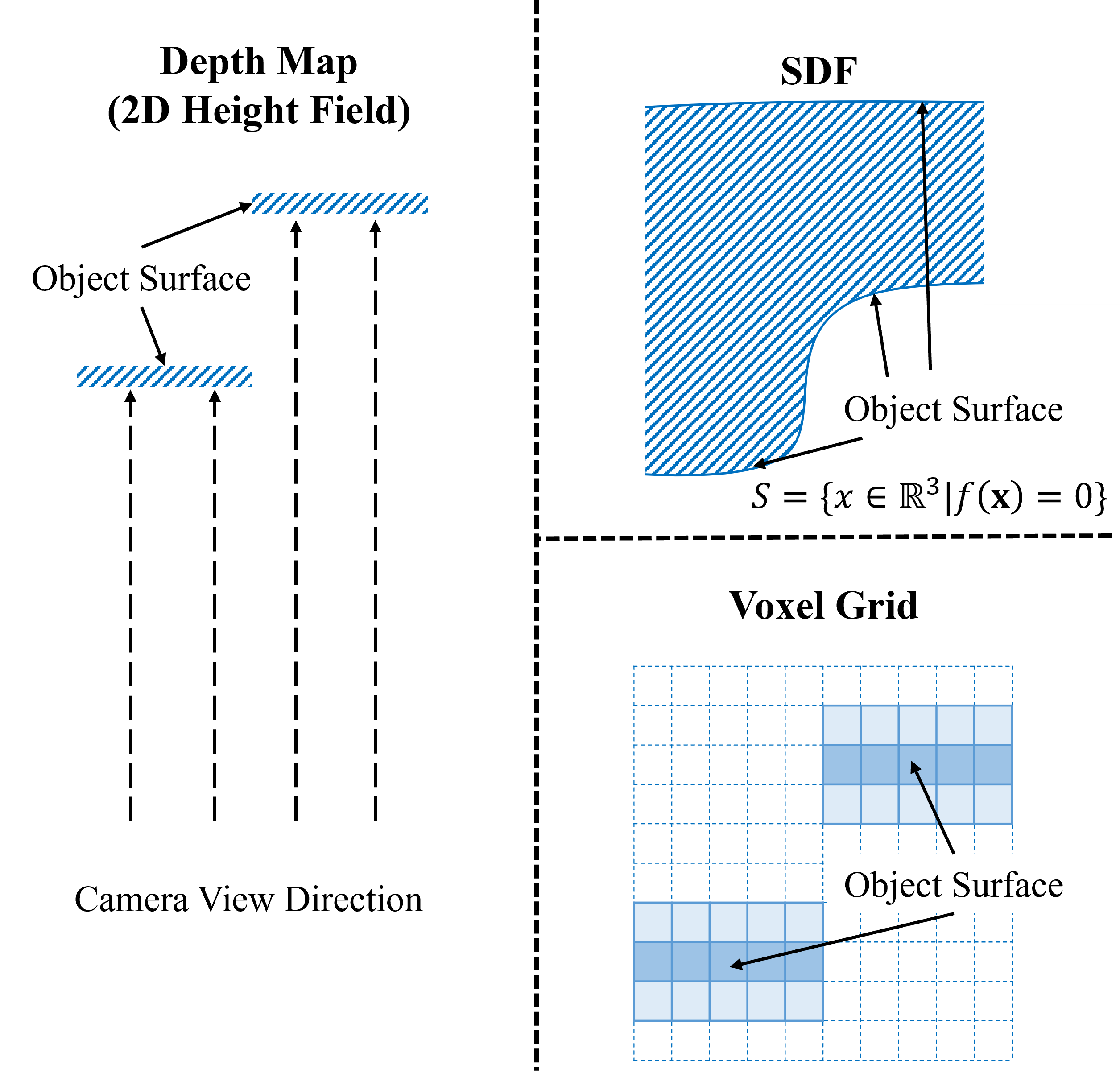
技术框架:该方法主要包含以下几个模块:1) 密度体素网格:用于表示场景的几何形状,每个体素存储一个密度值,表示该位置存在表面的概率。2) 可微体积渲染:将密度体素网格渲染成图像,通过光线步进算法,沿着每条光线累积颜色和密度值。3) 颜色场:利用结构光投影图案的颜色信息,为每个体素赋予一个颜色值,用于渲染过程。4) 自监督损失函数:包括渲染图像与输入图像之间的颜色损失、畸变损失和基于表面的颜色损失,用于优化密度体素网格。
关键创新:该方法最重要的创新点在于提出了无匹配的结构光深度估计方法。与传统的基于匹配的方法相比,该方法避免了复杂的图像匹配过程,可以直接从图像中学习场景几何。此外,该方法还利用了结构光投影图案的颜色信息,并设计了新的损失函数,从而提高了深度估计的精度和鲁棒性。
关键设计:1) 归一化设备坐标(NDC):用于将场景坐标映射到[-1, 1]的范围内,从而提高训练的稳定性。2) 畸变损失:用于惩罚渲染图像中的畸变,从而提高几何精度。3) 基于表面的颜色损失:用于鼓励渲染图像中的颜色与输入图像中的颜色一致,从而提高深度估计的准确性。4) 网络结构:使用简单的MLP网络来预测每个体素的密度和颜色值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在合成和真实场景中均优于现有的基于匹配的方法。在少量样本场景中,平均估计深度误差降低了约30%。此外,该方法的训练速度比以前使用隐式表示的无匹配方法快约三倍。这些结果表明,该方法在深度估计精度和训练效率方面都具有显著优势。
🎯 应用场景
该研究成果可应用于三维重建、机器人导航、工业检测、文物数字化等领域。无匹配的深度恢复方法降低了对环境纹理的依赖,提高了在复杂光照和遮挡条件下的鲁棒性,使得结构光技术能够应用于更广泛的场景。未来,该方法有望与SLAM等技术结合,实现更精确、更高效的三维场景理解。
📄 摘要(原文)
We introduce a novel approach for depth estimation using images obtained from monocular structured light systems. In contrast to many existing methods that depend on image matching, our technique employs a density voxel grid to represent scene geometry. This grid is trained through self-supervised differentiable volume rendering. Our method leverages color fields derived from the projected patterns in structured light systems during the rendering process, facilitating the isolated optimization of the geometry field. This innovative approach leads to faster convergence and high-quality results. Additionally, we integrate normalized device coordinates (NDC), a distortion loss, and a distinctive surface-based color loss to enhance geometric fidelity. Experimental results demonstrate that our method outperforms current matching-based techniques in terms of geometric performance in few-shot scenarios, achieving an approximately 30% reduction in average estimated depth errors for both synthetic scenes and real-world captured scenes. Moreover, our approach allows for rapid training, being approximately three times faster than previous matching-free methods that utilize implicit representations.