Rethinking Knowledge in Distillation: An In-context Sample Retrieval Perspective
作者: Jinjing Zhu, Songze Li, Lin Wang
分类: cs.CV
发布日期: 2025-01-13
💡 一句话要点
提出IC-KD框架,通过上下文样本检索视角重新定义知识蒸馏,提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 上下文学习 样本检索 模型压缩 深度学习
📋 核心要点
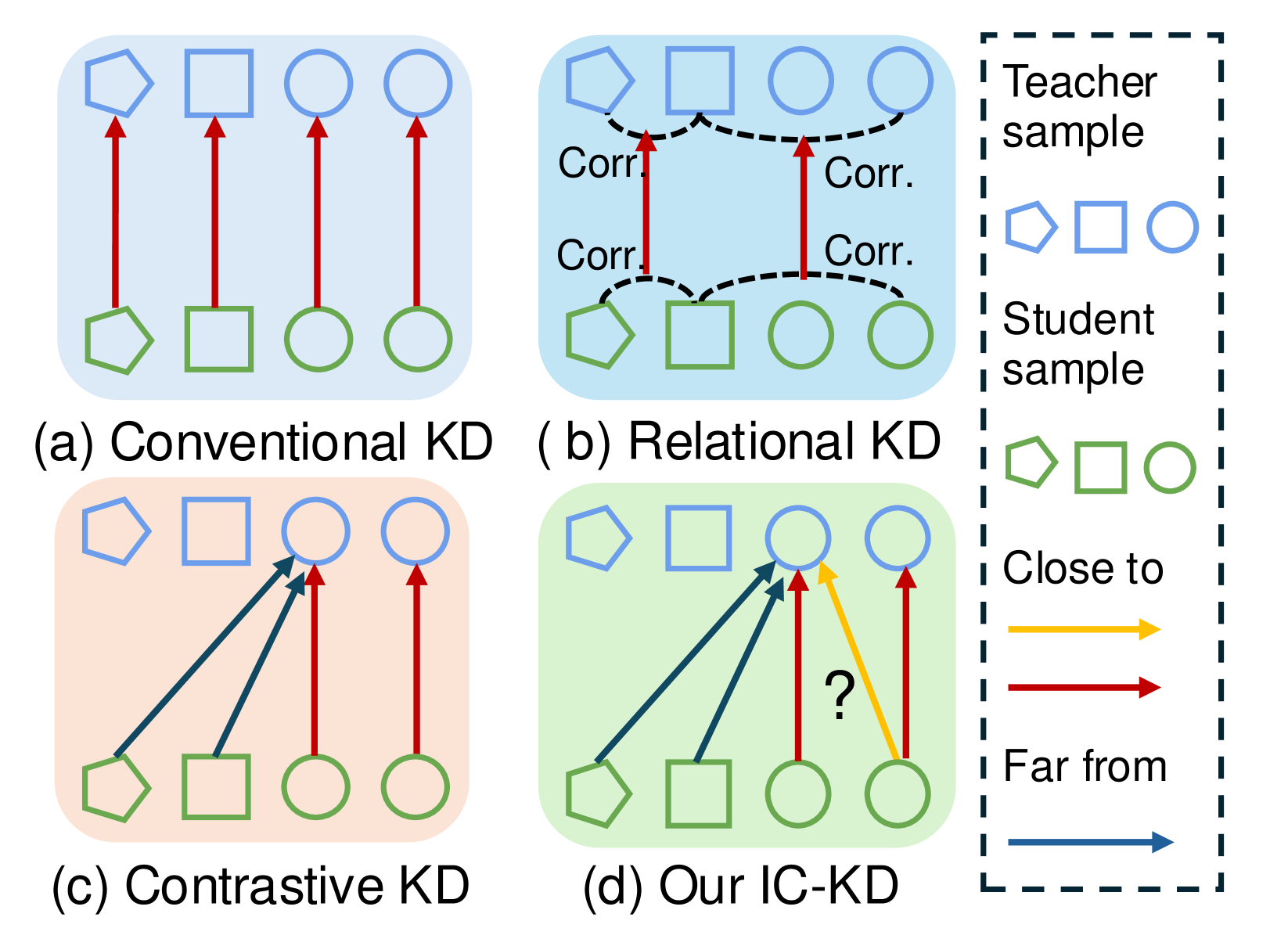
- 传统知识蒸馏忽略了样本间的关系,导致学生模型学习到的知识不够全面。
- IC-KD通过检索上下文样本,利用样本间的关系进行知识蒸馏,从而提升学生模型性能。
- 实验表明,IC-KD在多种KD范式下均有效,并在CIFAR-100和ImageNet上取得了SOTA性能。
📝 摘要(中文)
传统的知识蒸馏(KD)方法旨在使学生模型预测与教师模型相似的输出。然而,它们通常忽略了同一类别样本之间的关系。本文重新定义了知识蒸馏中的知识,捕捉每个样本与其上下文样本(一组具有相同或不同类别的相似样本)之间的关系,并从上下文样本检索的角度执行KD。由于KD是一种学习到的标签平滑正则化(LSR),我们首先进行理论分析,表明来自上下文样本的教师知识是使用相应样本正则化学生训练的关键因素。在分析的支持下,我们提出了一个新颖的上下文知识蒸馏(IC-KD)框架,该框架在各种KD范例(离线、在线和无教师KD)中都显示出其优越性。首先,我们从教师模型构建特征记忆库,并通过基于检索的学习为每个样本检索上下文样本。然后,我们引入正上下文蒸馏(PICD)来减少学生样本与教师模型中同一类别的聚合上下文样本在logit空间中的差异。此外,引入负上下文蒸馏(NICD)来分离学生样本与教师模型中不同类别的上下文样本。大量实验表明,IC-KD在各种类型的KD中均有效,并且在CIFAR-100和ImageNet数据集上始终达到最先进的性能。
🔬 方法详解
问题定义:现有知识蒸馏方法主要关注单个样本的知识迁移,忽略了样本之间的关联性,特别是同一类别或不同类别但语义相似的样本之间的关系。这种忽略导致学生模型无法充分学习到教师模型的知识,限制了模型的泛化能力和鲁棒性。
核心思路:本文的核心思路是利用上下文样本之间的关系来指导知识蒸馏。通过检索与目标样本相似的样本(上下文样本),并利用这些上下文样本的知识来正则化学生模型的训练,从而使学生模型能够学习到更丰富的知识。这样做的原因是,相似的样本往往具有相似的特征表示和预测结果,利用这些信息可以帮助学生模型更好地理解目标样本。
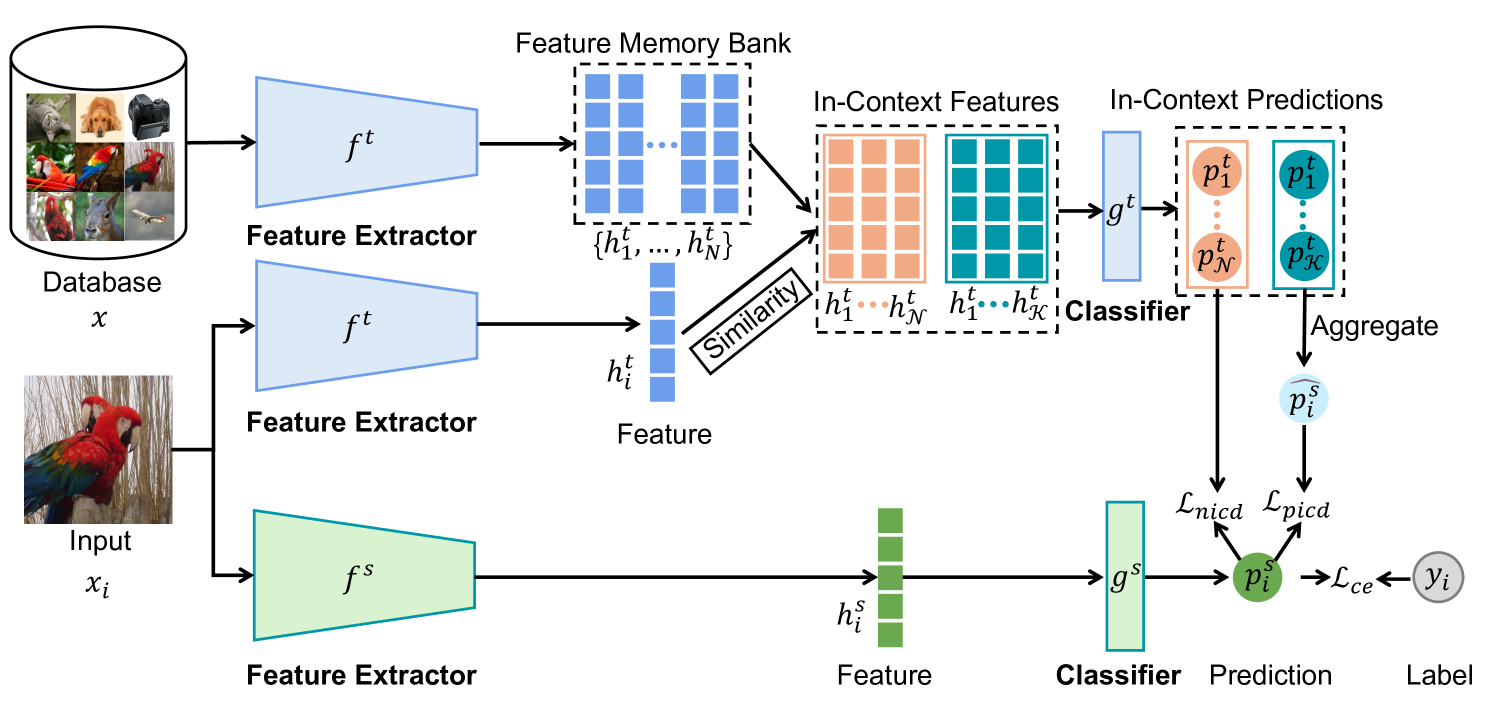
技术框架:IC-KD框架主要包含以下几个模块:1) 特征记忆库构建:利用教师模型提取训练集中所有样本的特征,构建特征记忆库。2) 上下文样本检索:对于每个样本,从特征记忆库中检索与其最相似的K个样本作为上下文样本。3) 正上下文蒸馏(PICD):缩小学生模型中目标样本与教师模型中同一类别的上下文样本在logit空间的差异。4) 负上下文蒸馏(NICD):增大学生模型中目标样本与教师模型中不同类别的上下文样本在logit空间的差异。
关键创新:IC-KD的关键创新在于将上下文样本检索引入知识蒸馏,并设计了正负上下文蒸馏损失函数。与传统KD方法只关注单个样本的知识迁移不同,IC-KD利用样本之间的关系来指导知识蒸馏,从而使学生模型能够学习到更丰富的知识。此外,通过正负上下文蒸馏,可以更好地利用上下文样本的信息,提高学生模型的性能。
关键设计:1) 特征记忆库的构建方式:使用教师模型提取的特征作为样本的表示。2) 上下文样本检索的相似度度量:可以使用余弦相似度等度量方式。3) 正负上下文蒸馏的损失函数设计:PICD旨在缩小同一类别样本之间的差异,NICD旨在增大不同类别样本之间的差异。4) 上下文样本的数量K:需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
IC-KD在CIFAR-100和ImageNet数据集上取得了显著的性能提升。例如,在CIFAR-100上,IC-KD在多种KD范式下均优于现有的SOTA方法。在ImageNet上,IC-KD也取得了具有竞争力的结果,证明了其在大型数据集上的有效性。具体性能数据需要在论文中查找。
🎯 应用场景
IC-KD框架可广泛应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测、以及自然语言处理中的文本分类等。通过知识蒸馏,可以将大型、复杂的教师模型压缩成小型、高效的学生模型,从而在资源受限的设备上实现高性能的AI应用。此外,IC-KD通过利用上下文信息,可以提高学生模型的鲁棒性和泛化能力,使其在复杂场景下也能表现良好。
📄 摘要(原文)
Conventional knowledge distillation (KD) approaches are designed for the student model to predict similar output as the teacher model for each sample. Unfortunately, the relationship across samples with same class is often neglected. In this paper, we explore to redefine the knowledge in distillation, capturing the relationship between each sample and its corresponding in-context samples (a group of similar samples with the same or different classes), and perform KD from an in-context sample retrieval perspective. As KD is a type of learned label smoothing regularization (LSR), we first conduct a theoretical analysis showing that the teacher's knowledge from the in-context samples is a crucial contributor to regularize the student training with the corresponding samples. Buttressed by the analysis, we propose a novel in-context knowledge distillation (IC-KD) framework that shows its superiority across diverse KD paradigms (offline, online, and teacher-free KD). Firstly, we construct a feature memory bank from the teacher model and retrieve in-context samples for each corresponding sample through retrieval-based learning. We then introduce Positive In-Context Distillation (PICD) to reduce the discrepancy between a sample from the student and the aggregated in-context samples with the same class from the teacher in the logit space. Moreover, Negative In-Context Distillation (NICD) is introduced to separate a sample from the student and the in-context samples with different classes from the teacher in the logit space. Extensive experiments demonstrate that IC-KD is effective across various types of KD, and consistently achieves state-of-the-art performance on CIFAR-100 and ImageNet datasets.