X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
作者: Wenqi Zhou, Kai Cao, Hao Zheng, Yunze Liu, Xinyi Zheng, Miao Liu, Per Ola Kristensson, Walterio Mayol-Cuevas, Fan Zhang, Weizhe Lin, Junxiao Shen
分类: cs.CV
发布日期: 2025-01-12 (更新: 2025-11-11)
💡 一句话要点
提出X-LeBench,用于评估极长第一人称视角视频理解能力,填补了现有基准数据集的空白。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 第一人称视角视频 长时视频理解 基准数据集 生活记录模拟 具身智能
📋 核心要点
- 现有第一人称视角视频数据集长度有限,难以评估模型在极长时间跨度下的理解能力,限制了相关技术发展。
- X-LeBench通过模拟生活记录生成超长视频,结合合成日常计划与真实视频片段,构建了大规模的评测基准。
- 实验表明,现有模型在X-LeBench上表现不佳,揭示了长时视频理解在时间推理、上下文聚合等方面的挑战。
📝 摘要(中文)
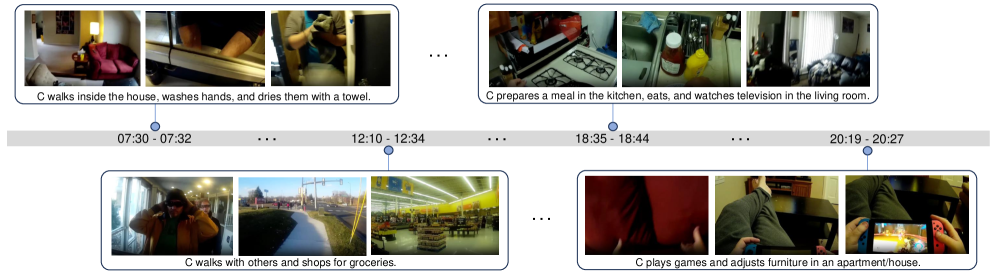
本文提出了X-LeBench,一个新的基准数据集,旨在解决极长第一人称视角视频理解的难题。现有的基准数据集主要集中于单个、较短(几分钟到几十分钟)或中等长度的视频,在评估大规模、超长第一人称视角视频记录方面存在显著差距。X-LeBench通过一个生活记录模拟流程生成,该流程能够产生与真实世界视频数据对齐的、逼真的、连贯的日常计划。这种方法能够灵活地将合成的日常计划与来自Ego4D(一个大规模第一人称视角视频数据集,涵盖广泛的日常生活场景)的真实视频片段相结合,从而生成432个模拟视频生活记录,时长从23分钟到16.4小时不等。对多个基线系统和多模态大型语言模型(MLLM)的评估表明,它们的性能普遍较差,突显了长时第一人称视角视频理解的内在挑战,例如时间定位和推理、上下文聚合和记忆保持,并强调了对更先进模型的需求。
🔬 方法详解
问题定义:现有第一人称视角视频理解数据集主要集中于短视频或中等长度视频,缺乏对极长时间跨度视频的评估能力。这使得研究人员难以开发和评估能够理解长期人类行为的模型,阻碍了具身智能、长期活动分析和个性化辅助技术的发展。现有方法在处理超长视频时,面临时间定位和推理、上下文聚合、记忆保持等挑战。
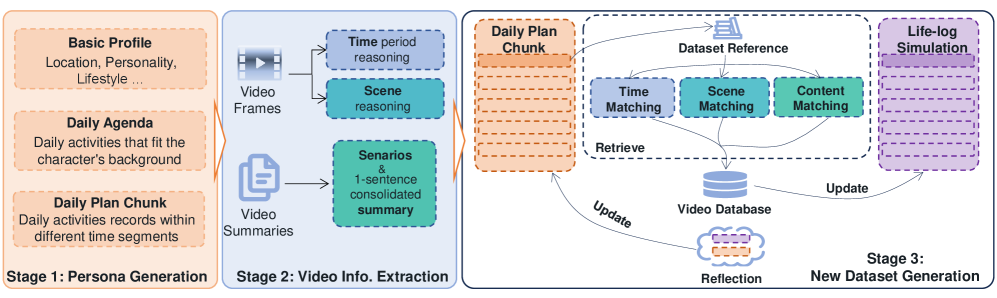
核心思路:X-LeBench的核心思路是通过生活记录模拟流程生成超长视频。该流程能够产生与真实世界视频数据对齐的、逼真的、连贯的日常计划。通过将合成的日常计划与来自Ego4D的真实视频片段相结合,可以灵活地生成各种长度和内容的视频,从而构建一个大规模的、具有挑战性的基准数据集。这样设计的目的是为了更好地模拟真实世界中人类的长期行为,并为研究人员提供一个评估模型在长时间跨度下理解能力的标准平台。
技术框架:X-LeBench的构建主要包含以下几个阶段:1) 设计生活记录模拟流程,生成与真实世界视频数据对齐的日常计划;2) 从Ego4D数据集中选择合适的视频片段;3) 将合成的日常计划与真实视频片段相结合,生成模拟视频生活记录;4) 对生成的视频进行标注,构建评估数据集。整个流程的关键在于如何生成逼真的日常计划,以及如何将这些计划与真实视频片段无缝地结合起来。
关键创新:X-LeBench最重要的技术创新点在于其生活记录模拟流程。该流程能够根据真实世界的数据,生成逼真的日常计划,从而模拟人类的长期行为。与以往的数据集相比,X-LeBench的视频长度更长,内容更复杂,更接近真实世界的情况。此外,X-LeBench还提供了一套完整的评估指标,方便研究人员对模型进行评估。
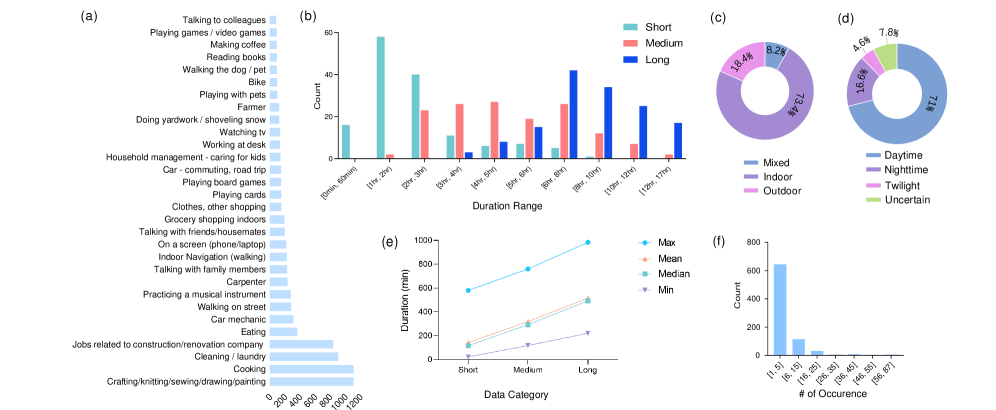
关键设计:在生活记录模拟流程中,需要考虑日常活动的类型、持续时间、发生顺序等因素。为了保证生成计划的真实性,需要对真实世界的数据进行分析,提取出日常活动的统计规律。在将合成计划与真实视频片段相结合时,需要进行时间对齐和内容匹配,以保证视频的连贯性。此外,还需要对视频进行标注,包括活动的类型、发生时间、参与者等信息。这些标注信息可以用于评估模型的理解能力。
🖼️ 关键图片
📊 实验亮点
对多个基线系统和多模态大型语言模型(MLLM)在X-LeBench上的评估表明,它们的性能普遍较差,突显了长时第一人称视角视频理解的内在挑战。这表明现有模型在处理超长视频时,面临时间定位和推理、上下文聚合、记忆保持等方面的困难,需要进一步的研究和改进。
🎯 应用场景
X-LeBench的应用场景广泛,包括具身智能、长期活动分析、个性化辅助技术等。例如,可以用于开发能够理解用户长期行为的智能助手,或者用于监测老年人的日常生活,及时发现异常情况。此外,X-LeBench还可以促进长时视频理解算法的研究,推动相关技术的发展。
📄 摘要(原文)
Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short (\eg, minutes to tens of minutes) to moderately long videos, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset meticulously designed to fill this gap by focusing on tasks requiring a comprehensive understanding of extremely long egocentric video recordings. Our X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs spanning from 23 minutes to 16.4 hours. The evaluations of several baseline systems and multimodal large language models (MLLMs) reveal their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding, such as temporal localization and reasoning, context aggregation, and memory retention, and underscoring the need for more advanced models.