Application of Vision-Language Model to Pedestrians Behavior and Scene Understanding in Autonomous Driving
作者: Haoxiang Gao, Li Zhang, Yu Zhao, Zhou Yang, Jinghan Cao
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2025-01-12 (更新: 2025-07-30)
💡 一句话要点
提出基于知识蒸馏的视觉-语言模型,用于提升自动驾驶中行人行为理解和场景感知能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言模型 知识蒸馏 行人行为预测 场景理解
📋 核心要点
- 现有方法在自动驾驶中理解与行人交互的复杂场景以及高效部署视觉-语言模型方面存在不足。
- 论文提出一种知识蒸馏方法,将大规模视觉-语言模型的知识迁移到高效的视觉网络,用于行人行为预测和场景理解。
- 实验结果表明,该方法在开放词汇感知和轨迹预测任务中取得了显著的性能提升,增强了自动驾驶的端到端性能。
📝 摘要(中文)
视觉-语言模型(VLMs)已成为增强自动驾驶感知和决策的一种有前景的方法。然而,将VLMs应用于理解与行人交互的复杂场景以及高效的车辆部署仍然存在差距。本文提出了一种知识蒸馏方法,将大规模视觉-语言基础模型的知识迁移到高效的视觉网络,并将其应用于行人行为预测和场景理解任务,在生成更多样化和全面的语义属性方面取得了可喜的成果。我们还利用多个预训练模型和集成技术来提高模型的性能。我们进一步检验了知识蒸馏后模型的有效性;结果表明,在开放词汇感知和轨迹预测任务中,指标得到了显著改善,这有可能提高自动驾驶的端到端性能。
🔬 方法详解
问题定义:自动驾驶系统需要准确理解行人的行为和周围场景,以便做出安全可靠的决策。现有的视觉模型在处理复杂场景和生成全面的语义属性方面存在局限性,并且难以直接应用大规模视觉-语言模型,因为后者通常计算成本较高,难以部署在资源受限的车辆上。
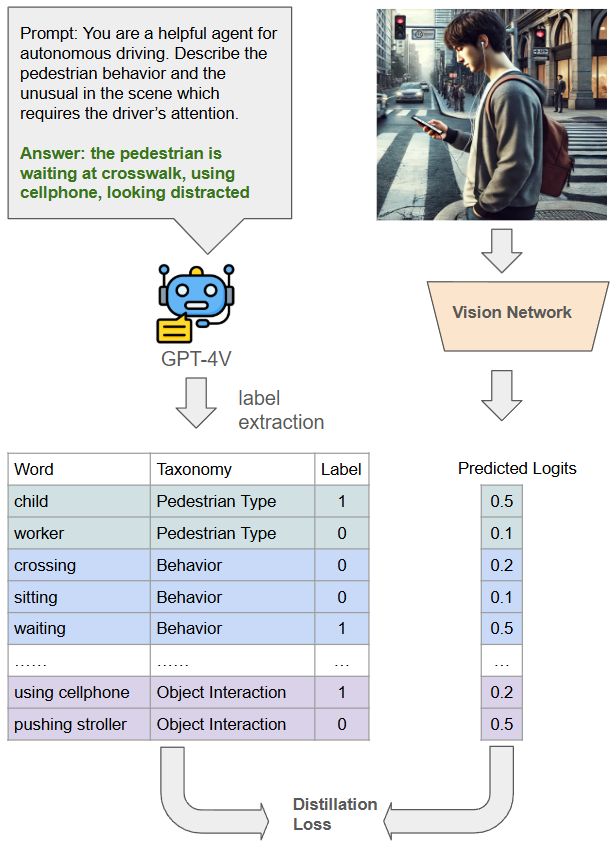
核心思路:论文的核心思路是利用知识蒸馏技术,将大规模视觉-语言基础模型(teacher model)的知识迁移到更小、更高效的视觉网络(student model)。这样既能保留VLMs的强大语义理解能力,又能降低计算成本,使其更适合在自动驾驶车辆上部署。
技术框架:整体框架包含以下几个主要步骤:1) 使用大规模VLM作为teacher model,对行人行为和场景进行理解,生成丰富的语义信息。2) 设计一个更小、更高效的视觉网络作为student model。3) 使用知识蒸馏技术,将teacher model的知识(例如,softmax输出、中间层特征等)迁移到student model。4) 使用多个预训练模型和集成技术进一步提升student model的性能。
关键创新:最重要的技术创新点在于将知识蒸馏技术应用于视觉-语言模型,并将其应用于自动驾驶中的行人行为预测和场景理解任务。与直接使用大型VLM相比,该方法显著降低了计算成本,使其更适合在实际应用中部署。此外,利用多个预训练模型和集成技术进一步提升了模型的性能。
关键设计:论文中可能涉及的关键设计包括:1) 选择合适的teacher model和student model。2) 设计有效的知识蒸馏损失函数,例如,使用KL散度损失来匹配teacher和student的softmax输出。3) 选择合适的预训练模型和集成策略,例如,使用不同的VLM模型进行集成,或者使用不同的数据增强方法来训练模型。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了知识蒸馏方法的有效性,在开放词汇感知和轨迹预测任务中取得了显著的性能提升。具体而言,该方法能够生成更多样化和全面的语义属性,从而提高自动驾驶系统对复杂场景的理解能力。实验结果表明,该方法具有很大的应用潜力,可以显著提升自动驾驶的端到端性能。
🎯 应用场景
该研究成果可应用于自动驾驶系统,提升其对行人行为的理解和场景感知能力,从而提高驾驶安全性。此外,该方法还可以推广到其他需要高效语义理解的机器人应用中,例如,服务机器人、物流机器人等。未来,该研究可以进一步探索更有效的知识蒸馏方法和更高效的视觉网络结构,以实现更强大的自动驾驶系统。
📄 摘要(原文)
Vision-language models (VLMs) have become a promising approach to enhancing perception and decision-making in autonomous driving. The gap remains in applying VLMs to understand complex scenarios interacting with pedestrians and efficient vehicle deployment. In this paper, we propose a knowledge distillation method that transfers knowledge from large-scale vision-language foundation models to efficient vision networks, and we apply it to pedestrian behavior prediction and scene understanding tasks, achieving promising results in generating more diverse and comprehensive semantic attributes. We also utilize multiple pre-trained models and ensemble techniques to boost the model's performance. We further examined the effectiveness of the model after knowledge distillation; the results show significant metric improvements in open-vocabulary perception and trajectory prediction tasks, which can potentially enhance the end-to-end performance of autonomous driving.