Natural Language Supervision for Low-light Image Enhancement
作者: Jiahui Tang, Kaihua Zhou, Zhijian Luo, Yueen Hou
分类: cs.CV, cs.AI
发布日期: 2025-01-11
备注: 12 pages, 10 figures
💡 一句话要点
提出基于自然语言监督的低光图像增强方法NaLSuper,实现视觉和文本特征对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低光图像增强 自然语言监督 跨模态学习 文本引导 特征融合 注意力机制 图像处理
📋 核心要点
- 现有低光图像增强方法依赖于“完美”参考图像,但难以定义,导致结果在指标和视觉效果上存在偏差。
- 提出自然语言监督策略,利用文本描述指导图像增强,通过视觉和文本特征对齐,提供更灵活的图像描述方式。
- 设计文本引导调节机制和信息融合注意力模块,有效融合多层次图像和文本信息,实验证明了方法的有效性和鲁棒性。
📝 摘要(中文)
随着深度学习的发展,低光图像增强(LLIE)领域涌现出大量表现出色的方法。主流LLIE方法通常基于低光和正常光图像对学习端到端映射。然而,不同光照条件下的正常光图像作为参考图像,难以定义“完美”的参考图像,导致了指标导向和视觉友好结果难以调和的挑战。最近,许多跨模态研究发现,来自其他相关模态的辅助信息可以指导视觉表征学习。基于此,我们引入了一种自然语言监督(NLS)策略,该策略从与图像对应的文本中学习特征图,为描述不同光照下的图像提供了一种通用且灵活的接口。然而,以文本描述为条件的图像分布是高度多模态的,这使得训练变得困难。为了解决这个问题,我们设计了一种文本引导调节机制(TCM),它结合了图像区域和句子单词之间的联系,增强了捕获图像和文本的细粒度跨模态线索的能力。该策略不仅利用了更广泛的监督来源,而且为基于视觉和文本特征对齐的LLIE提供了一种新的范例。为了有效地识别和融合来自不同级别的图像和文本信息的特征,我们设计了一个信息融合注意力(IFA)模块,以增强不同级别的不同区域。我们将提出的TCM和IFA集成到一个用于LLIE的自然语言监督网络中,命名为NaLSuper。最后,大量的实验证明了我们提出的NaLSuper的鲁棒性和卓越有效性。
🔬 方法详解
问题定义:现有低光图像增强方法依赖于成对的低光/正常光图像进行训练,但正常光图像在不同光照条件下存在差异,难以定义一个“完美”的参考图像。这导致模型在优化指标(如PSNR、SSIM)的同时,难以保证视觉效果的自然和真实。因此,如何利用更灵活的监督信息,提升低光图像增强的视觉质量,是一个重要的挑战。
核心思路:论文的核心思路是利用自然语言作为监督信号,指导低光图像的增强。通过将图像与对应的文本描述对齐,模型可以学习到更丰富的图像特征表示,从而更好地恢复图像的细节和色彩。这种方法避免了对“完美”参考图像的依赖,并允许模型根据文本描述生成不同风格的增强结果。
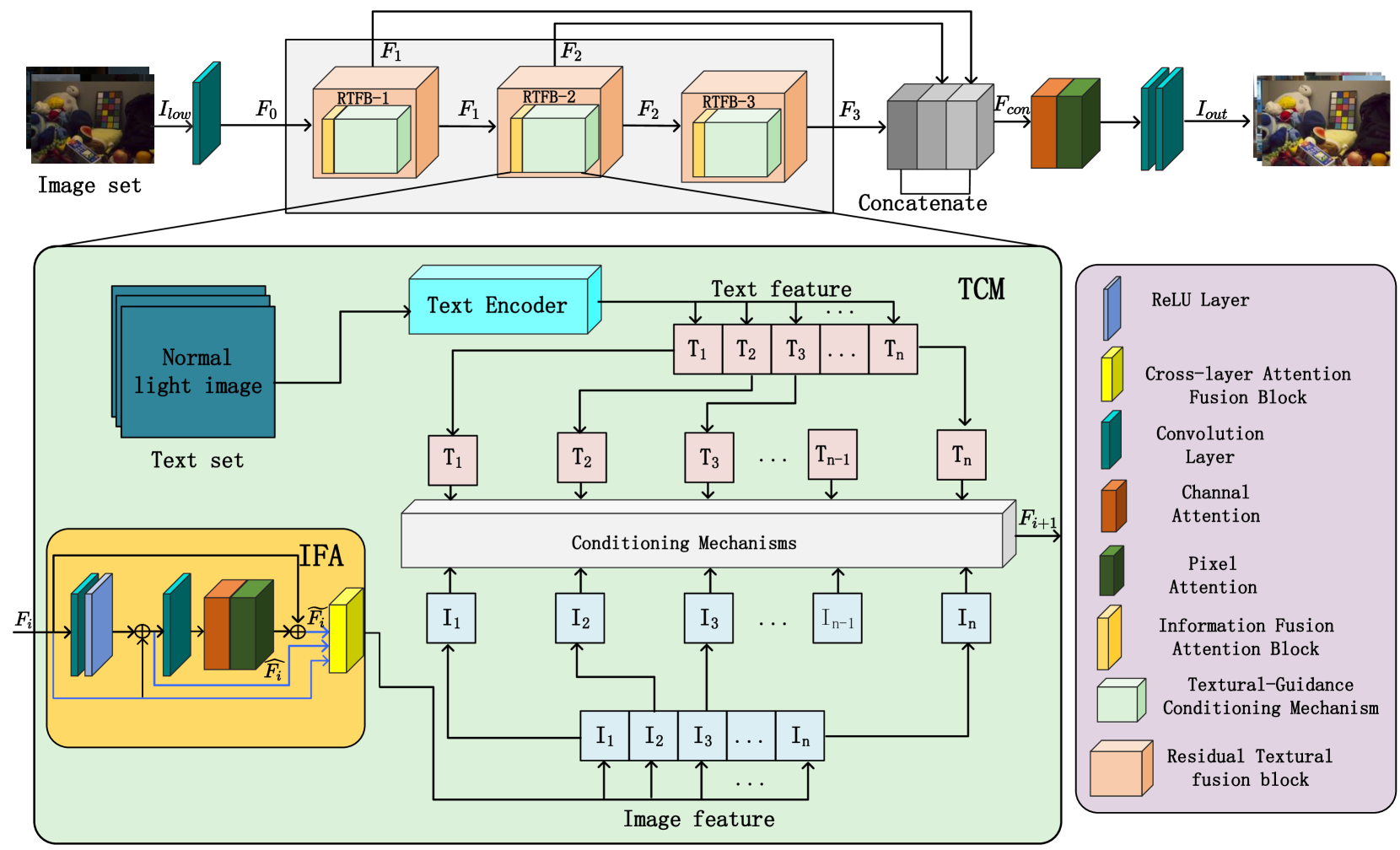
技术框架:NaLSuper网络主要包含以下几个模块:1) 图像编码器:提取低光图像的视觉特征。2) 文本编码器:提取文本描述的语义特征。3) 文本引导调节机制(TCM):将文本特征融入到图像特征中,增强图像特征的表达能力。4) 信息融合注意力(IFA):融合不同层次的图像和文本特征,并利用注意力机制增强重要区域的特征。5) 图像解码器:将融合后的特征解码为增强后的图像。
关键创新:论文的关键创新在于引入了自然语言监督(NLS)策略,将文本信息作为低光图像增强的指导。这种方法突破了传统方法对成对图像数据的依赖,利用了更广泛的监督信息。此外,TCM和IFA模块的设计,有效地实现了图像和文本特征的对齐和融合,提升了模型的性能。
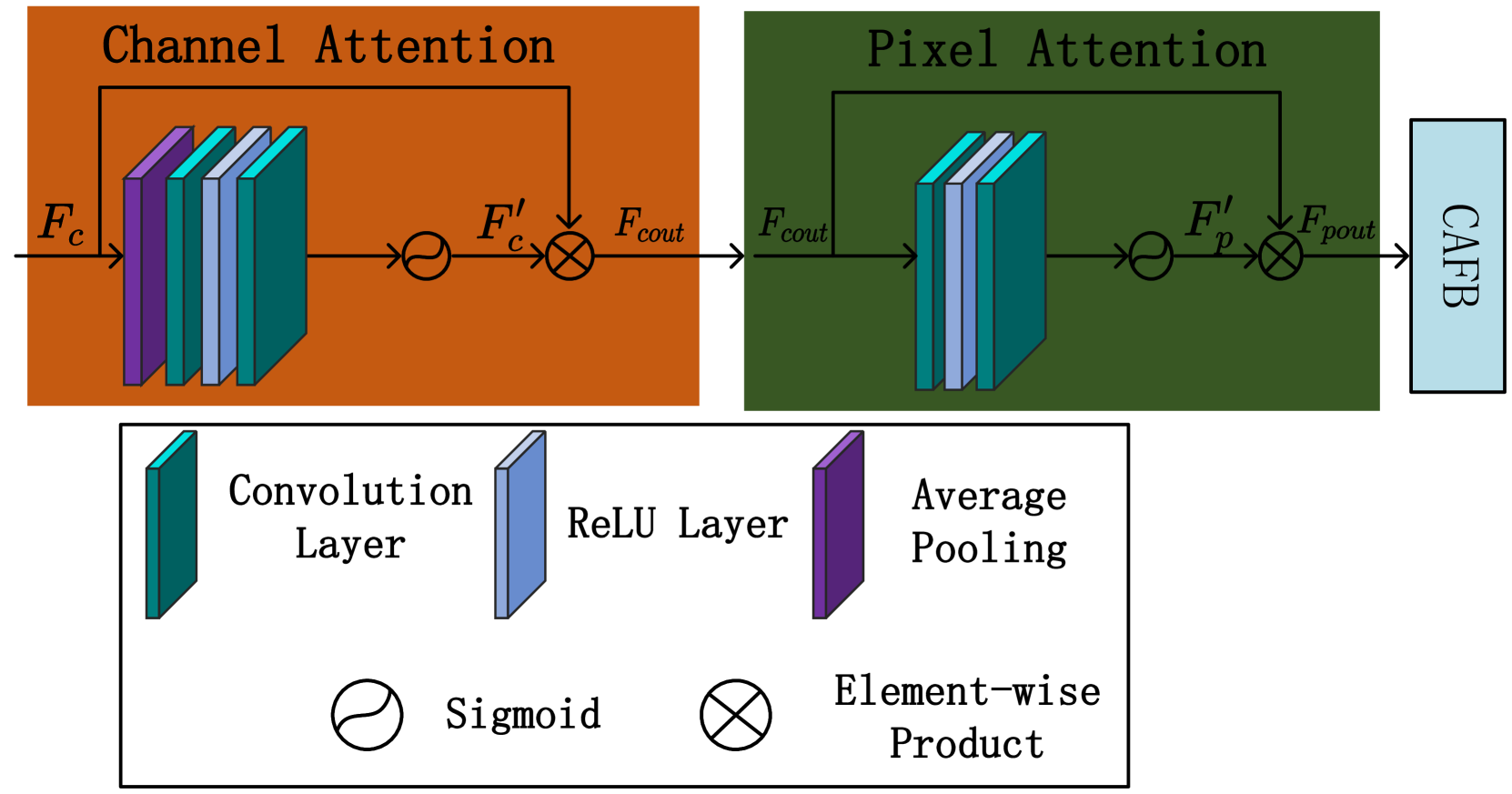
关键设计:TCM模块通过计算图像区域和句子单词之间的相关性,实现细粒度的跨模态特征融合。IFA模块利用多层特征融合和注意力机制,增强了不同区域和不同层次特征的表达能力。损失函数方面,可能采用了像素级别的L1或L2损失,以及感知损失、对抗损失等,以保证增强图像的视觉质量。具体的网络结构和参数设置在论文中应该有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
论文通过大量实验验证了NaLSuper的有效性和鲁棒性。实验结果表明,NaLSuper在多个低光图像增强数据集上取得了优于现有方法的性能。具体的性能提升幅度未知,但摘要中强调了其卓越的有效性。此外,论文还展示了NaLSuper在不同光照条件和不同文本描述下的增强效果,证明了其泛化能力。
🎯 应用场景
该研究成果可应用于安防监控、夜间摄影、医学影像等领域,提升低光照条件下的图像质量,改善视觉体验。通过自然语言的引导,可以实现更灵活、个性化的图像增强,例如,根据描述调整图像的亮度和色彩风格。未来,该方法有望应用于更广泛的图像处理任务,例如图像修复、图像生成等。
📄 摘要(原文)
With the development of deep learning, numerous methods for low-light image enhancement (LLIE) have demonstrated remarkable performance. Mainstream LLIE methods typically learn an end-to-end mapping based on pairs of low-light and normal-light images. However, normal-light images under varying illumination conditions serve as reference images, making it difficult to define a ``perfect'' reference image This leads to the challenge of reconciling metric-oriented and visual-friendly results. Recently, many cross-modal studies have found that side information from other related modalities can guide visual representation learning. Based on this, we introduce a Natural Language Supervision (NLS) strategy, which learns feature maps from text corresponding to images, offering a general and flexible interface for describing an image under different illumination. However, image distributions conditioned on textual descriptions are highly multimodal, which makes training difficult. To address this issue, we design a Textual Guidance Conditioning Mechanism (TCM) that incorporates the connections between image regions and sentence words, enhancing the ability to capture fine-grained cross-modal cues for images and text. This strategy not only utilizes a wider range of supervised sources, but also provides a new paradigm for LLIE based on visual and textual feature alignment. In order to effectively identify and merge features from various levels of image and textual information, we design an Information Fusion Attention (IFA) module to enhance different regions at different levels. We integrate the proposed TCM and IFA into a Natural Language Supervision network for LLIE, named NaLSuper. Finally, extensive experiments demonstrate the robustness and superior effectiveness of our proposed NaLSuper.