Scalable Vision Language Model Training via High Quality Data Curation
作者: Hongyuan Dong, Zijian Kang, Weijie Yin, Xiao Liang, Chao Feng, Jiao Ran
分类: cs.CV, cs.CL
发布日期: 2025-01-10 (更新: 2025-06-09)
备注: ACL 2025 Main Conference
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
SAIL-VL:通过高质量数据构建实现可扩展的视觉语言模型训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 高质量数据 数据构建 可扩展训练 监督微调 多模态学习 视觉理解 大规模预训练
📋 核心要点
- 现有视觉语言模型在数据质量和规模上存在瓶颈,限制了模型性能的进一步提升。
- SAIL-VL通过构建大规模高质量的视觉理解数据集SAIL-Caption,并结合数据数量和复杂性扩展的SFT策略,显著提升模型性能。
- SAIL-VL系列模型在多个VLM基准测试中取得了领先的性能,尤其是在OpenCompass 2024上,2B模型超越了同等规模的模型。
📝 摘要(中文)
本文介绍SAIL-VL(通过高质量数据构建实现可扩展的视觉语言模型训练),这是一个开源的视觉语言模型(VLM)系列,在20亿和80亿参数规模上实现了最先进(SOTA)的性能。以下三个关键改进促成了SAIL-VL的领先性能:(1)可扩展的高质量视觉理解数据构建:我们实现了一个数据构建流程,以支持数亿规模的高质量重新标注数据。与开源数据集相比,生成的数据集SAIL-Caption被验证具有最高的数据质量。(2)利用高质量视觉理解数据进行可扩展的预训练:我们将SAIL-VL的预训练预算扩展到6550亿tokens,并表明即使是20亿参数的VLM也能从扩大规模的训练数据中受益,在基准测试性能中表现出对数数据规模扩展规律。(3)通过数据数量和复杂性扩展实现可扩展的SFT:我们构建了一个高质量的SFT数据集集合,具有领先的数据数量扩展有效性,并证明使用逐渐增加复杂性的数据进行训练,大大超过了基线单阶段训练。在我们的评估中,SAIL-VL系列模型在18个广泛使用的VLM基准测试中实现了最高的平均分,其中20亿参数模型在OpenCompass 2024上超过了同等规模的VLM,展示了强大的视觉理解能力。SAIL-VL系列模型已在HuggingFace上发布。
🔬 方法详解
问题定义:现有视觉语言模型训练受限于数据质量和规模。开源数据集质量参差不齐,大规模高质量数据的获取成本高昂,导致模型性能难以进一步提升。此外,如何有效地利用大规模数据进行训练,特别是如何设计有效的监督微调(SFT)策略,也是一个挑战。
核心思路:SAIL-VL的核心思路是通过高质量的数据构建和可扩展的训练策略来提升视觉语言模型的性能。具体来说,首先构建一个大规模、高质量的视觉理解数据集SAIL-Caption,然后利用该数据集进行预训练,并通过数据数量和复杂性扩展的SFT策略来进一步提升模型性能。这种设计旨在解决数据质量和规模的瓶颈,并充分利用大规模数据进行训练。
技术框架:SAIL-VL的整体框架包括三个主要阶段:(1) 数据构建阶段:构建大规模高质量的视觉理解数据集SAIL-Caption。(2) 预训练阶段:利用SAIL-Caption数据集对视觉语言模型进行预训练。(3) 监督微调(SFT)阶段:通过数据数量和复杂性扩展的SFT策略,进一步提升模型性能。
关键创新:SAIL-VL的关键创新在于以下几个方面:(1) 提出了一个可扩展的高质量视觉理解数据构建流程,能够高效地生成大规模高质量的重新标注数据。(2) 提出了数据数量和复杂性扩展的SFT策略,能够有效地利用大规模数据进行训练,并显著提升模型性能。与现有方法相比,SAIL-VL更加注重数据质量和训练策略的优化。
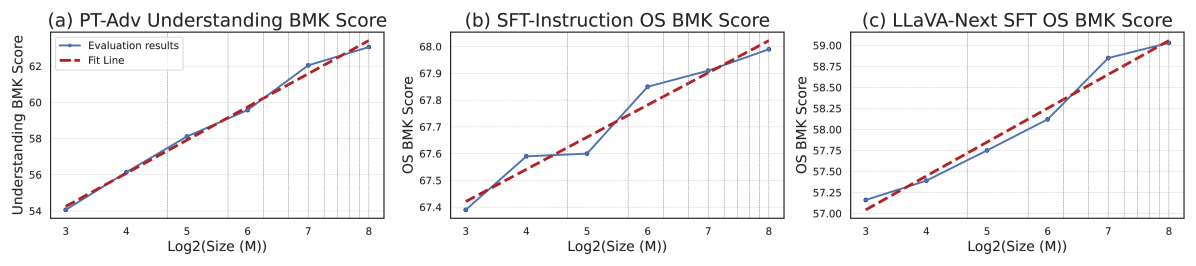
关键设计:在数据构建方面,采用了特定的标注流程和质量控制机制,以确保数据的准确性和一致性。在预训练方面,采用了大规模的训练预算(6550亿tokens),并观察到模型性能与数据规模之间的对数关系。在SFT方面,采用了数据数量和复杂性扩展的策略,即逐步增加训练数据的数量和难度,以提升模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
SAIL-VL系列模型在18个广泛使用的VLM基准测试中实现了最高的平均分。特别地,20亿参数的SAIL-VL模型在OpenCompass 2024上超越了同等规模的VLM,证明了其强大的视觉理解能力。实验结果表明,SAIL-VL在数据质量和训练策略上的优化是有效的,能够显著提升模型性能。
🎯 应用场景
SAIL-VL具有广泛的应用前景,包括图像描述、视觉问答、图像检索、视觉推理等。它可以应用于智能客服、自动驾驶、智能家居、医疗诊断等领域,提升人机交互的智能化水平,并为各行业提供更高效、更智能的解决方案。未来,SAIL-VL有望成为多模态人工智能领域的重要基石。
📄 摘要(原文)
In this paper, we introduce SAIL-VL (ScAlable Vision Language Model TraIning via High QuaLity Data Curation), an open-source vision language model (VLM) series achieving state-of-the-art (SOTA) performance in 2B and 8B parameters. The following three key improvements contribute to SAIL-VL's leading performance: (1) Scalable high-quality visual understanding data construction: We implement a data construction pipeline to enable hundred-million-scale high-quality recaption data annotation. The resulted dataset SAIL-Caption is validated to be of the highest data quality compared with opensource datasets. (2) Scalable Pretraining with High-Quality Visual Understanding Data: We scale SAIL-VL's pretraining budget up to 655B tokens and show that even a 2B VLM benefits from scaled up training data sizes, exhibiting logarithmic data size scaling laws in benchmark performance. (3) Scalable SFT via data quantity and complexity scaling: We curate a high-quality SFT dataset collection with leading data quantity scaling effectiveness and demonstrate that training with progressively higher-complexity data surpasses baseline one-stage training by a large margin. SAIL-VL series models achieve the highest average score in 18 widely used VLM benchmarks in our evaluation, with the 2B model takes the top position over VLMs of comparable sizes on OpenCompass 2024 (https://rank.opencompass.org.cn/leaderboard-multimodal), demonstrating robust visual comprehension abilities. SAIL-VL series models are released at HuggingFace (https://huggingface.co/BytedanceDouyinContent).