Text-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs
作者: Dabing Cheng, Haosen Zhan, Xingchen Zhao, Guisheng Liu, Zemin Li, Jinghui Xie, Zhao Song, Weiguo Feng, Bingyue Peng
分类: cs.CV
发布日期: 2025-01-10
备注: 16pages conference
💡 一句话要点
提出Text-to-Edit框架,利用多模态LLM实现可控的端到端视频广告创作
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频编辑 多模态LLM 文本到视频 端到端学习 视频广告 时空信息 可控生成
📋 核心要点
- 现有视频编辑方法难以理解视频内容并根据用户需求进行定制,自动化程度和控制精度不足。
- 提出Text-to-Edit框架,利用多模态LLM建立文本输入与视频编辑输出之间的映射,实现可控视频编辑。
- 通过密集帧率和慢-快处理增强模型对时空信息的理解,实验表明该方法在广告和公共数据集上均有效。
📝 摘要(中文)
短视频内容的指数级增长激发了对高效、自动化视频编辑解决方案的需求,同时也带来了理解视频并根据用户需求定制编辑的挑战。为了满足这一需求,我们提出了一个创新的端到端基础框架,最终实现了对最终视频内容编辑的精确控制。利用多模态大型语言模型(MLLM)的灵活性和泛化性,我们为高效的视频创建定义了清晰的输入-输出映射。为了增强模型处理和理解视频内容的能力,我们引入了更密集帧率和慢-快处理技术的战略组合,显著增强了时空视频信息的提取和理解。此外,我们引入了一种文本到编辑机制,允许用户通过文本输入实现所需的视频效果,从而提高编辑视频的质量和可控性。通过全面的实验,我们的方法不仅在广告数据集上展示了显著的有效性,而且在公共数据集上也产生了普遍适用的结论。
🔬 方法详解
问题定义:论文旨在解决视频编辑自动化程度低、难以根据用户文本指令精确控制编辑结果的问题。现有方法在理解视频内容和用户意图方面存在不足,导致编辑效果不理想,难以满足广告等场景的定制化需求。
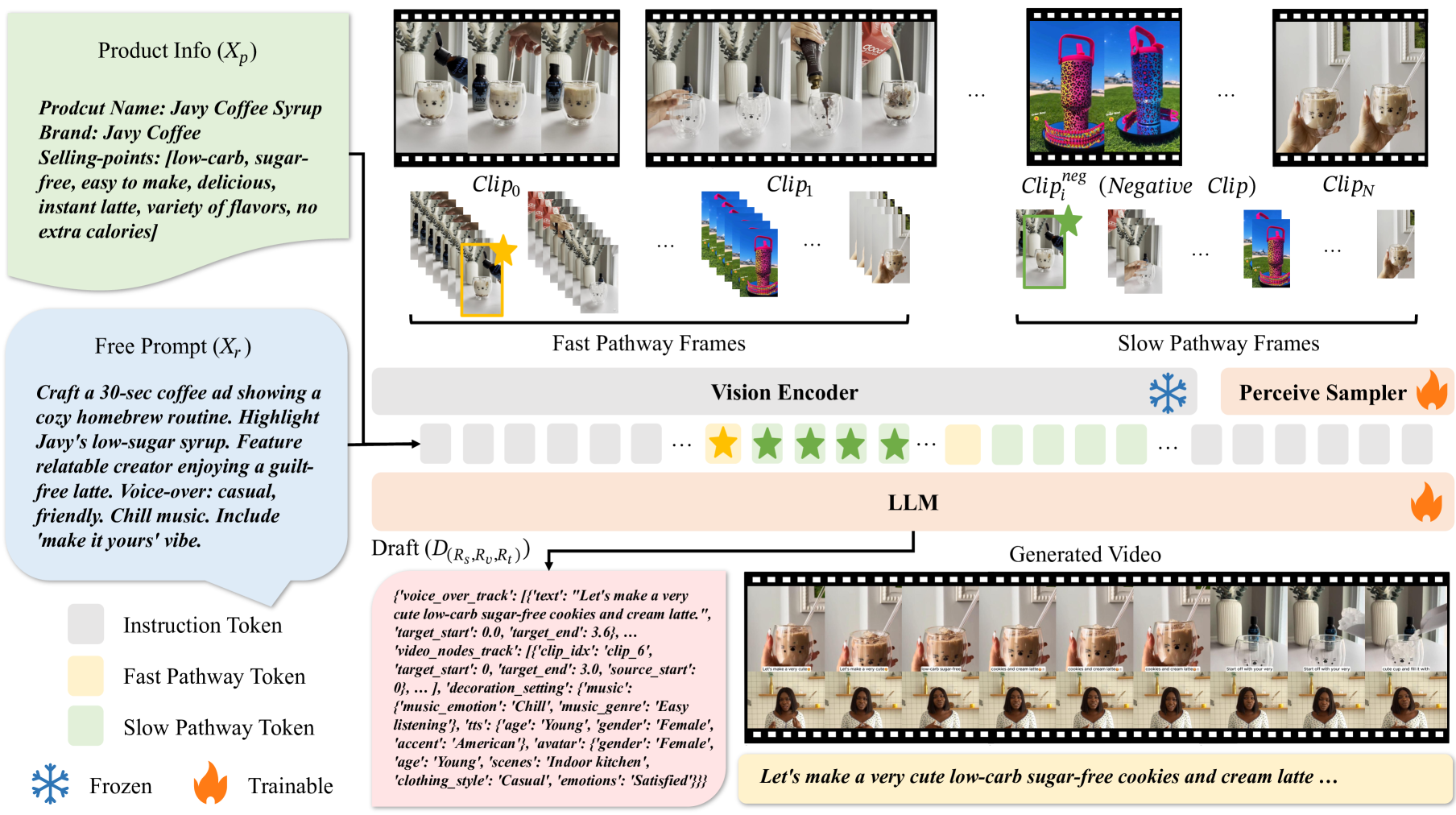
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)的强大能力,将文本指令直接映射到视频编辑操作。通过将视频内容和用户指令转化为MLLM能够理解的输入形式,并利用MLLM的生成能力,实现端到端的视频编辑流程。这种方法旨在提高视频编辑的自动化程度和可控性。
技术框架:该框架主要包含以下几个模块:1) 视频编码器:用于提取视频的时空特征,采用密集帧率和慢-快处理技术,增强对视频内容的理解。2) 文本编码器:用于提取用户文本指令的语义特征。3) 多模态LLM:作为核心模块,接收视频和文本特征,并生成视频编辑指令。4) 视频解码器:根据MLLM生成的编辑指令,对原始视频进行编辑,生成最终的视频内容。
关键创新:该论文的关键创新在于提出了一个端到端的文本到视频编辑框架,直接利用MLLM实现可控的视频编辑。与传统方法相比,该方法无需人工干预,能够根据用户文本指令自动生成编辑后的视频,大大提高了编辑效率和可控性。此外,密集帧率和慢-快处理技术的引入,增强了模型对视频时空信息的理解。
关键设计:论文采用了密集帧率策略,即提取更高帧率的视频帧,以捕捉更细粒度的动作信息。同时,采用了慢-快处理技术,即分别使用较慢和较快的速度处理视频帧,以提取不同时间尺度的特征。这些技术细节旨在增强模型对视频内容的理解。损失函数方面,论文可能采用了生成对抗网络(GAN)或变分自编码器(VAE)等方法,以提高生成视频的质量。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明了Text-to-Edit框架在视频广告数据集上的有效性,并验证了其在公共数据集上的泛化能力。具体性能数据未知,但摘要强调了该方法在提高视频编辑质量和可控性方面的显著效果。与现有方法相比,该方法能够更好地理解用户意图,生成更符合需求的编辑结果。
🎯 应用场景
该研究成果可广泛应用于短视频广告制作、内容创作、社交媒体视频编辑等领域。通过文本指令控制视频编辑,可以大幅降低视频制作门槛,提高生产效率,并实现个性化定制。未来,该技术有望应用于智能监控、自动驾驶等领域,实现基于视觉信息的智能决策。
📄 摘要(原文)
The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.