VideoRAG: Retrieval-Augmented Generation over Video Corpus
作者: Soyeong Jeong, Kangsan Kim, Jinheon Baek, Sung Ju Hwang
分类: cs.CV, cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2025-01-10 (更新: 2025-05-28)
备注: ACL Findings 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出VideoRAG,通过检索增强生成提升视频语料上的问答准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频检索 检索增强生成 视频语言模型 多模态学习 视频理解
📋 核心要点
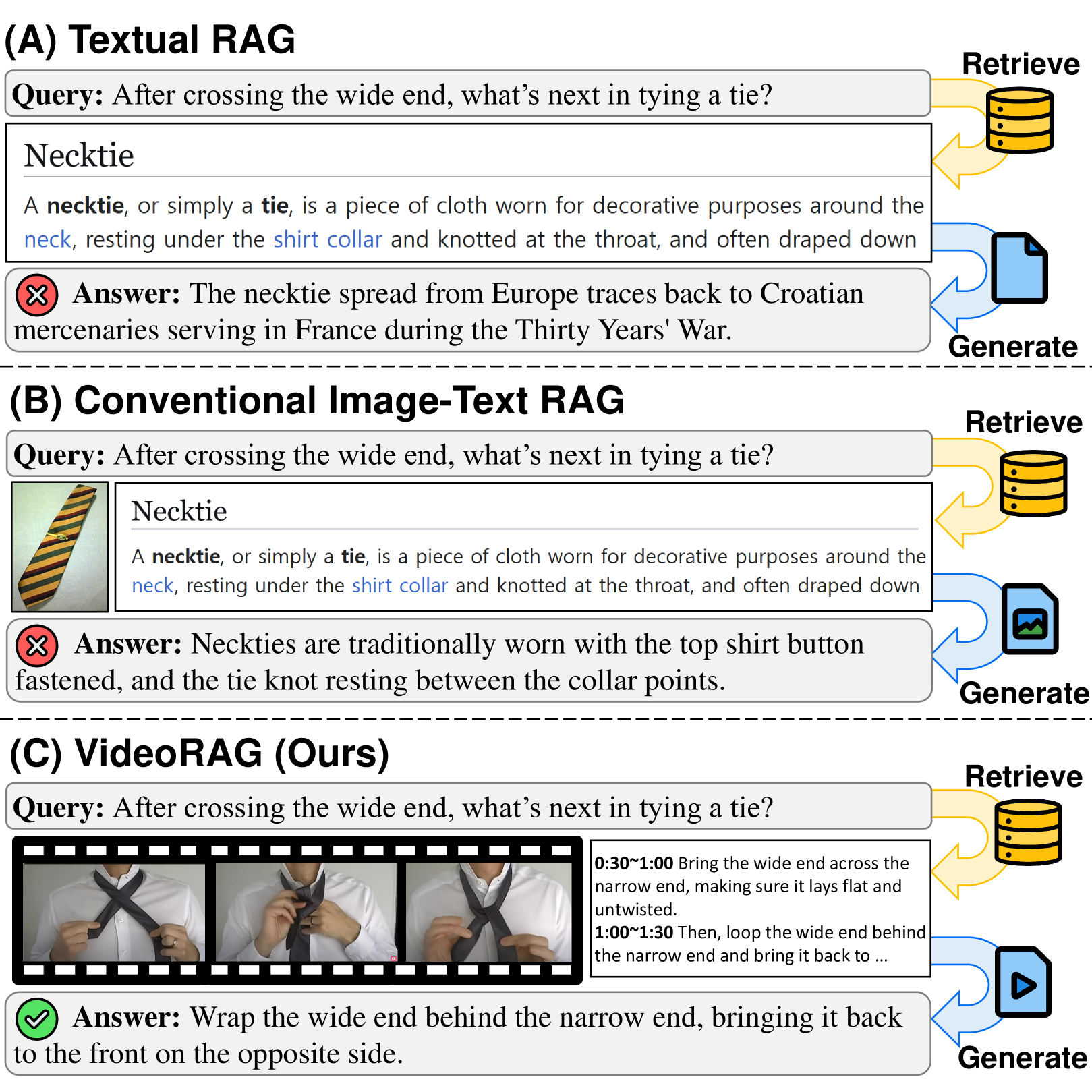
- 现有RAG方法忽略了视频这一富含上下文信息的多模态数据源,限制了问答系统的准确性。
- VideoRAG通过动态检索相关视频,并结合视觉和文本信息,增强生成模型的知识。
- 实验结果表明,VideoRAG优于现有基线方法,验证了其在视频问答任务中的有效性。
📝 摘要(中文)
检索增强生成(RAG)是一种强大的策略,通过检索与查询相关的外部知识并将其整合到生成过程中,从而提高模型的factual accuracy。然而,现有的方法主要集中在文本上,最近的一些进展考虑了图像,但它们在很大程度上忽略了视频,视频是一种比任何其他模态都能更有效地表示上下文细节的丰富的多模态知识来源。虽然最近的研究探索了在响应生成中使用视频,但它们要么预定义与查询相关的视频而不进行检索,要么将视频转换为文本描述,从而丢失了多模态的丰富性。为了解决这些问题,我们引入了VideoRAG,一个不仅动态检索与查询相关的视频,而且利用视觉和文本信息的框架。VideoRAG的运行由最近的大型视频语言模型(LVLMs)提供支持,这使得可以直接处理视频内容以表示检索,并将检索到的视频与查询无缝集成以进行响应生成。此外,受到LVLM的上下文大小可能不足以处理极长视频中的所有帧,并且并非所有帧都同等重要的启发,我们引入了一种视频帧选择机制来提取信息量最大的帧子集,以及一种从视频中提取文本信息的策略(因为它可以帮助理解视频内容),当它们的字幕不可用时。我们通过实验验证了VideoRAG的有效性,表明它优于相关的基线。
🔬 方法详解
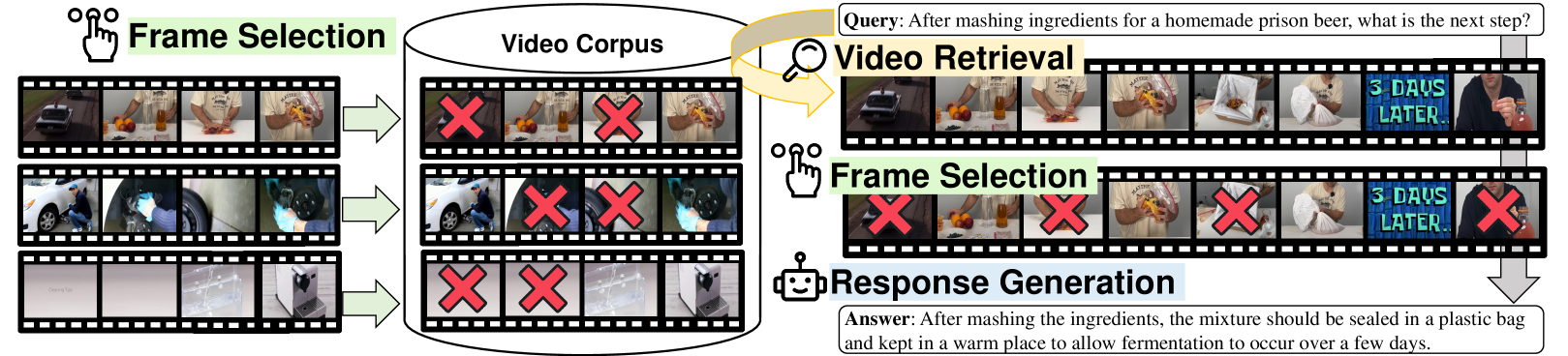
问题定义:论文旨在解决现有检索增强生成方法在视频语料库上的应用不足问题。现有方法要么忽略视频模态,要么将视频转换为文本,损失了视频中丰富的视觉信息。此外,长视频包含大量冗余帧,直接处理会超出大型视频语言模型的上下文长度限制,影响效率和准确性。
核心思路:论文的核心思路是构建一个能够动态检索相关视频片段,并有效利用视频中的视觉和文本信息进行问答的RAG框架。通过结合视频检索和帧选择机制,提取关键信息,并利用大型视频语言模型进行信息融合和答案生成。
技术框架:VideoRAG框架包含以下几个主要模块:1) 视频检索模块:根据查询语句,从视频语料库中检索相关视频。2) 视频帧选择模块:从检索到的视频中选择最具代表性的帧子集。3) 文本信息提取模块:提取视频中的文本信息,例如字幕或OCR识别结果。4) 大型视频语言模型:将查询语句、检索到的视频帧和文本信息输入到LVLM中,生成答案。
关键创新:VideoRAG的关键创新在于:1) 提出了一个完整的视频RAG框架,能够动态检索和利用视频信息。2) 引入了视频帧选择机制,有效降低了计算复杂度,并提高了信息利用率。3) 结合了视觉和文本信息,充分利用了视频的多模态特性。
关键设计:视频检索模块可以使用现有的文本检索方法,例如基于向量相似度的检索。视频帧选择模块可以使用基于关键帧提取的算法,例如聚类或重要性评分。文本信息提取模块可以使用现有的OCR技术或字幕提取工具。大型视频语言模型可以使用预训练的LVLM,例如VideoBERT或CLIP。具体的参数设置和损失函数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了VideoRAG的有效性,结果表明,VideoRAG在视频问答任务上优于现有的基线方法。具体的性能提升数据在论文中给出,证明了VideoRAG在利用视频信息进行问答方面的优势。
🎯 应用场景
VideoRAG可应用于多种场景,例如视频内容理解、智能客服、教育视频检索、新闻视频摘要等。通过提供更准确和全面的答案,可以提升用户体验,并为视频内容的智能化应用提供支持。未来,该技术有望在视频监控、自动驾驶等领域发挥重要作用。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) is a powerful strategy for improving the factual accuracy of models by retrieving external knowledge relevant to queries and incorporating it into the generation process. However, existing approaches primarily focus on text, with some recent advancements considering images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing contextual details more effectively than any other modality. While very recent studies explore the use of videos in response generation, they either predefine query-associated videos without retrieval or convert videos into textual descriptions losing multimodal richness. To tackle these, we introduce VideoRAG, a framework that not only dynamically retrieves videos based on their relevance with queries but also utilizes both visual and textual information. The operation of VideoRAG is powered by recent Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and the seamless integration of retrieved videos jointly with queries for response generation. Also, inspired by that the context size of LVLMs may not be sufficient to process all frames in extremely long videos and not all frames are equally important, we introduce a video frame selection mechanism to extract the most informative subset of frames, along with a strategy to extract textual information from videos (as it can aid the understanding of video content) when their subtitles are not available. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines. Code is available at https://github.com/starsuzi/VideoRAG.