UV-Attack: Physical-World Adversarial Attacks for Person Detection via Dynamic-NeRF-based UV Mapping
作者: Yanjie Li, Kaisheng Liang, Bin Xiao
分类: cs.CV, cs.AI
发布日期: 2025-01-10 (更新: 2025-10-30)
备注: 23 pages, 22 figures, accepted by ICLR2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出UV-Attack,利用动态NeRF的UV映射实现对行人检测器的高成功率物理对抗攻击。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 对抗攻击 行人检测 动态NeRF UV映射 物理世界攻击
📋 核心要点
- 现有基于补丁或静态3D模型纹理修改的行人检测对抗攻击,因人体运动的灵活性而成功率较低,对人体动作引起的3D变形建模是主要挑战。
- UV-Attack利用动态NeRF的UV映射,生成各种动作和视角的行人图像,通过修改UV贴图而非RGB图像,实现实时纹理编辑,提高攻击的实用性。
- 提出的姿态变换期望损失(EoPT)提高了在未见过的姿势和视角下的规避成功率。实验表明,UV-Attack显著优于现有方法。
📝 摘要(中文)
本文提出了一种名为UV-Attack的突破性方法,该方法利用基于动态神经辐射场(NeRF)的UV映射,即使在广泛且未见过的行人动作下也能实现高攻击成功率。该方法通过动态NeRF生成跨多种动作和视角的行人图像,甚至通过从SMPL参数空间采样来创建新的动作。UV-Attack生成UV贴图而非RGB图像,并修改纹理堆栈,从而实现实时纹理编辑,使攻击更具实用性。此外,还提出了一种新颖的姿态变换期望损失(EoPT),以提高在未见过的姿势和视角下的规避成功率。实验表明,UV-Attack在动态视频设置中针对FastRCNN模型实现了92.7%的攻击成功率,显著优于最先进的AdvCamou攻击(仅有28.5%的ASR)。在黑盒设置下,针对最新的YOLOv8检测器也实现了49.5%的ASR。这项工作突出了基于动态NeRF的UV映射在创建更有效的行人检测器对抗攻击方面的潜力,解决了建模人体运动和纹理修改的关键挑战。
🔬 方法详解
问题定义:论文旨在解决物理世界中行人检测器的对抗攻击问题。现有方法,如基于补丁或静态3D模型纹理修改的方法,难以有效应对人体运动带来的复杂形变,导致攻击成功率低。对动态人体建模和纹理修改是主要痛点。
核心思路:论文的核心思路是利用动态NeRF来建模人体运动,并使用UV映射来修改服装纹理。通过动态NeRF,可以生成各种姿势和视角的逼真人体图像。使用UV映射而非直接修改RGB图像,可以更方便地进行纹理编辑,并提高攻击的鲁棒性。
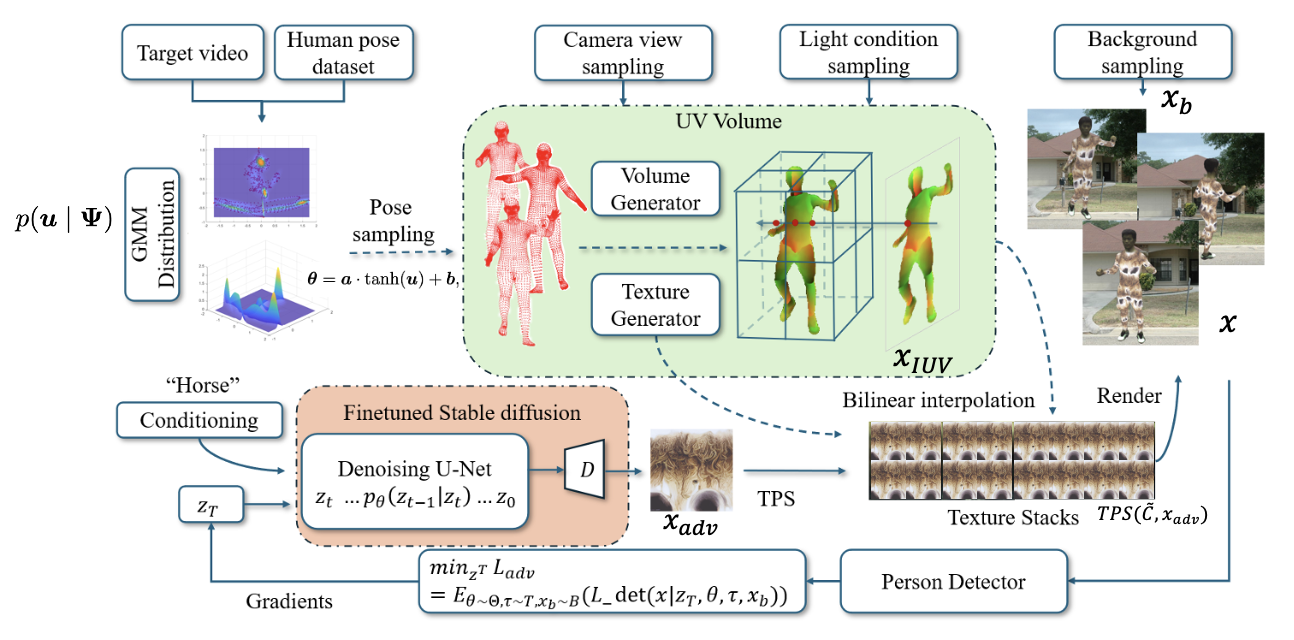
技术框架:UV-Attack的整体框架包括以下几个主要模块:1) 基于动态NeRF的人体建模,用于生成不同姿势和视角的行人图像;2) UV贴图生成模块,将3D人体模型映射到2D UV空间;3) 纹理修改模块,在UV空间中对服装纹理进行对抗性扰动;4) 渲染模块,将修改后的纹理映射回3D人体模型,并渲染成2D图像;5) 对抗攻击模块,利用生成的对抗样本攻击行人检测器。
关键创新:论文的关键创新在于:1) 将动态NeRF引入到物理对抗攻击中,解决了人体运动建模的难题;2) 提出了一种基于UV映射的纹理修改方法,实现了实时纹理编辑,提高了攻击的实用性;3) 提出了姿态变换期望损失(EoPT),提高了攻击在未见过的姿势和视角下的泛化能力。与现有方法相比,UV-Attack能够更有效地生成对抗样本,并提高攻击成功率。
关键设计:EoPT损失函数的设计是关键。它通过对SMPL参数空间进行采样,生成不同的姿势和视角,并计算对抗样本在这些姿势和视角下的期望损失。这样可以提高攻击在未见过的姿势和视角下的鲁棒性。此外,UV贴图的分辨率和纹理修改的强度也是重要的参数。论文中对这些参数进行了仔细的调整,以获得最佳的攻击效果。
🖼️ 关键图片

📊 实验亮点
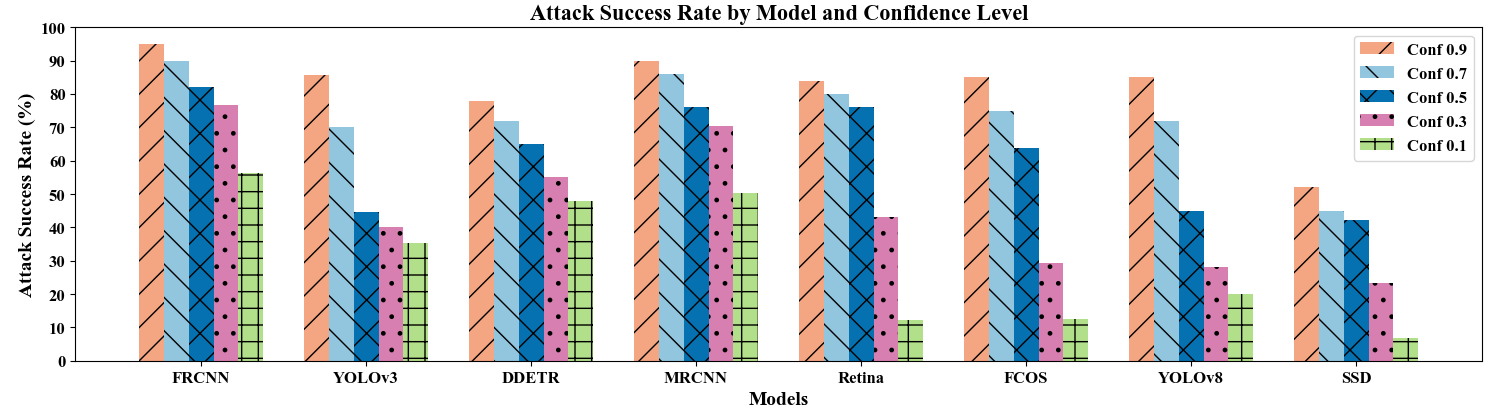
UV-Attack在动态视频设置中针对FastRCNN模型实现了92.7%的攻击成功率,显著优于最先进的AdvCamou攻击(仅有28.5%的ASR)。在黑盒设置下,针对最新的YOLOv8检测器也实现了49.5%的ASR。这些结果表明,UV-Attack在对抗攻击方面具有显著的优势。
🎯 应用场景
该研究成果可应用于评估和提高行人检测系统的安全性,尤其是在自动驾驶、智能监控等领域。通过模拟真实的物理对抗攻击,可以发现行人检测系统中的潜在漏洞,并开发更鲁棒的防御机制。此外,该技术也可用于生成逼真的虚拟人物,应用于游戏、电影等领域。
📄 摘要(原文)
In recent research, adversarial attacks on person detectors using patches or static 3D model-based texture modifications have struggled with low success rates due to the flexible nature of human movement. Modeling the 3D deformations caused by various actions has been a major challenge. Fortunately, advancements in Neural Radiance Fields (NeRF) for dynamic human modeling offer new possibilities. In this paper, we introduce UV-Attack, a groundbreaking approach that achieves high success rates even with extensive and unseen human actions. We address the challenge above by leveraging dynamic-NeRF-based UV mapping. UV-Attack can generate human images across diverse actions and viewpoints, and even create novel actions by sampling from the SMPL parameter space. While dynamic NeRF models are capable of modeling human bodies, modifying clothing textures is challenging because they are embedded in neural network parameters. To tackle this, UV-Attack generates UV maps instead of RGB images and modifies the texture stacks. This approach enables real-time texture edits and makes the attack more practical. We also propose a novel Expectation over Pose Transformation loss (EoPT) to improve the evasion success rate on unseen poses and views. Our experiments show that UV-Attack achieves a 92.7% attack success rate against the FastRCNN model across varied poses in dynamic video settings, significantly outperforming the state-of-the-art AdvCamou attack, which only had a 28.5% ASR. Moreover, we achieve 49.5% ASR on the latest YOLOv8 detector in black-box settings. This work highlights the potential of dynamic NeRF-based UV mapping for creating more effective adversarial attacks on person detectors, addressing key challenges in modeling human movement and texture modification. The code is available at https://github.com/PolyLiYJ/UV-Attack.