Overcoming Language Priors for Visual Question Answering Based on Knowledge Distillation
作者: Daowan Peng, Wei Wei
分类: cs.CV, cs.CL
发布日期: 2025-01-10
备注: Accepted to ICME2024
💡 一句话要点
提出KDAR方法,利用知识蒸馏克服视觉问答中的语言先验依赖问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 知识蒸馏 语言先验 多模态学习 泛化能力 样本重加权 VQA-CPv2
📋 核心要点
- VQA模型易受语言先验影响,导致依赖语言捷径而非真正理解多模态信息,泛化能力受限。
- 提出KDAR方法,通过知识蒸馏利用教师模型的软标签进行正则化,抑制对常见答案的过拟合。
- 实验表明,KDAR在OOD和IID设置下均提升了VQA性能,并在VQA-CPv2上取得了SOTA结果。
📝 摘要(中文)
先前的研究表明,视觉问答(VQA)模型容易依赖语言先验进行答案预测。在这种情况下,预测通常依赖于语言捷径,而不是对多模态知识的全面掌握,这降低了它们的泛化能力。在本文中,我们提出了一种新方法,即KDAR,利用知识蒸馏来解决VQA任务中的先验依赖困境。具体来说,利用来自训练有素的教师模型的软标签所带来的正则化效果来惩罚对最常见答案的过度拟合。软标签起到正则化作用,也提供了语义指导,缩小了候选答案的范围。此外,我们设计了一种自适应的样本级重加权学习策略,通过动态调整每个样本的重要性来进一步减轻偏差。实验结果表明,我们的方法增强了在OOD和IID设置下的性能。我们的方法在VQA-CPv2分布外(OOD)基准测试中实现了最先进的性能,显著优于以前的最先进方法。
🔬 方法详解
问题定义:VQA模型在预测答案时,容易过度依赖问题中的语言模式(language priors),而忽略图像信息。这导致模型在训练数据分布之外(OOD)的数据集上表现不佳,泛化能力差。现有方法难以有效抑制这种语言先验依赖。
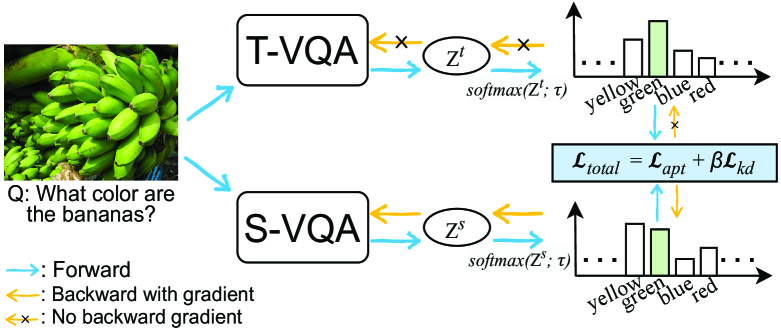
核心思路:利用知识蒸馏,将一个训练充分的教师模型(teacher model)的知识迁移到学生模型(student model)。教师模型通过软标签(soft labels)提供更丰富的语义信息,引导学生模型学习更鲁棒的特征表示,减少对语言先验的依赖。同时,通过自适应的样本重加权策略,动态调整不同样本的重要性,进一步缓解偏差。
技术框架:KDAR方法包含一个教师模型和一个学生模型。教师模型首先在一个大型数据集上进行训练,学习到丰富的知识。然后,教师模型对训练数据进行预测,生成软标签。学生模型在训练时,不仅要拟合真实标签,还要拟合教师模型提供的软标签。此外,KDAR还引入了一个自适应的样本重加权模块,根据样本的难易程度和重要性,动态调整每个样本的权重。
关键创新:KDAR的关键创新在于将知识蒸馏与自适应样本重加权相结合,用于解决VQA中的语言先验依赖问题。与传统的知识蒸馏方法不同,KDAR更加关注如何利用软标签来抑制对常见答案的过度拟合,并设计了自适应的样本重加权策略来进一步减轻偏差。这种方法能够更有效地引导学生模型学习到与图像内容相关的知识,提高模型的泛化能力。
关键设计:KDAR使用交叉熵损失函数来衡量学生模型的预测结果与真实标签之间的差异。同时,使用KL散度损失函数来衡量学生模型的预测结果与教师模型的软标签之间的差异。自适应样本重加权模块根据样本的预测难度和重要性,动态调整每个样本的权重。具体来说,对于预测难度较大的样本,给予更高的权重;对于容易受到语言先验影响的样本,给予更低的权重。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
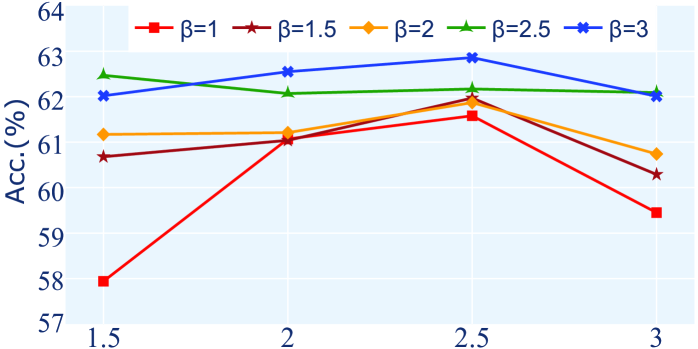
KDAR方法在VQA-CPv2数据集上取得了显著的性能提升,超越了之前的SOTA方法。实验结果表明,KDAR能够有效抑制语言先验依赖,提高模型的泛化能力。具体的数据提升幅度在论文中有详细展示,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要视觉理解和推理的场景,例如智能客服、图像搜索、自动驾驶等。通过提高VQA模型的泛化能力,可以使其在更复杂和多变的环境中更好地理解图像内容,并做出准确的回答。此外,该方法也可以推广到其他多模态学习任务中,例如图像描述生成、视频问答等,具有广泛的应用前景。
📄 摘要(原文)
Previous studies have pointed out that visual question answering (VQA) models are prone to relying on language priors for answer predictions. In this context, predictions often depend on linguistic shortcuts rather than a comprehensive grasp of multimodal knowledge, which diminishes their generalization ability. In this paper, we propose a novel method, namely, KDAR, leveraging knowledge distillation to address the prior-dependency dilemmas within the VQA task. Specifically, the regularization effect facilitated by soft labels from a well-trained teacher is employed to penalize overfitting to the most common answers. The soft labels, which serve a regularization role, also provide semantic guidance that narrows the range of candidate answers. Additionally, we design an adaptive sample-wise reweighting learning strategy to further mitigate bias by dynamically adjusting the importance of each sample. Experimental results demonstrate that our method enhances performance in both OOD and IID settings. Our method achieves state-of-the-art performance on the VQA-CPv2 out-of-distribution (OOD) benchmark, significantly outperforming previous state-of-the-art approaches.