Deep Reversible Consistency Learning for Cross-modal Retrieval
作者: Ruitao Pu, Yang Qin, Dezhong Peng, Xiaomin Song, Huiming Zheng
分类: cs.CV, cs.MM
发布日期: 2025-01-10
💡 一句话要点
提出深度可逆一致性学习(DRCL)用于提升跨模态检索的性能与灵活性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态检索 深度学习 语义一致性 表示学习 先验学习
📋 核心要点
- 现有跨模态检索方法依赖配对数据联合训练,限制了灵活性,且独立训练方法使用随机初始化的先验,忽略了类间关系。
- DRCL通过选择性先验学习(SPL)避免低质量先验,并利用可逆语义一致性学习(RSC)从标签重铸模态不变表示,指导表示学习。
- 在五个数据集上的实验表明,DRCL显著优于15个最先进的基线方法,验证了其有效性和优越性。
📝 摘要(中文)
跨模态检索(CMR)通常学习共同表示以直接度量多模态样本之间的相似性。现有方法大多采用配对的多模态样本,并进行联合训练以学习共同表示,限制了CMR的灵活性。虽然一些方法采用针对每个模态的独立训练策略来提高灵活性,但它们使用随机初始化的正交矩阵来指导表示学习,这是次优的,因为它们假设类间样本彼此独立,限制了样本表示和真实标签之间语义对齐的潜力。为了解决这些问题,我们提出了一种新的方法,称为深度可逆一致性学习(DRCL)用于跨模态检索。DRCL包括两个核心模块,即选择性先验学习(SPL)和可逆语义一致性学习(RSC)。更具体地说,SPL首先学习每个模态上的变换权重矩阵,并根据质量分数选择最佳的作为先验,从而大大避免了盲目选择从低质量模态学习的先验。然后,RSC采用模态不变表示重铸机制(MRR),通过先验的广义逆矩阵从样本语义标签中重铸潜在的模态不变表示。由于标签缺乏模态特定信息,我们利用重铸的特征来指导表示学习,从而最大限度地保持语义一致性。此外,RSC中引入了一种特征增强机制(FA),以鼓励模型学习更广泛的数据分布以实现多样性。最后,在五个广泛使用的数据集上进行的大量实验以及与15个最先进基线的比较证明了我们DRCL的有效性和优越性。
🔬 方法详解
问题定义:跨模态检索旨在学习不同模态数据之间的关联,以便能够根据一个模态的数据检索到另一个模态的相似数据。现有方法的痛点在于,要么依赖于配对的多模态数据进行联合训练,灵活性差;要么虽然采用独立训练,但使用随机初始化的矩阵作为先验,忽略了样本之间的语义关系,导致学习到的表示并非最优。
核心思路:DRCL的核心思路是利用样本的语义标签作为桥梁,学习模态不变的表示。通过选择性先验学习,避免使用低质量模态的先验信息。然后,利用可逆语义一致性学习,将标签信息“重铸”为模态不变的特征,并用这些特征来指导各个模态的表示学习,从而保证语义一致性。
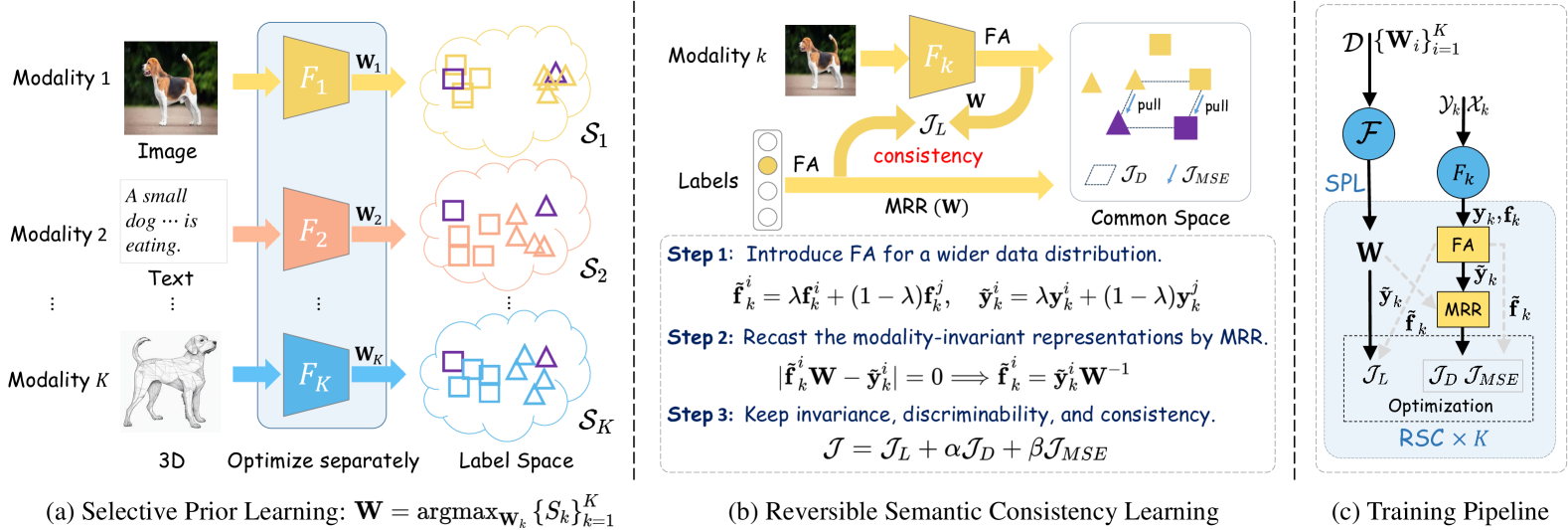
技术框架:DRCL主要包含两个核心模块:选择性先验学习(SPL)和可逆语义一致性学习(RSC)。SPL模块首先为每个模态学习一个变换权重矩阵,并根据质量分数选择最佳的作为先验。RSC模块则包含模态不变表示重铸机制(MRR)和特征增强机制(FA)。MRR利用SPL学习到的先验的广义逆矩阵,将样本的语义标签重铸为模态不变的特征。FA则通过数据增强,鼓励模型学习更广泛的数据分布。
关键创新:DRCL的关键创新在于:1) 提出了选择性先验学习,避免了盲目使用低质量模态的先验信息;2) 提出了模态不变表示重铸机制,利用标签信息指导表示学习,保证了语义一致性。与现有方法的本质区别在于,DRCL不依赖于配对数据,也不使用随机初始化的先验,而是通过标签信息建立跨模态的联系。
关键设计:SPL模块中,质量分数的计算方式未知。RSC模块中,MRR使用先验的广义逆矩阵进行重铸,具体实现方式未知。FA模块中,数据增强的具体策略未知。损失函数的设计也未知,但可以推测包含语义一致性损失和表示学习损失。
🖼️ 关键图片
📊 实验亮点
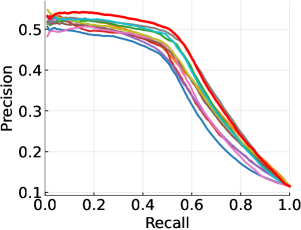
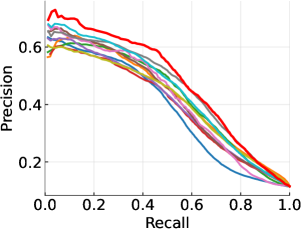
DRCL在五个广泛使用的数据集上进行了评估,并与15个最先进的基线方法进行了比较。实验结果表明,DRCL在所有数据集上都取得了显著的性能提升,证明了其有效性和优越性。具体的性能数据和提升幅度在论文中给出,但摘要中未提及。
🎯 应用场景
DRCL具有广泛的应用前景,例如图像-文本检索、视频-文本检索、音频-文本检索等。该方法可以应用于搜索引擎、推荐系统、智能客服等领域,提高检索的准确性和效率。此外,该方法还可以用于跨模态数据分析和理解,例如医学影像分析、遥感图像分析等。
📄 摘要(原文)
Cross-modal retrieval (CMR) typically involves learning common representations to directly measure similarities between multimodal samples. Most existing CMR methods commonly assume multimodal samples in pairs and employ joint training to learn common representations, limiting the flexibility of CMR. Although some methods adopt independent training strategies for each modality to improve flexibility in CMR, they utilize the randomly initialized orthogonal matrices to guide representation learning, which is suboptimal since they assume inter-class samples are independent of each other, limiting the potential of semantic alignments between sample representations and ground-truth labels. To address these issues, we propose a novel method termed Deep Reversible Consistency Learning (DRCL) for cross-modal retrieval. DRCL includes two core modules, \ie Selective Prior Learning (SPL) and Reversible Semantic Consistency learning (RSC). More specifically, SPL first learns a transformation weight matrix on each modality and selects the best one based on the quality score as the Prior, which greatly avoids blind selection of priors learned from low-quality modalities. Then, RSC employs a Modality-invariant Representation Recasting mechanism (MRR) to recast the potential modality-invariant representations from sample semantic labels by the generalized inverse matrix of the prior. Since labels are devoid of modal-specific information, we utilize the recast features to guide the representation learning, thus maintaining semantic consistency to the fullest extent possible. In addition, a feature augmentation mechanism (FA) is introduced in RSC to encourage the model to learn over a wider data distribution for diversity. Finally, extensive experiments conducted on five widely used datasets and comparisons with 15 state-of-the-art baselines demonstrate the effectiveness and superiority of our DRCL.