OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
作者: Yifei Li, Junbo Niu, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang
分类: cs.CV, cs.AI
发布日期: 2025-01-09 (更新: 2025-03-27)
备注: CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
OVO-Bench:提出在线视频理解基准,评估视频LLM的时间感知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线视频理解 时间感知 视频语言模型 基准测试 视频推理
📋 核心要点
- 现有视频LLM基准缺乏对时间感知的充分评估,无法准确衡量模型在在线视频理解中的能力。
- OVO-Bench通过引入时间戳信息,评估模型在不同时间点对视频内容的理解和推理能力。
- 实验表明,现有Video-LLMs在OVO-Bench上表现不佳,与人类水平差距明显,凸显了在线视频理解的挑战。
📝 摘要(中文)
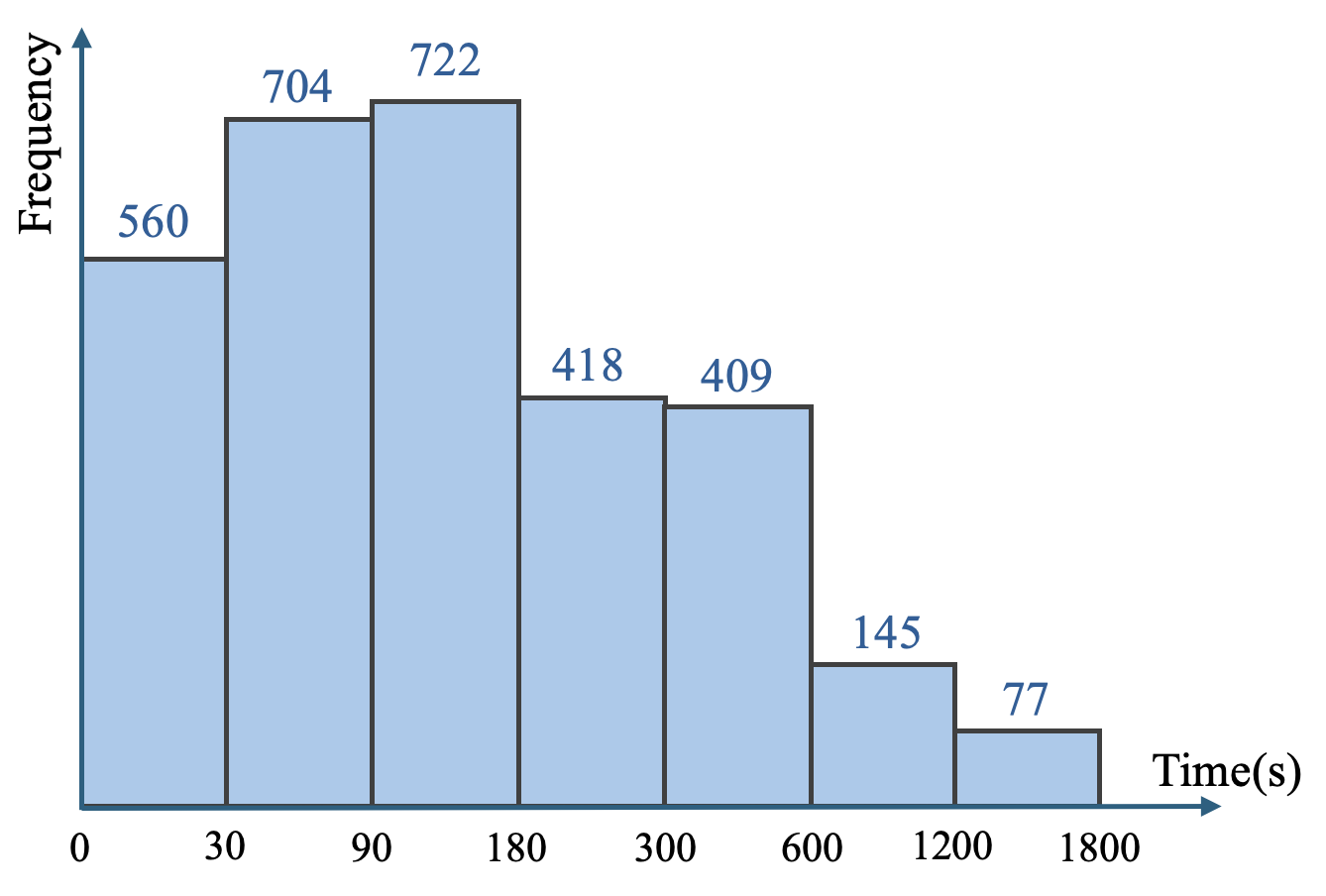
本文提出了OVO-Bench,一个新的视频基准,旨在评估视频语言模型(Video-LLMs)在在线视频理解中的时间感知能力。与离线模型不同,在线模型需要根据问题提出的时间戳动态地推理和响应。OVO-Bench包含12个任务,644个视频和约2800个人工标注的细粒度元数据,并带有精确的时间戳。该基准评估模型在三种场景下的能力:回溯过去事件、实时理解当前事件和前瞻性地延迟响应直到获得足够未来信息。通过对九个Video-LLMs的评估表明,现有模型在在线视频理解方面表现不佳,与人类智能体存在显著差距。OVO-Bench旨在推动视频LLMs的发展,并激发未来对在线视频推理的研究。
🔬 方法详解
问题定义:现有视频语言模型(Video-LLMs)主要针对离线视频理解,即在完整视频输入的基础上进行静态分析。然而,现实世界的视频应用场景通常是线性的、实时的,模型需要根据时间戳动态地理解视频内容并做出响应。现有基准测试未能充分评估模型的时间感知能力,无法准确反映模型在在线视频理解任务中的性能。
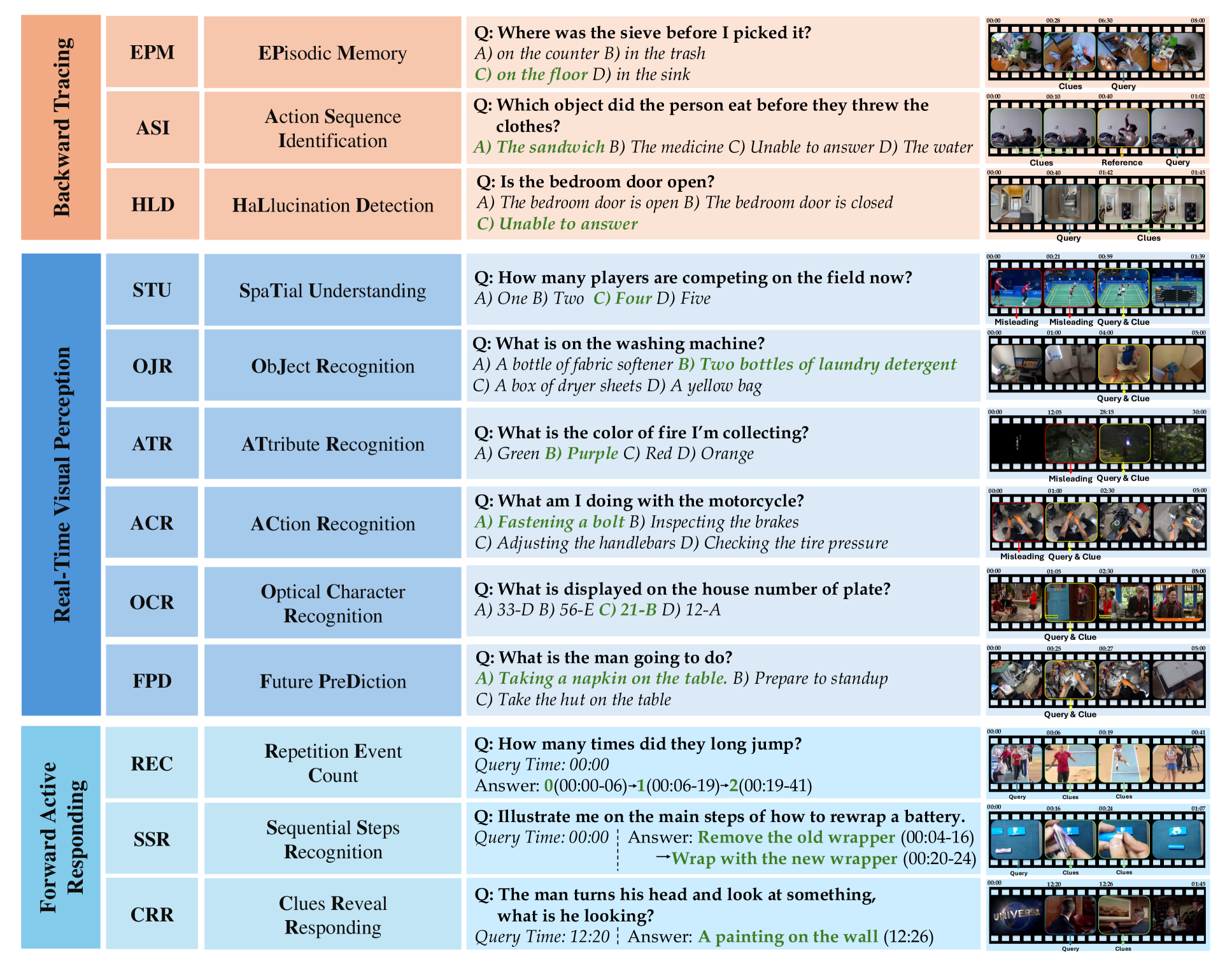
核心思路:OVO-Bench的核心思路是构建一个强调时间戳重要性的视频基准,通过设计不同的任务场景,考察模型在不同时间点对视频内容的理解和推理能力。具体来说,OVO-Bench包含回溯过去事件、实时理解当前事件和前瞻性地延迟响应三种场景,要求模型根据问题提出的时间戳,动态地调整其响应策略。
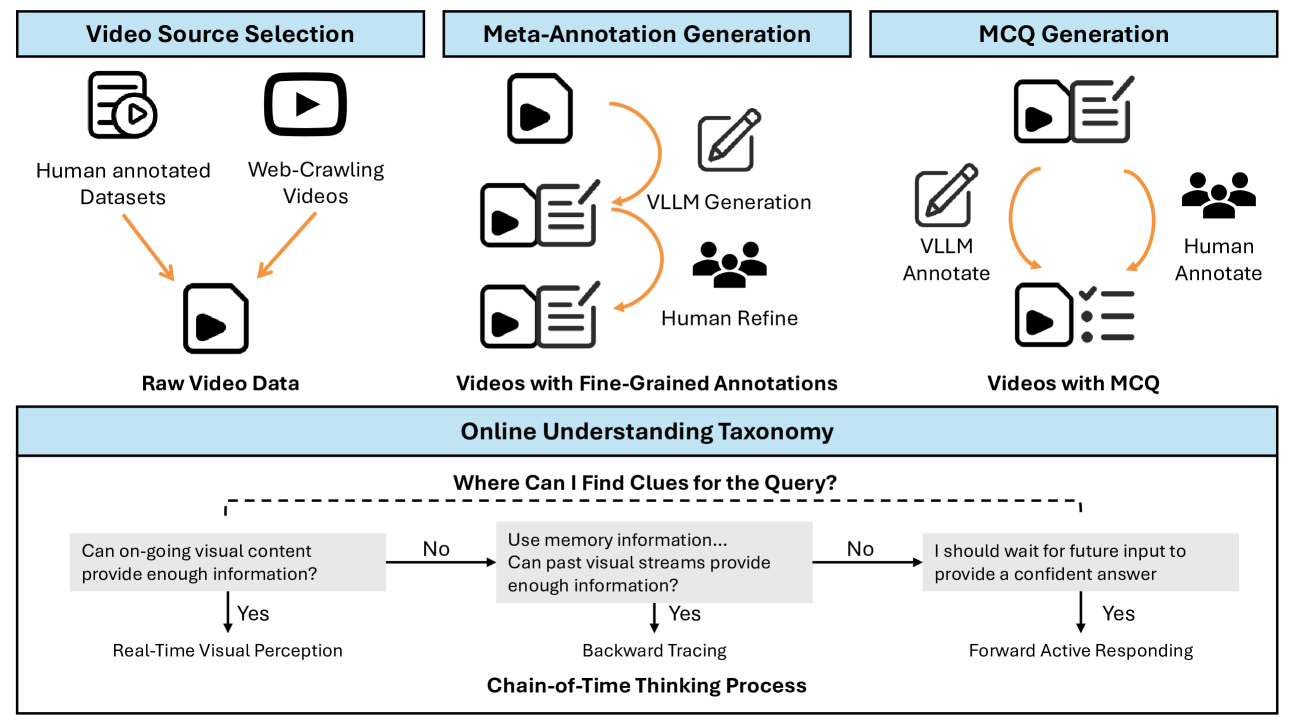
技术框架:OVO-Bench的整体框架包括数据收集与标注、任务设计和评估流程三个主要部分。首先,通过自动化生成和人工标注相结合的方式,构建高质量的视频数据集,并为每个视频添加细粒度的时间戳元数据。然后,基于这些数据,设计12个不同的任务,涵盖上述三种场景。最后,开发一个评估流程,系统地沿着视频时间线查询Video-LLMs,并根据模型的响应质量进行评估。
关键创新:OVO-Bench最重要的技术创新点在于其对时间戳的强调和对在线视频理解场景的模拟。与现有基准测试不同,OVO-Bench要求模型不仅要理解视频内容,还要根据问题提出的时间戳,动态地调整其响应策略。这种设计更贴近现实世界的视频应用场景,能够更准确地评估模型在在线视频理解任务中的性能。
关键设计:OVO-Bench的关键设计包括:1) 细粒度的时间戳元数据标注,确保模型能够准确地理解视频内容的时间信息;2) 多样化的任务设计,涵盖回溯、实时和前瞻三种不同的场景,全面评估模型的时间感知能力;3) 系统化的评估流程,确保能够沿着视频时间线全面地评估模型的性能。
🖼️ 关键图片
📊 实验亮点
对九个Video-LLMs在OVO-Bench上的评估结果显示,现有模型在在线视频理解方面表现显著低于人类水平。例如,在需要回溯过去事件的任务中,模型的准确率远低于人类。这表明,尽管Video-LLMs在传统基准上取得了进展,但在时间感知和在线视频理解方面仍存在很大的提升空间。
🎯 应用场景
OVO-Bench的研究成果可应用于开发更智能的视频监控系统、实时视频分析工具、以及更具交互性的视频助手。通过提升视频LLM的时间感知能力,可以实现更精准的事件检测、更及时的风险预警和更自然的视频交互体验,从而在安防、教育、娱乐等领域产生广泛的应用价值。
📄 摘要(原文)
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.