Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark
作者: Yunzhuo Hao, Jiawei Gu, Huichen Will Wang, Linjie Li, Zhengyuan Yang, Lijuan Wang, Yu Cheng
分类: cs.CV
发布日期: 2025-01-09
💡 一句话要点
提出EMMA:增强多模态推理基准,评估MLLM在复杂跨模态推理中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 大型语言模型 基准测试 跨模态学习 视觉文本融合
📋 核心要点
- 现有基准测试未能充分评估多模态大型语言模型在复杂视觉和文本推理上的集成能力。
- EMMA基准通过数学、物理、化学和编码等多领域任务,着重考察模型跨模态推理能力。
- 实验表明,现有MLLM在EMMA基准上表现出显著局限性,即使采用先进技术也难以有效解决。
📝 摘要(中文)
人类智能的一个重要支柱是有机地对文本和图像进行推理。然而,多模态大型语言模型(MLLM)执行这种多模态推理的能力仍未得到充分探索。现有的基准通常强调文本主导的推理或依赖于浅层的视觉线索,未能充分评估集成的视觉和文本推理。我们引入了EMMA(增强多模态推理),一个针对数学、物理、化学和编码等领域中有机多模态推理的基准。EMMA任务需要高级的跨模态推理,而不能通过独立地在每个模态中进行推理来解决,为MLLM的推理能力提供了一个增强的测试套件。我们对最先进的MLLM在EMMA上的评估表明,即使采用诸如思维链提示和测试时计算缩放等先进技术,它们在处理复杂的多模态和多步骤推理任务方面也存在显著的局限性。这些发现强调需要改进多模态架构和训练范式,以缩小人类和模型在多模态推理方面的差距。
🔬 方法详解
问题定义:论文旨在解决现有MLLM在复杂多模态推理能力上的不足。现有基准测试要么侧重于文本推理,要么依赖于简单的视觉线索,无法有效评估模型在需要深度融合视觉和文本信息的任务上的表现。因此,需要一个更具挑战性的基准来推动MLLM在多模态推理方面的研究。
核心思路:论文的核心思路是构建一个更具挑战性的多模态推理基准,即EMMA。EMMA包含数学、物理、化学和编码等多个领域的任务,这些任务需要模型进行复杂的跨模态推理,而不能简单地通过独立处理每个模态的信息来解决。通过评估MLLM在EMMA上的表现,可以更准确地了解其多模态推理能力。
技术框架:EMMA基准包含多个领域的任务,每个任务都包含文本描述和图像信息。模型需要同时理解文本和图像,并进行推理才能得到正确答案。评估过程包括使用不同的提示策略(如思维链)和计算资源来测试模型的性能。最终,通过比较模型在EMMA上的表现来评估其多模态推理能力。
关键创新:EMMA的关键创新在于其任务设计的复杂性和多样性。与现有基准相比,EMMA的任务更需要模型进行深度跨模态推理,而不是简单地依赖于文本或图像中的表面信息。此外,EMMA涵盖了多个领域,可以更全面地评估模型的推理能力。
关键设计:EMMA的任务设计考虑了以下关键因素:1) 需要跨模态推理:任务不能通过单独分析文本或图像来解决。2) 涉及多个推理步骤:任务需要模型进行多步推理才能得到答案。3) 涵盖多个领域:任务涵盖数学、物理、化学和编码等多个领域。具体的参数设置、损失函数和网络结构取决于被评估的MLLM。
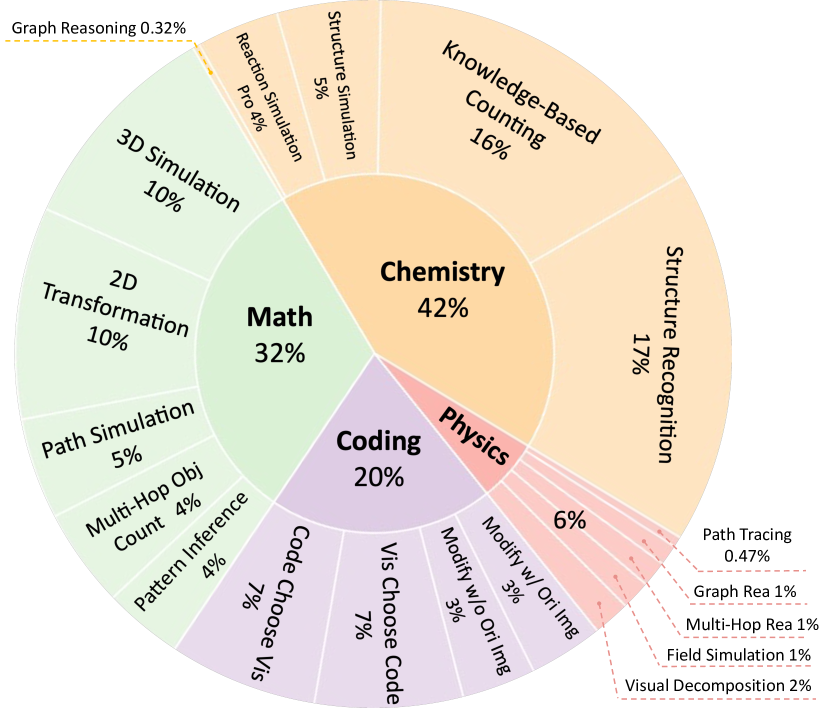
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最先进的MLLM在EMMA基准上的表现也远低于人类水平,即使采用思维链提示和测试时计算缩放等技术,性能提升也有限。这表明现有MLLM在处理复杂多模态推理任务方面仍存在显著差距,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于开发更智能的多模态人工智能系统,例如智能教育、科学研究助手、以及能够理解和处理复杂视觉和文本信息的机器人。通过提高MLLM的多模态推理能力,可以实现更自然和高效的人机交互,并解决更广泛的现实世界问题。
📄 摘要(原文)
The ability to organically reason over and with both text and images is a pillar of human intelligence, yet the ability of Multimodal Large Language Models (MLLMs) to perform such multimodal reasoning remains under-explored. Existing benchmarks often emphasize text-dominant reasoning or rely on shallow visual cues, failing to adequately assess integrated visual and textual reasoning. We introduce EMMA (Enhanced MultiModal reAsoning), a benchmark targeting organic multimodal reasoning across mathematics, physics, chemistry, and coding. EMMA tasks demand advanced cross-modal reasoning that cannot be addressed by reasoning independently in each modality, offering an enhanced test suite for MLLMs' reasoning capabilities. Our evaluation of state-of-the-art MLLMs on EMMA reveals significant limitations in handling complex multimodal and multi-step reasoning tasks, even with advanced techniques like Chain-of-Thought prompting and test-time compute scaling underperforming. These findings underscore the need for improved multimodal architectures and training paradigms to close the gap between human and model reasoning in multimodality.