Progressive Growing of Video Tokenizers for Temporally Compact Latent Spaces
作者: Aniruddha Mahapatra, Long Mai, David Bourgin, Yitian Zhang, Feng Liu
分类: cs.CV, cs.AI, eess.IV
发布日期: 2025-01-09 (更新: 2025-08-02)
备注: Project website: https://progressive-video-tokenizer.github.io/Pro-MAG/
💡 一句话要点
提出渐进式视频Tokenizers训练方法,实现时序紧凑的潜在空间表示
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频Tokenizer 时间压缩 潜在空间 视频扩散模型 渐进式学习 跨层特征混合 视频重建 自监督学习
📋 核心要点
- 现有视频Tokenizer难以在不增加通道容量的情况下实现高时间压缩比,限制了视频扩散模型的效率。
- 提出一种渐进式训练方法,从低压缩模型出发,逐步训练高压缩模块,利用跨层特征混合保留信息。
- 实验表明,该方法显著提高重建质量,增加时间压缩比,并能有效训练高质量视频生成扩散模型。
📝 摘要(中文)
视频Tokenizers对于潜在视频扩散模型至关重要,它们将原始视频数据转换为时空压缩的潜在空间,以实现高效训练。然而,在不增加通道容量的情况下,扩展最先进的视频Tokenizers以实现超过4倍的时间压缩比,面临着巨大的挑战。本文提出了一种增强时间压缩的替代方法。研究发现,从低压缩编码器中重建时间子采样的视频的质量,超过了应用于原始视频的高压缩编码器。这表明高压缩模型可以利用来自低压缩模型的表示。基于此,我们开发了一种自举式高时间压缩模型,该模型在经过良好训练的低压缩模型之上,逐步训练高压缩块。我们的方法包括一个跨层特征混合模块,以保留来自预训练的低压缩模型的信息,并引导更高压缩块捕获来自完整视频序列的剩余细节。视频基准的评估表明,与直接训练完整模型相比,我们的方法显著提高了重建质量,同时增加了时间压缩。此外,由此产生的紧凑潜在空间有效地训练了一个视频扩散模型,用于高质量的视频生成,并显著降低了token预算。
🔬 方法详解
问题定义:当前视频 Tokenizer 在时间维度上的压缩能力不足,尤其是在不增加模型参数量(如通道数)的前提下,难以实现高压缩比。直接训练高压缩比的 Tokenizer 效果不佳,导致重建质量下降,进而影响下游视频生成任务的性能。现有方法难以兼顾高压缩比和高质量重建。
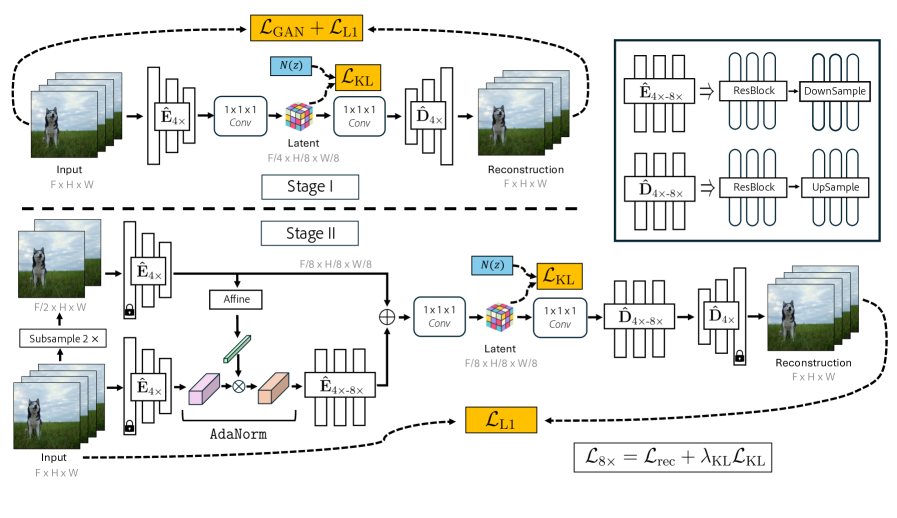
核心思路:论文的核心思想是利用低压缩比 Tokenizer 已经学习到的视频表示作为先验知识,逐步构建高压缩比 Tokenizer。作者观察到,对时间子采样后的视频进行低压缩比编码,其重建效果优于直接对原始视频进行高压缩比编码。因此,可以先训练一个低压缩比的 Tokenizer,然后在此基础上逐步增加时间压缩模块,从而实现高压缩比。
技术框架:整体框架包含一个预训练的低压缩比 Tokenizer 和一系列逐步增加时间压缩能力的高压缩比模块。训练过程分为两个阶段:首先,训练一个低压缩比的 Tokenizer。然后,固定低压缩比 Tokenizer 的参数,逐步添加并训练高压缩比模块。在训练高压缩比模块时,使用跨层特征混合模块,将低压缩比 Tokenizer 的特征信息融入到高压缩比模块中,以引导高压缩比模块的学习。
关键创新:该方法的核心创新在于渐进式的训练策略和跨层特征混合模块。渐进式训练避免了直接训练高压缩比 Tokenizer 的困难,利用了低压缩比 Tokenizer 的先验知识。跨层特征混合模块则保证了高压缩比模块能够充分利用低压缩比 Tokenizer 的信息,从而提高重建质量。
关键设计:跨层特征混合模块是关键设计之一,它将低压缩比 Tokenizer 的特征图与高压缩比模块的特征图进行融合。具体的融合方式可以是简单的拼接或加权求和,也可以是更复杂的注意力机制。损失函数方面,除了重建损失外,还可以加入一些正则化项,以防止过拟合。时间压缩模块的具体结构可以是卷积层、Transformer 层等,具体选择取决于具体的应用场景。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在视频重建质量上显著优于直接训练高压缩比 Tokenizer 的方法。具体而言,在多个视频基准数据集上,该方法能够以更高的压缩比实现更低的重建误差(如MSE、PSNR等)。同时,使用该方法训练的视频扩散模型能够生成更高质量的视频,且所需的token预算更低。
🎯 应用场景
该研究成果可应用于视频压缩、视频检索、视频生成等领域。通过高效的视频 Tokenizer,可以显著降低视频数据的存储和传输成本,提高视频检索的效率,并为高质量的视频生成提供更紧凑的潜在空间表示。尤其在计算资源受限的场景下,该方法具有重要的应用价值。
📄 摘要(原文)
Video tokenizers are essential for latent video diffusion models, converting raw video data into spatiotemporally compressed latent spaces for efficient training. However, extending state-of-the-art video tokenizers to achieve a temporal compression ratio beyond 4x without increasing channel capacity poses significant challenges. In this work, we propose an alternative approach to enhance temporal compression. We find that the reconstruction quality of temporally subsampled videos from a low-compression encoder surpasses that of high-compression encoders applied to original videos. This indicates that high-compression models can leverage representations from lower-compression models. Building on this insight, we develop a bootstrapped high-temporal-compression model that progressively trains high-compression blocks atop well-trained lower-compression models. Our method includes a cross-level feature-mixing module to retain information from the pretrained low-compression model and guide higher-compression blocks to capture the remaining details from the full video sequence. Evaluation of video benchmarks shows that our method significantly improves reconstruction quality while increasing temporal compression compared to directly training the full model. Furthermore, the resulting compact latent space effectively trains a video diffusion model for high-quality video generation with a significantly reduced token budget.