Arc2Avatar: Generating Expressive 3D Avatars from a Single Image via ID Guidance
作者: Dimitrios Gerogiannis, Foivos Paraperas Papantoniou, Rolandos Alexandros Potamias, Alexandros Lattas, Stefanos Zafeiriou
分类: cs.CV
发布日期: 2025-01-09 (更新: 2025-01-13)
备注: Project Page https://arc2avatar.github.io
💡 一句话要点
Arc2Avatar:基于单张图像和ID引导生成逼真可控的3D头像
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D头像生成 单图重建 人脸基础模型 3D高斯溅射 身份保持 表情生成
📋 核心要点
- 现有方法难以仅用单张图像生成高质量、可控的3D人脸头像,尤其是在保持身份信息和生成逼真表情方面。
- Arc2Avatar利用预训练的人脸基础模型作为先验知识,结合改进的3D高斯溅射,实现单张图像到3D头像的生成,并保持身份一致性。
- 实验表明,Arc2Avatar在真实感和身份保持方面达到了最先进水平,并能有效生成多样化的面部表情。
📝 摘要(中文)
Arc2Avatar 是一种基于单张图像生成富有表现力的3D头像的新方法。该方法受到3D高斯溅射(3DGS)在多视角场景重建中的有效性和大型2D人脸基础模型的启发,是第一个利用人脸基础模型作为指导的基于SDS的方法。为了实现这一点,该方法通过在合成数据上进行微调并修改其条件,扩展了该模型以生成多样视角的人头。生成的头像与人脸网格模板保持密集的对应关系,从而可以生成基于blendshape的表情。这是通过改进的3DGS方法、连接性正则化器以及为任务量身定制的策略性初始化来实现的。此外,该方法还提出了一个可选的、高效的基于SDS的校正步骤,以细化blendshape表情,从而增强真实感和多样性。实验表明,Arc2Avatar实现了最先进的真实感和身份保持,并通过允许使用非常低的指导有效地解决了颜色问题,这得益于强大的身份先验和初始化策略,而不会影响细节。
🔬 方法详解
问题定义:现有方法在仅使用单张图像生成高质量3D人脸头像时面临挑战,尤其是在保持身份信息、生成逼真表情以及处理颜色一致性问题上。这些方法通常需要多视角图像或复杂的训练流程,难以满足实际应用的需求。
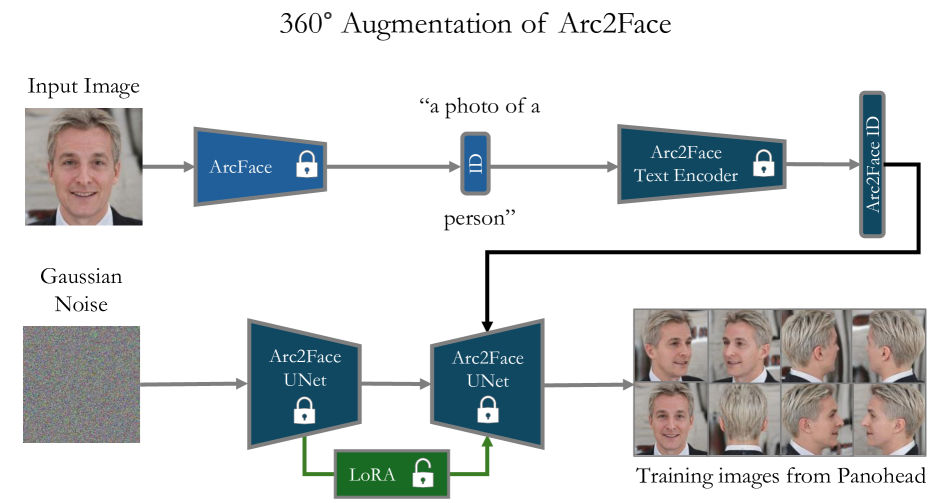
核心思路:Arc2Avatar的核心思路是利用预训练的人脸基础模型作为强大的先验知识,指导3D高斯溅射(3DGS)的优化过程。通过将2D人脸基础模型的知识迁移到3D空间,可以有效地约束3D头像的形状和纹理,从而生成更逼真、身份保持更好的结果。同时,通过对基础模型进行微调,使其能够生成多样视角的图像,从而为3DGS提供更丰富的指导信息。
技术框架:Arc2Avatar的整体框架包括以下几个主要模块:1) 人脸基础模型微调:在合成数据上微调预训练的人脸基础模型,使其能够生成多样视角的人头图像。2) 3DGS初始化:使用策略性的初始化方法,为3DGS提供一个良好的初始状态,加速优化过程。3) 3DGS优化:利用微调后的人脸基础模型作为指导,通过SDS损失函数优化3DGS参数,生成3D头像。4) 连接性正则化:引入连接性正则化器,保持3DGS点云的拓扑结构,避免生成不自然的形状。5) 表情细化:可选地,使用基于SDS的校正步骤,进一步细化blendshape表情,增强真实感和多样性。
关键创新:Arc2Avatar的关键创新在于:1) 单图引导的3D头像生成:首次利用人脸基础模型作为指导,实现了仅使用单张图像生成高质量3D头像。2) 策略性初始化:设计了针对性的初始化策略,加速了3DGS的优化过程,并提高了生成结果的质量。3) 表情细化步骤:提出了基于SDS的表情细化步骤,进一步增强了生成表情的真实感和多样性。
关键设计:在人脸基础模型微调阶段,使用了合成数据进行训练,并修改了模型的条件输入,使其能够生成多样视角的图像。在3DGS优化阶段,使用了SDS损失函数,该损失函数基于人脸基础模型生成的图像与3DGS渲染图像之间的差异进行计算。此外,还引入了连接性正则化器,以保持3DGS点云的拓扑结构。在表情细化阶段,使用了基于SDS的校正步骤,该步骤通过优化blendshape系数,进一步增强了生成表情的真实感和多样性。
🖼️ 关键图片


📊 实验亮点
Arc2Avatar 在真实感和身份保持方面达到了最先进水平。通过允许使用非常低的指导,有效地解决了颜色问题,这得益于强大的身份先验和初始化策略,而不会影响细节。实验结果表明,Arc2Avatar 能够生成高质量、身份一致的3D头像,并能有效生成多样化的面部表情,优于现有的单图3D头像生成方法。
🎯 应用场景
Arc2Avatar 技术在虚拟现实、增强现实、游戏开发、社交媒体等领域具有广泛的应用前景。它可以用于创建个性化的3D虚拟形象,用于在线会议、虚拟社交、游戏角色定制等场景。此外,该技术还可以应用于人脸识别、表情分析、动画制作等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Inspired by the effectiveness of 3D Gaussian Splatting (3DGS) in reconstructing detailed 3D scenes within multi-view setups and the emergence of large 2D human foundation models, we introduce Arc2Avatar, the first SDS-based method utilizing a human face foundation model as guidance with just a single image as input. To achieve that, we extend such a model for diverse-view human head generation by fine-tuning on synthetic data and modifying its conditioning. Our avatars maintain a dense correspondence with a human face mesh template, allowing blendshape-based expression generation. This is achieved through a modified 3DGS approach, connectivity regularizers, and a strategic initialization tailored for our task. Additionally, we propose an optional efficient SDS-based correction step to refine the blendshape expressions, enhancing realism and diversity. Experiments demonstrate that Arc2Avatar achieves state-of-the-art realism and identity preservation, effectively addressing color issues by allowing the use of very low guidance, enabled by our strong identity prior and initialization strategy, without compromising detail. Please visit https://arc2avatar.github.io for more resources.