CellViT++: Energy-Efficient and Adaptive Cell Segmentation and Classification Using Foundation Models
作者: Fabian Hörst, Moritz Rempe, Helmut Becker, Lukas Heine, Julius Keyl, Jens Kleesiek
分类: cs.CV, cs.LG
发布日期: 2025-01-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出CellViT++以解决数字病理中细胞分割与分类问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数字病理学 细胞分割 视觉变换器 基础模型 零样本学习 自动化标注 数据效率
📋 核心要点
- 现有细胞分割方法依赖大量标注数据,且通常受限于固定的细胞分类方案,限制了其适应性和效率。
- CellViT++框架结合视觉变换器和基础模型,能够同时进行细胞特征提取和分割,且对新细胞类型具有良好的适应性。
- 在七个不同的数据集上,CellViT++实现了卓越的零样本分割和高效的细胞类型分类,且无需专家标注即可生成高质量训练数据。
📝 摘要(中文)
数字病理学是疾病诊断和治疗的基石,其中细胞的识别和分割是关键任务。现有的细胞分割方法通常需要大量标注数据进行训练,并且受限于预定义的细胞分类方案。为了解决这些问题,本文提出了CellViT++框架,利用视觉变换器和基础模型作为编码器,同时计算深层细胞特征和分割掩膜。该方法在训练时需要的数据量极少,且显著降低了碳足迹。实验结果表明,CellViT++在七个不同数据集上表现出色,能够实现零样本分割和数据高效的细胞类型分类。此外,该框架能够利用免疫荧光染色生成训练数据集,无需病理学家的标注,且其自动化数据集生成方法的性能超过了基于手动标注数据训练的网络。为推动数字病理学的发展,CellViT++作为开源框架提供了用户友好的网页界面用于可视化和标注。
🔬 方法详解
问题定义:本文旨在解决数字病理学中细胞分割和分类的挑战,现有方法通常需要大量标注数据,且适应性差,限制了其应用。
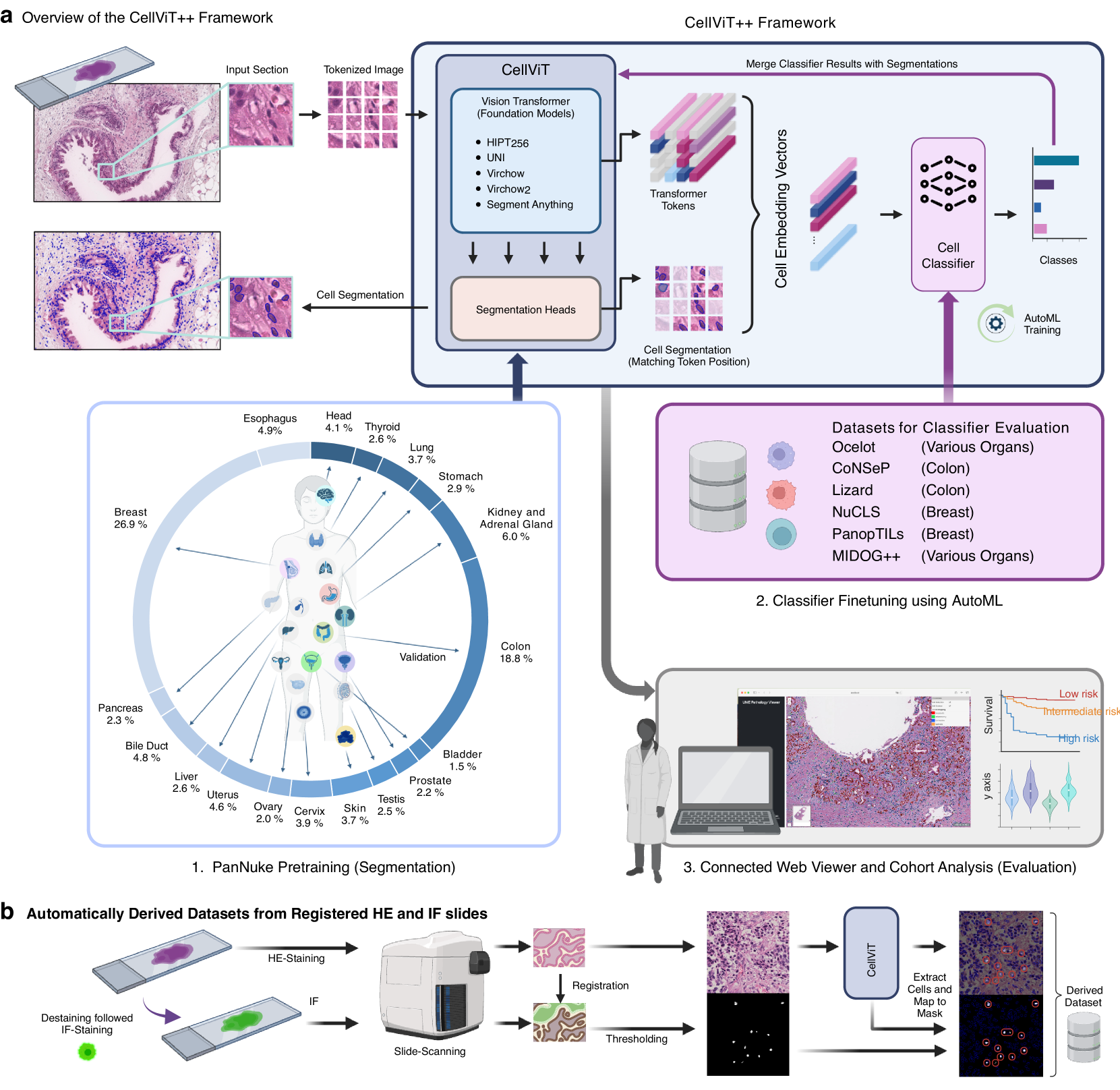
核心思路:CellViT++框架通过结合视觉变换器和基础模型,能够高效提取细胞特征并生成分割掩膜,适应未见细胞类型,减少对标注数据的依赖。
技术框架:该框架包括两个主要模块:细胞特征提取模块和分割模块,利用视觉变换器作为编码器,进行深层特征计算和掩膜生成。
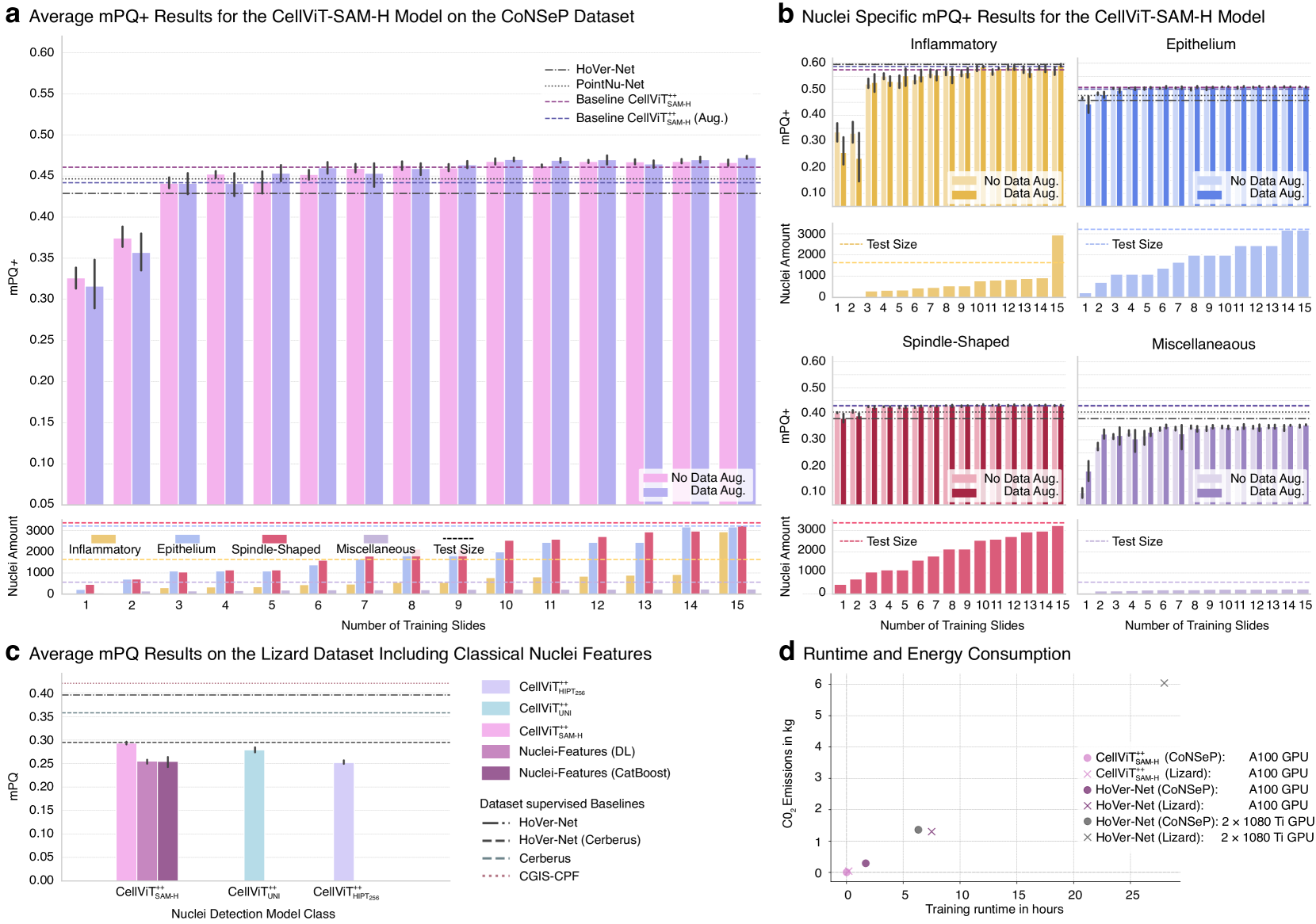
关键创新:CellViT++的创新在于其高效的数据利用方式和零样本学习能力,能够在缺乏标注数据的情况下,仍然实现高性能的细胞分割和分类,显著降低了碳足迹。
关键设计:在网络结构上,CellViT++采用了视觉变换器架构,设计了适应性损失函数以优化细胞特征提取,同时通过免疫荧光染色生成训练数据,避免了对专家标注的依赖。
🖼️ 关键图片

📊 实验亮点
在七个不同的数据集上,CellViT++实现了卓越的零样本分割和细胞类型分类,性能超过了基于手动标注数据训练的网络,展示了其在数据效率和适应性方面的显著优势。
🎯 应用场景
CellViT++在数字病理学中的应用潜力巨大,能够用于癌症诊断、组织切片分析等领域。其高效的细胞分割和分类能力将推动病理学研究的自动化和智能化,降低对人工标注的需求,提升诊断效率和准确性。
📄 摘要(原文)
Digital Pathology is a cornerstone in the diagnosis and treatment of diseases. A key task in this field is the identification and segmentation of cells in hematoxylin and eosin-stained images. Existing methods for cell segmentation often require extensive annotated datasets for training and are limited to a predefined cell classification scheme. To overcome these limitations, we propose $\text{CellViT}^{\scriptscriptstyle ++}$, a framework for generalized cell segmentation in digital pathology. $\text{CellViT}^{\scriptscriptstyle ++}$ utilizes Vision Transformers with foundation models as encoders to compute deep cell features and segmentation masks simultaneously. To adapt to unseen cell types, we rely on a computationally efficient approach. It requires minimal data for training and leads to a drastically reduced carbon footprint. We demonstrate excellent performance on seven different datasets, covering a broad spectrum of cell types, organs, and clinical settings. The framework achieves remarkable zero-shot segmentation and data-efficient cell-type classification. Furthermore, we show that $\text{CellViT}^{\scriptscriptstyle ++}$ can leverage immunofluorescence stainings to generate training datasets without the need for pathologist annotations. The automated dataset generation approach surpasses the performance of networks trained on manually labeled data, demonstrating its effectiveness in creating high-quality training datasets without expert annotations. To advance digital pathology, $\text{CellViT}^{\scriptscriptstyle ++}$ is available as an open-source framework featuring a user-friendly, web-based interface for visualization and annotation. The code is available under https://github.com/TIO-IKIM/CellViT-plus-plus.