Harnessing Large Language and Vision-Language Models for Robust Out-of-Distribution Detection
作者: Pei-Kang Lee, Jun-Cheng Chen, Ja-Ling Wu
分类: cs.CV
发布日期: 2025-01-09
备注: 9 pages, 4 figures
💡 一句话要点
利用大语言模型和视觉-语言模型增强鲁棒的分布外检测能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布外检测 零样本学习 视觉-语言模型 大语言模型 鲁棒性 提示调优 语义特征
📋 核心要点
- 现有零样本OOD检测方法侧重于提升远域OOD性能,可能牺牲近域OOD的有效性,存在性能瓶颈。
- 利用LLM生成超类和背景描述,提取并提炼ID数据的核心语义特征,从而选择更合适的负标签。
- 通过少样本提示调优和视觉提示调优,使框架更好地适应目标分布,实验结果表明性能显著提升。
📝 摘要(中文)
本文提出了一种新颖的策略,通过创新性地利用大型语言模型(LLM)和视觉-语言模型(VLM),来增强远域(Far-OOD)和近域(Near-OOD)场景下的零样本分布外(OOD)检测性能。该方法首先利用LLM生成ID标签的超类及其对应的背景描述,然后使用CLIP提取特征。接着,通过从超类特征中减去背景特征,隔离ID数据的核心语义特征。这种精炼的表示有助于从WordNet的综合候选标签集中为OOD数据选择更合适的负标签,从而提高两种场景下的零样本OOD检测性能。此外,我们还引入了新颖的少样本提示调优和视觉提示调优,以使提出的框架更好地适应目标分布。实验结果表明,该方法在多个基准测试中始终优于当前最先进的方法,AUROC提高了2.9%,FPR95降低了12.6%。此外,我们的方法在不同领域的协变量偏移下表现出卓越的鲁棒性,进一步突显了其在实际场景中的有效性。
🔬 方法详解
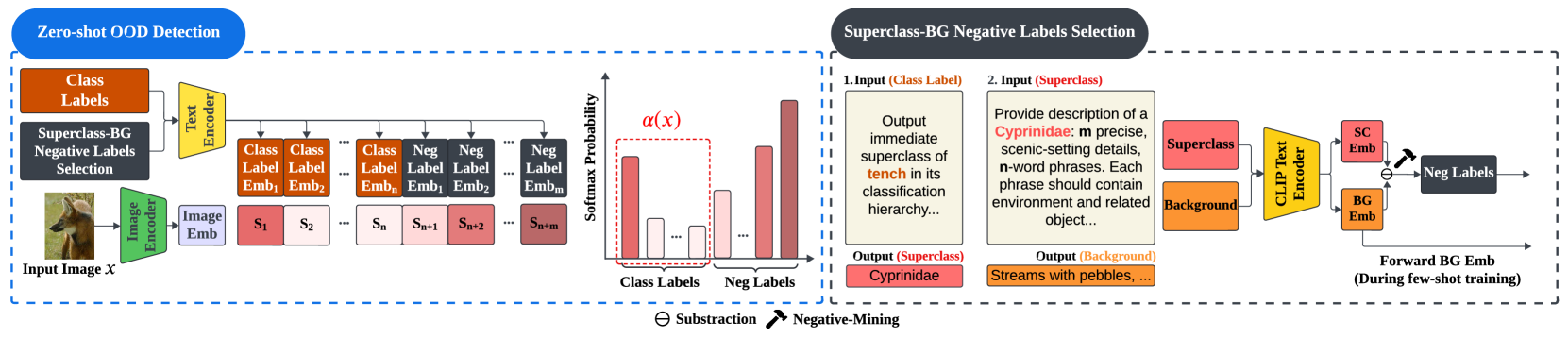
问题定义:论文旨在解决零样本分布外(OOD)检测中,现有方法在提升远域OOD检测性能的同时,牺牲近域OOD检测性能的问题。现有方法难以有效区分与训练数据相似但又不同的OOD样本,导致近域OOD检测效果不佳。
核心思路:论文的核心思路是利用大型语言模型(LLM)的语义理解能力,生成更具区分性的ID类别描述,并结合视觉-语言模型(VLM)提取特征。通过从类别特征中去除背景特征,突出ID数据的核心语义信息,从而更好地选择OOD数据的负标签,提升OOD检测的准确性。
技术框架:整体框架包含以下几个主要阶段:1) 利用LLM生成ID标签的超类和背景描述;2) 使用CLIP提取超类和背景描述的特征;3) 通过特征相减,提取ID数据的核心语义特征;4) 从WordNet中选择合适的负标签;5) 利用提取的特征和选择的负标签进行OOD检测。此外,还引入了少样本提示调优和视觉提示调优来适应目标分布。
关键创新:论文的关键创新在于:1) 创新性地利用LLM生成超类和背景描述,从而更好地提取ID数据的核心语义特征;2) 提出了一种基于特征相减的方法,用于去除背景特征,突出ID数据的核心语义信息;3) 引入了少样本提示调优和视觉提示调优,以适应目标分布。
关键设计:在利用LLM生成超类和背景描述时,使用了特定的prompt模板。在特征提取阶段,使用了预训练的CLIP模型。在负标签选择阶段,使用了WordNet作为候选标签集,并根据特征相似度选择合适的负标签。少样本提示调优和视觉提示调优的具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个基准测试中均优于当前最先进的方法,AUROC指标最高提升了2.9%,FPR95指标最高降低了12.6%。此外,该方法在不同领域的协变量偏移下表现出更强的鲁棒性,表明其在实际应用中具有更好的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要识别未知或异常数据的场景,例如:自动驾驶中的异常物体检测、医疗图像分析中的疾病诊断、金融风控中的欺诈检测、工业质检中的缺陷检测等。通过提高OOD检测的准确性和鲁棒性,可以有效降低误判率,提升系统的安全性和可靠性,具有重要的实际应用价值。
📄 摘要(原文)
Out-of-distribution (OOD) detection has seen significant advancements with zero-shot approaches by leveraging the powerful Vision-Language Models (VLMs) such as CLIP. However, prior research works have predominantly focused on enhancing Far-OOD performance, while potentially compromising Near-OOD efficacy, as observed from our pilot study. To address this issue, we propose a novel strategy to enhance zero-shot OOD detection performances for both Far-OOD and Near-OOD scenarios by innovatively harnessing Large Language Models (LLMs) and VLMs. Our approach first exploit an LLM to generate superclasses of the ID labels and their corresponding background descriptions followed by feature extraction using CLIP. We then isolate the core semantic features for ID data by subtracting background features from the superclass features. The refined representation facilitates the selection of more appropriate negative labels for OOD data from a comprehensive candidate label set of WordNet, thereby enhancing the performance of zero-shot OOD detection in both scenarios. Furthermore, we introduce novel few-shot prompt tuning and visual prompt tuning to adapt the proposed framework to better align with the target distribution. Experimental results demonstrate that the proposed approach consistently outperforms current state-of-the-art methods across multiple benchmarks, with an improvement of up to 2.9% in AUROC and a reduction of up to 12.6% in FPR95. Additionally, our method exhibits superior robustness against covariate shift across different domains, further highlighting its effectiveness in real-world scenarios.