Light Transport-aware Diffusion Posterior Sampling for Single-View Reconstruction of 3D Volumes
作者: Ludwic Leonard, Nils Thuerey, Ruediger Westermann
分类: cs.CV, cs.LG
发布日期: 2025-01-09 (更新: 2025-03-28)
备注: CVPR 2025
💡 一句话要点
提出光传输感知扩散后验采样,用于单视角三维体积重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 体积重建 扩散模型 光传输 可微渲染 单视角重建
📋 核心要点
- 现有NeRF方法在处理具有复杂光散射的体积云单视角重建时存在局限性,难以准确建模光传输。
- 论文提出一种基于扩散模型的体积场重建方法,利用扩散后验采样技术和可微渲染,优化潜在空间中的光传输。
- 实验表明,该方法在体积云单视角重建任务中取得了显著提升,重建质量达到前所未有的水平。
📝 摘要(中文)
本文提出了一种体积场单视角重建技术,该技术适用于多重光散射效应普遍存在的场景,例如云。我们使用无条件扩散模型来建模未知的体积场分布,该模型在一个包含1000个合成模拟体积密度场的新基准数据集上进行训练。神经扩散模型在一种新颖的、扩散友好的单平面表示的潜在代码上进行训练。生成模型被用于将定制的参数化扩散后验采样技术整合到不同的重建任务中。采用基于物理的可微体积渲染器来提供关于潜在空间中光传输的梯度。这与经典的NeRF方法形成对比,并使重建结果与观察到的数据更好地对齐。通过各种实验,我们展示了以前无法达到的高质量的体积云单视角重建。
🔬 方法详解
问题定义:论文旨在解决从单个视角图像重建具有复杂光散射效应的3D体积云的问题。现有方法,特别是基于NeRF的方法,在处理这种复杂的光传输时表现不佳,难以准确捕捉云的细节和光照效果。
核心思路:论文的核心思路是利用扩散模型学习体积密度场的先验分布,并结合基于物理的可微渲染,通过优化潜在空间中的光传输来指导重建过程。通过扩散后验采样,可以生成符合观测数据的多种可能的体积场,从而提高重建的鲁棒性和准确性。
技术框架:整体框架包括以下几个主要模块:1) 使用合成数据训练一个无条件扩散模型,学习体积密度场的潜在表示;2) 使用单平面表示对体积场进行编码,使其更适合扩散模型;3) 利用可微体积渲染器,计算重建图像与输入图像之间的差异,并反向传播梯度到潜在空间;4) 使用扩散后验采样技术,在潜在空间中搜索符合观测数据的体积场。
关键创新:最重要的创新点在于将扩散模型与光传输感知的可微渲染相结合,实现单视角体积云的高质量重建。与传统的NeRF方法相比,该方法能够更好地建模复杂的光散射效应,并利用扩散模型的生成能力来提高重建的鲁棒性。
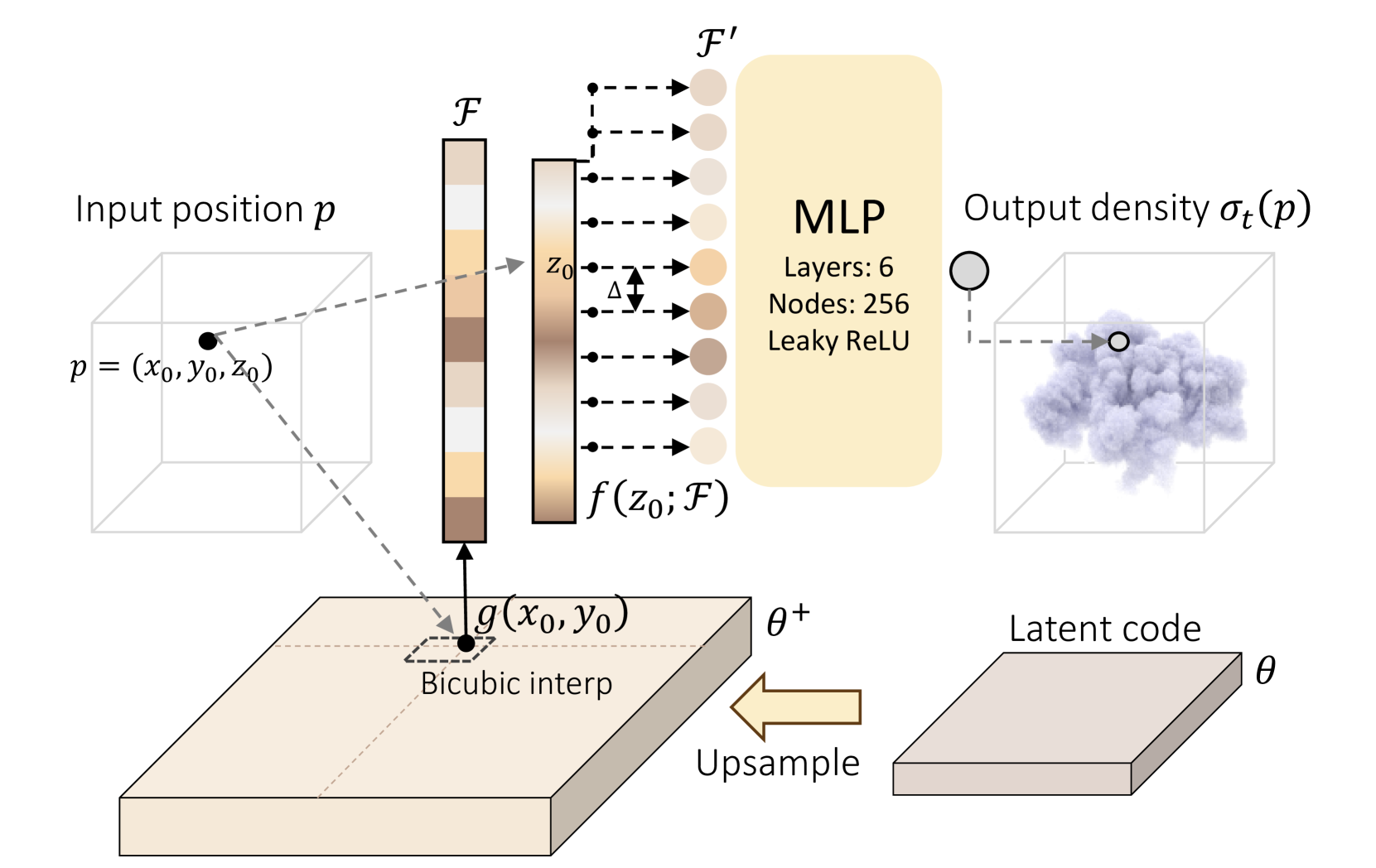
关键设计:论文使用了一种新颖的单平面表示,将三维体积场编码为二维图像,从而更易于使用扩散模型进行学习。损失函数包括重建损失和正则化项,用于约束潜在空间的分布。扩散模型采用U-Net结构,并使用DDPM采样策略。可微渲染器基于物理模型,能够准确计算光在体积中的传输过程。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明,该方法在单视角体积云重建任务中取得了显著的性能提升。与现有方法相比,重建结果在视觉质量和定量指标上均有明显改善。特别是在处理具有复杂光散射的云层时,该方法能够更准确地捕捉云的细节和光照效果,重建结果更加逼真。
🎯 应用场景
该研究成果可应用于气象学、计算机图形学、电影特效等领域。例如,可以利用单张卫星图像重建三维云层结构,用于天气预报和气候研究。在电影特效中,可以快速生成逼真的云雾效果,提高制作效率和视觉质量。此外,该方法还可以扩展到其他具有复杂光散射效应的场景,如烟雾、火焰等。
📄 摘要(原文)
We introduce a single-view reconstruction technique of volumetric fields in which multiple light scattering effects are omnipresent, such as in clouds. We model the unknown distribution of volumetric fields using an unconditional diffusion model trained on a novel benchmark dataset comprising 1,000 synthetically simulated volumetric density fields. The neural diffusion model is trained on the latent codes of a novel, diffusion-friendly, monoplanar representation. The generative model is used to incorporate a tailored parametric diffusion posterior sampling technique into different reconstruction tasks. A physically-based differentiable volume renderer is employed to provide gradients with respect to light transport in the latent space. This stands in contrast to classic NeRF approaches and makes the reconstructions better aligned with observed data. Through various experiments, we demonstrate single-view reconstruction of volumetric clouds at a previously unattainable quality.