Discovering Hidden Visual Concepts Beyond Linguistic Input in Infant Learning
作者: Xueyi Ke, Satoshi Tsutsui, Yayun Zhang, Bihan Wen
分类: cs.CV, cs.AI
发布日期: 2025-01-09 (更新: 2025-06-13)
备注: Accepted at CVPR 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
探索婴儿学习机制:发现超越语言输入的隐藏视觉概念
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 婴儿学习 视觉概念 神经元标记 表征学习 认知科学
📋 核心要点
- 现有计算机视觉模型缺乏对婴儿早期视觉学习机制的有效模拟,限制了其泛化能力和对真实世界复杂场景的理解。
- 该研究通过分析在婴儿视觉和语言数据上训练的模型,探索其内部表征中蕴含的、超越语言输入的隐藏视觉概念。
- 实验结果表明,该模型能够识别超出训练词汇范围的物体,并揭示了与传统计算机视觉模型在表征上的差异。
📝 摘要(中文)
婴儿在获得语言技能之前就能迅速发展出复杂的视觉理解能力。计算机视觉领域试图复制人类视觉系统,理解婴儿的视觉发展可能提供有价值的见解。本文提出了一项跨学科研究,探讨了一个问题:模仿婴儿学习过程的计算模型能否发展出超越其所听到的词汇的更广泛的视觉概念,类似于婴儿的自然学习方式?为了研究这个问题,我们分析了Vong等人发表在Science上的一项研究中的模型,该模型在单个儿童的纵向、以自我为中心的图像以及转录的父母语音上进行训练。我们执行神经元标记以识别模型内部表示中隐藏的视觉概念神经元。然后,我们证明这些神经元可以识别超出模型原始词汇的对象。此外,我们比较了婴儿模型与现代计算机视觉模型(如CLIP和ImageNet预训练模型)在表征上的差异。最终,我们的工作通过分析在婴儿视觉和语言输入上训练的计算模型的内部表征,将认知科学和计算机视觉联系起来。
🔬 方法详解
问题定义:论文旨在探究一个模仿婴儿学习过程的计算模型,是否能够像婴儿一样,发展出超越其所接触的语言词汇的视觉概念。现有方法主要依赖于大规模标注数据集进行训练,缺乏对婴儿早期视觉学习机制的模拟,导致模型难以泛化到真实世界的复杂场景中。
核心思路:论文的核心思路是通过分析一个在婴儿视角数据上训练的计算模型的内部表征,来识别其中蕴含的视觉概念神经元。通过神经元标记技术,发现模型能够识别超出其训练词汇范围的物体,从而验证了模型具备发展超越语言输入的视觉概念的能力。
技术框架:该研究主要包含以下几个阶段:1) 使用Vong等人在Science上发表的模型,该模型在纵向的婴儿视角图像和对应的父母语音数据上进行训练。2) 对训练后的模型进行神经元标记,以识别负责特定视觉概念的神经元。3) 测试这些神经元对超出模型原始词汇范围的物体的识别能力。4) 将婴儿模型与CLIP和ImageNet预训练模型等现代计算机视觉模型进行表征上的比较。
关键创新:该研究的关键创新在于将认知科学的研究方法引入计算机视觉领域,通过分析在婴儿视角数据上训练的模型,揭示了模型内部隐藏的、超越语言输入的视觉概念。这种方法为理解婴儿的视觉学习机制以及开发更具泛化能力的计算机视觉模型提供了新的思路。
关键设计:论文使用了Vong等人预训练好的模型,并在此基础上进行了神经元标记和表征分析。具体的神经元标记方法和表征比较方法在论文中没有详细描述,属于未知细节。损失函数和网络结构等细节沿用了Vong等人的设置。
🖼️ 关键图片
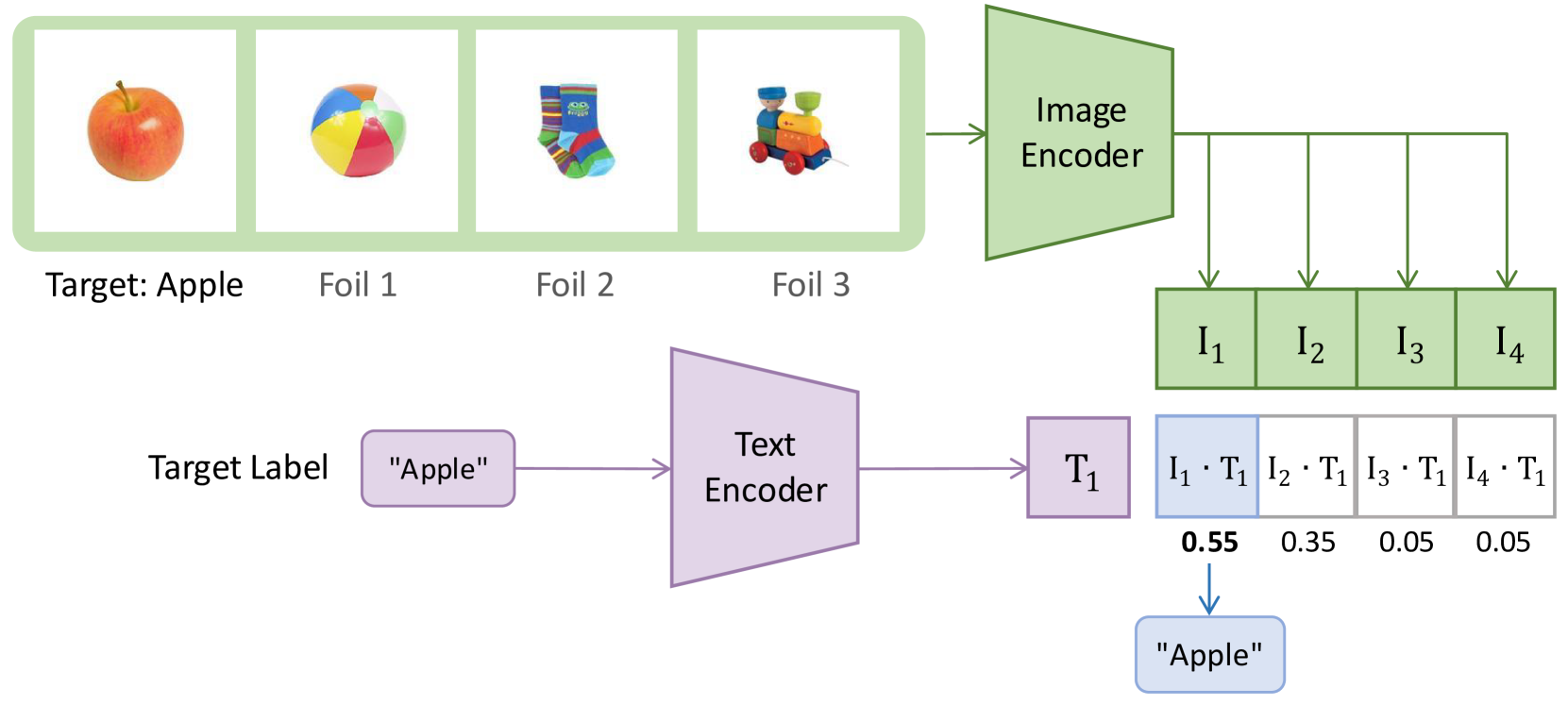


📊 实验亮点
该研究通过神经元标记技术,成功识别了在婴儿视角数据上训练的模型中,能够识别超出训练词汇范围的物体的神经元。这表明该模型具备发展超越语言输入的视觉概念的能力。此外,研究还对比了婴儿模型与CLIP和ImageNet预训练模型在表征上的差异,为理解不同模型的学习机制提供了新的视角。
🎯 应用场景
该研究成果可应用于开发更智能、更具泛化能力的计算机视觉系统,例如,可以用于提升机器人对未知环境的适应能力,或者用于开发更自然的图像理解和生成模型。此外,该研究也有助于我们更深入地理解人类的认知发展过程,为教育和儿童发展提供理论指导。
📄 摘要(原文)
Infants develop complex visual understanding rapidly, even preceding the acquisition of linguistic skills. As computer vision seeks to replicate the human vision system, understanding infant visual development may offer valuable insights. In this paper, we present an interdisciplinary study exploring this question: can a computational model that imitates the infant learning process develop broader visual concepts that extend beyond the vocabulary it has heard, similar to how infants naturally learn? To investigate this, we analyze a recently published model in Science by Vong et al., which is trained on longitudinal, egocentric images of a single child paired with transcribed parental speech. We perform neuron labeling to identify visual concept neurons hidden in the model's internal representations. We then demonstrate that these neurons can recognize objects beyond the model's original vocabulary. Furthermore, we compare the differences in representation between infant models and those in modern computer vision models, such as CLIP and ImageNet pre-trained model. Ultimately, our work bridges cognitive science and computer vision by analyzing the internal representations of a computational model trained on an infant visual and linguistic inputs. Project page is available at https://kexueyi.github.io/webpage-discover-hidden-visual-concepts.