V2C-CBM: Building Concept Bottlenecks with Vision-to-Concept Tokenizer
作者: Hangzhou He, Lei Zhu, Xinliang Zhang, Shuang Zeng, Qian Chen, Yanye Lu
分类: cs.CV
发布日期: 2025-01-09
备注: Accepted by AAAI2025
💡 一句话要点
提出V2C-CBM,利用视觉-概念Tokenizer构建高效且可解释的概念瓶颈模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念瓶颈模型 可解释性 视觉概念 多模态学习 视觉-概念Tokenizer
📋 核心要点
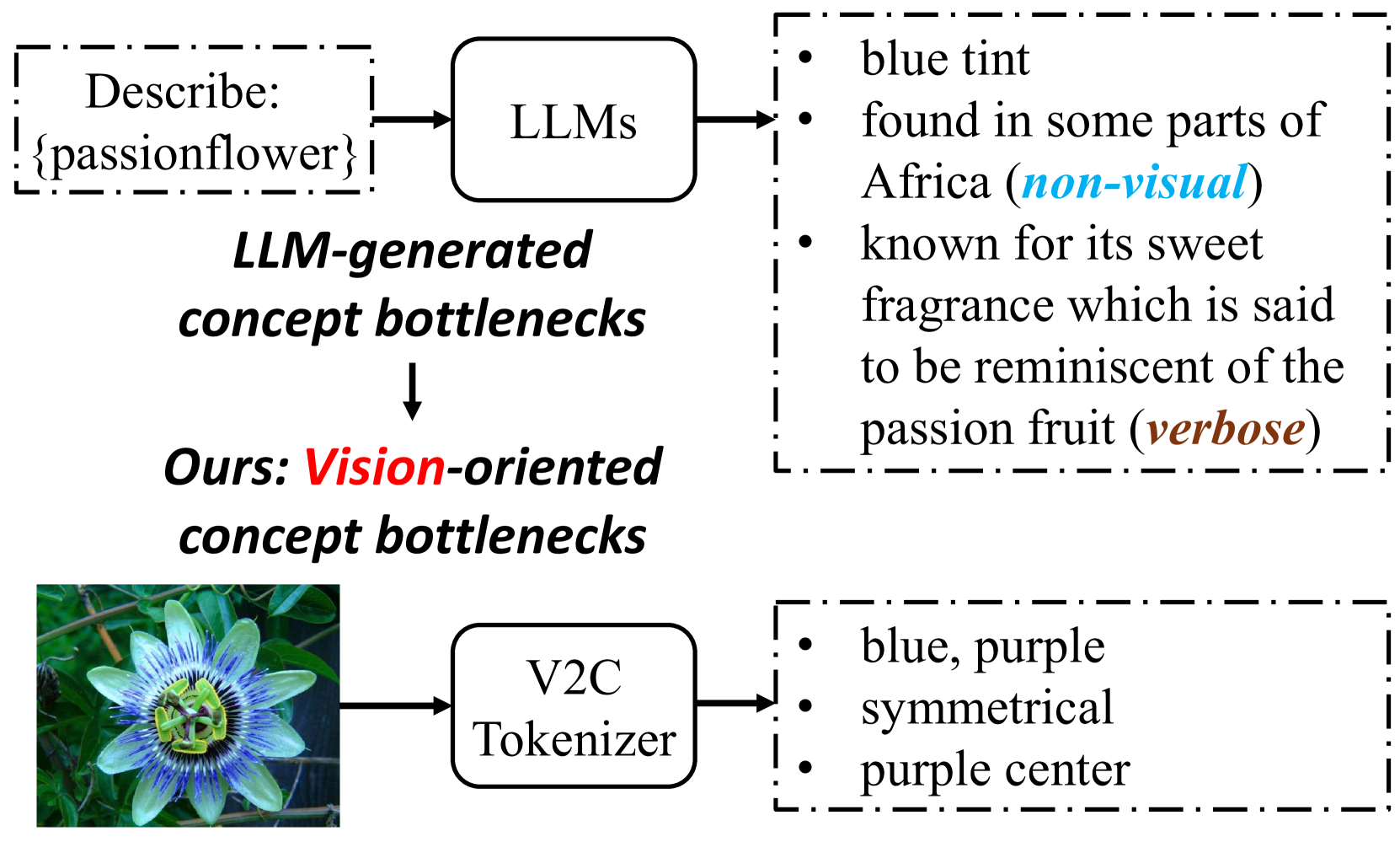
- 现有概念瓶颈模型依赖人工标注概念,成本高昂,且基于LLM的方法易引入非视觉属性,影响精度和可解释性。
- 论文提出V2C-CBM,通过视觉-概念Tokenizer将图像量化为视觉概念,构建面向视觉的概念瓶颈,避免引入非视觉信息。
- 实验表明,V2C-CBM在多个视觉分类基准测试中,性能匹配或超过LLM监督的CBM,验证了方法的有效性。
📝 摘要(中文)
概念瓶颈模型(CBMs)通过将图像转换为人类可理解的概念,然后对这些概念进行线性组合以进行分类,从而提供内在的可解释性。然而,视觉识别任务的概念标注需要大量的专家知识和劳动,限制了CBMs的广泛应用。最近的方法利用大型语言模型的知识来构建概念瓶颈,多模态模型(如CLIP)随后将图像特征映射到概念特征空间进行分类。尽管如此,语言模型产生的概念可能冗长,并可能引入非视觉属性,从而损害准确性和可解释性。本研究旨在避免这些问题,直接从多模态模型构建CBM。为此,我们采用常用词作为基本概念词汇,并利用辅助的未标记图像构建视觉-概念(V2C) tokenizer,它可以将图像显式量化为最相关的视觉概念,从而创建一个与多模态模型紧密集成的面向视觉的概念瓶颈。这促成了我们的V2C-CBM,它具有训练高效、可解释和高精度的特点。我们的V2C-CBM在各种视觉分类基准测试中匹配或优于LLM监督的CBM,验证了我们方法的有效性。
🔬 方法详解
问题定义:现有概念瓶颈模型(CBMs)依赖于人工标注的概念,这需要大量的专家知识和人工劳动,限制了其广泛应用。虽然一些方法尝试利用大型语言模型(LLMs)来生成概念,但这些概念可能包含冗余信息或非视觉属性,从而降低模型的准确性和可解释性。因此,如何高效且准确地构建概念瓶颈是当前CBMs面临的关键问题。
核心思路:论文的核心思路是直接从多模态模型中学习视觉概念,避免依赖人工标注或LLM生成。通过构建一个视觉-概念(V2C)Tokenizer,将图像量化为一组预定义的视觉概念。这种方法能够确保概念的视觉相关性,并减少冗余信息,从而提高模型的准确性和可解释性。
技术框架:V2C-CBM的整体框架包括以下几个主要模块:1) 图像编码器:使用预训练的多模态模型(如CLIP)提取图像特征。2) 视觉-概念Tokenizer:将图像特征量化为一组视觉概念。该Tokenizer基于可学习的码本,每个码本对应一个视觉概念。3) 概念瓶颈:将量化后的视觉概念作为模型的中间表示。4) 分类器:基于概念瓶颈进行分类预测。整个框架通过端到端的方式进行训练。
关键创新:该论文的关键创新在于提出了视觉-概念(V2C)Tokenizer,它能够将图像显式量化为最相关的视觉概念。与现有方法相比,V2C Tokenizer避免了人工标注的成本和LLM引入的非视觉属性,从而构建了一个更高效、更准确且更可解释的概念瓶颈。V2C Tokenizer与多模态模型紧密结合,能够更好地利用视觉信息。
关键设计:V2C Tokenizer的关键设计包括:1) 概念词汇的选择:使用常用词作为基本概念词汇,确保概念的通用性和可理解性。2) 码本学习:通过对比学习的方式,学习每个视觉概念对应的码本。3) 量化策略:使用Gumbel-Softmax技巧进行软量化,使得模型可以进行端到端训练。4) 损失函数:使用交叉熵损失函数进行分类,并添加正则化项,鼓励概念的稀疏性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,V2C-CBM在多个视觉分类基准测试中取得了优异的性能,例如在CUB数据集上,V2C-CBM的准确率与LLM监督的CBM相当甚至更高。此外,V2C-CBM具有更高的训练效率和更好的可解释性。消融实验验证了V2C Tokenizer的有效性,表明其能够有效地提取视觉概念。
🎯 应用场景
V2C-CBM可应用于各种需要可解释性的视觉分类任务,例如医疗图像诊断、自动驾驶场景理解、细粒度图像分类等。该方法能够提供模型决策的依据,增强用户对模型的信任,并有助于发现数据中的潜在模式。未来,该方法可以扩展到其他领域,例如视频理解和多模态学习。
📄 摘要(原文)
Concept Bottleneck Models (CBMs) offer inherent interpretability by initially translating images into human-comprehensible concepts, followed by a linear combination of these concepts for classification. However, the annotation of concepts for visual recognition tasks requires extensive expert knowledge and labor, constraining the broad adoption of CBMs. Recent approaches have leveraged the knowledge of large language models to construct concept bottlenecks, with multimodal models like CLIP subsequently mapping image features into the concept feature space for classification. Despite this, the concepts produced by language models can be verbose and may introduce non-visual attributes, which hurts accuracy and interpretability. In this study, we investigate to avoid these issues by constructing CBMs directly from multimodal models. To this end, we adopt common words as base concept vocabulary and leverage auxiliary unlabeled images to construct a Vision-to-Concept (V2C) tokenizer that can explicitly quantize images into their most relevant visual concepts, thus creating a vision-oriented concept bottleneck tightly coupled with the multimodal model. This leads to our V2C-CBM which is training efficient and interpretable with high accuracy. Our V2C-CBM has matched or outperformed LLM-supervised CBMs on various visual classification benchmarks, validating the efficacy of our approach.