Seeing with Partial Certainty: Conformal Prediction for Robotic Scene Recognition in Built Environments
作者: Yifan Xu, Vineet Kamat, Carol Menassa
分类: cs.CV
发布日期: 2025-01-09
备注: 10 pages, 4 Figures
💡 一句话要点
提出SwPC框架,利用Conformal Prediction提升VLM在机器人场景识别中的置信度与准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人场景识别 视觉语言模型 不确定性建模 Conformal Prediction 辅助机器人
📋 核心要点
- 辅助机器人需要在室内环境中进行精确的场景识别,但现有的视觉语言模型(VLM)容易产生幻觉预测,且人类指令可能模糊。
- SwPC框架通过Conformal Prediction理论来量化VLM的不确定性,使其在缺乏信心时能够识别并寻求帮助,从而提高识别的可靠性。
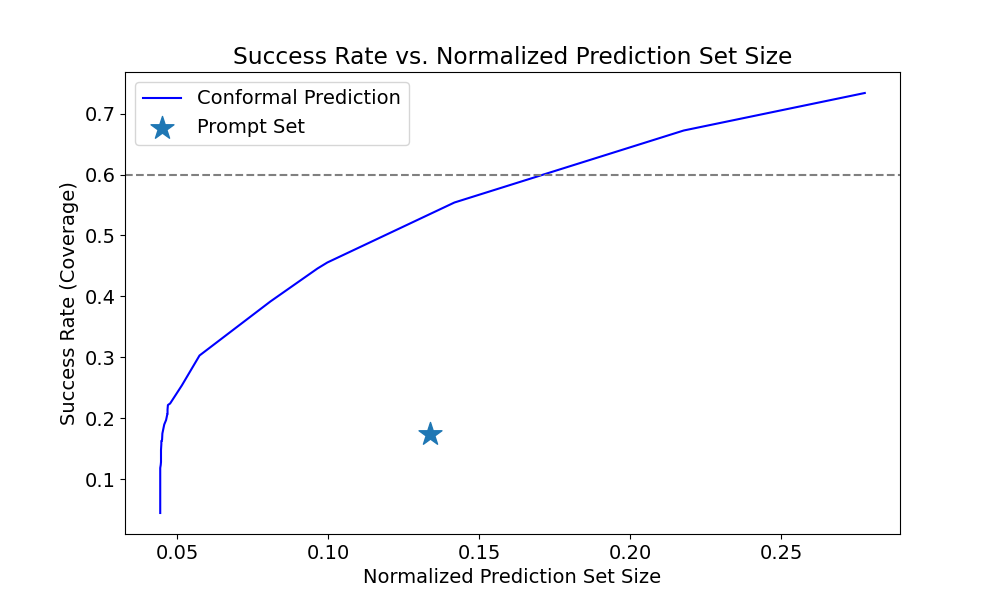
- 在Matterport3D数据集上的实验表明,SwPC显著提高了场景识别的成功率,并减少了对人工干预的需求,无需模型微调。
📝 摘要(中文)
本文提出了一种名为“Seeing with Partial Certainty (SwPC)”的框架,旨在衡量和调整基于视觉语言模型(VLM)的机器人场景识别中的不确定性,使模型能够在缺乏信心时识别出来并寻求帮助。该框架基于Conformal Prediction理论,在复杂的室内环境设置中,为场景识别提供统计保证,同时最大限度地减少对人工帮助的需求。通过在广泛使用的、具有丰富注释的场景数据集Matterport3D上的实验,结果表明,相对于现有技术,SwPC显著提高了成功率,并减少了所需的人工干预量。SwPC可以直接与任何VLM一起使用,无需模型微调,为不确定性建模提供了一种有前景的、轻量级的方法,可以补充和扩展基础模型的能力。
🔬 方法详解
问题定义:论文旨在解决辅助机器人场景识别中,视觉语言模型(VLM)由于幻觉预测和人类指令模糊导致的不确定性问题。现有方法缺乏对VLM置信度的有效评估,难以判断何时需要人工干预,导致识别错误或不必要的帮助请求。
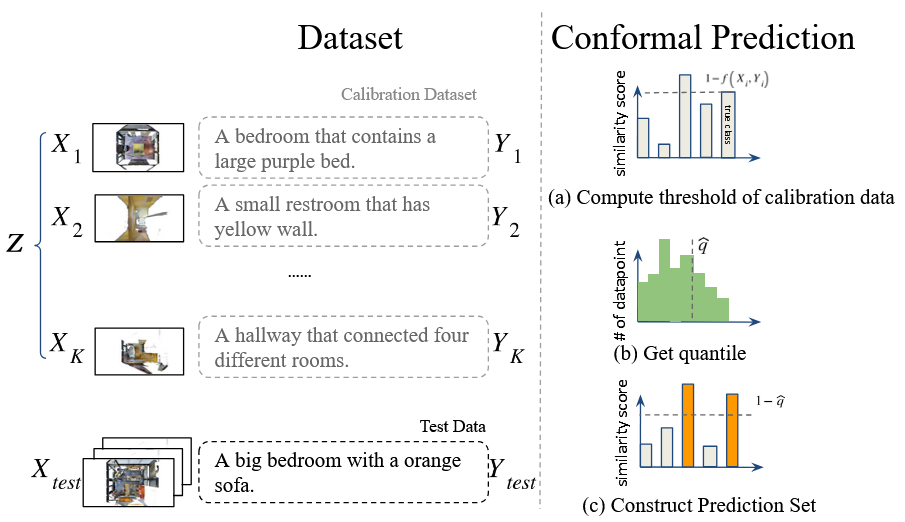
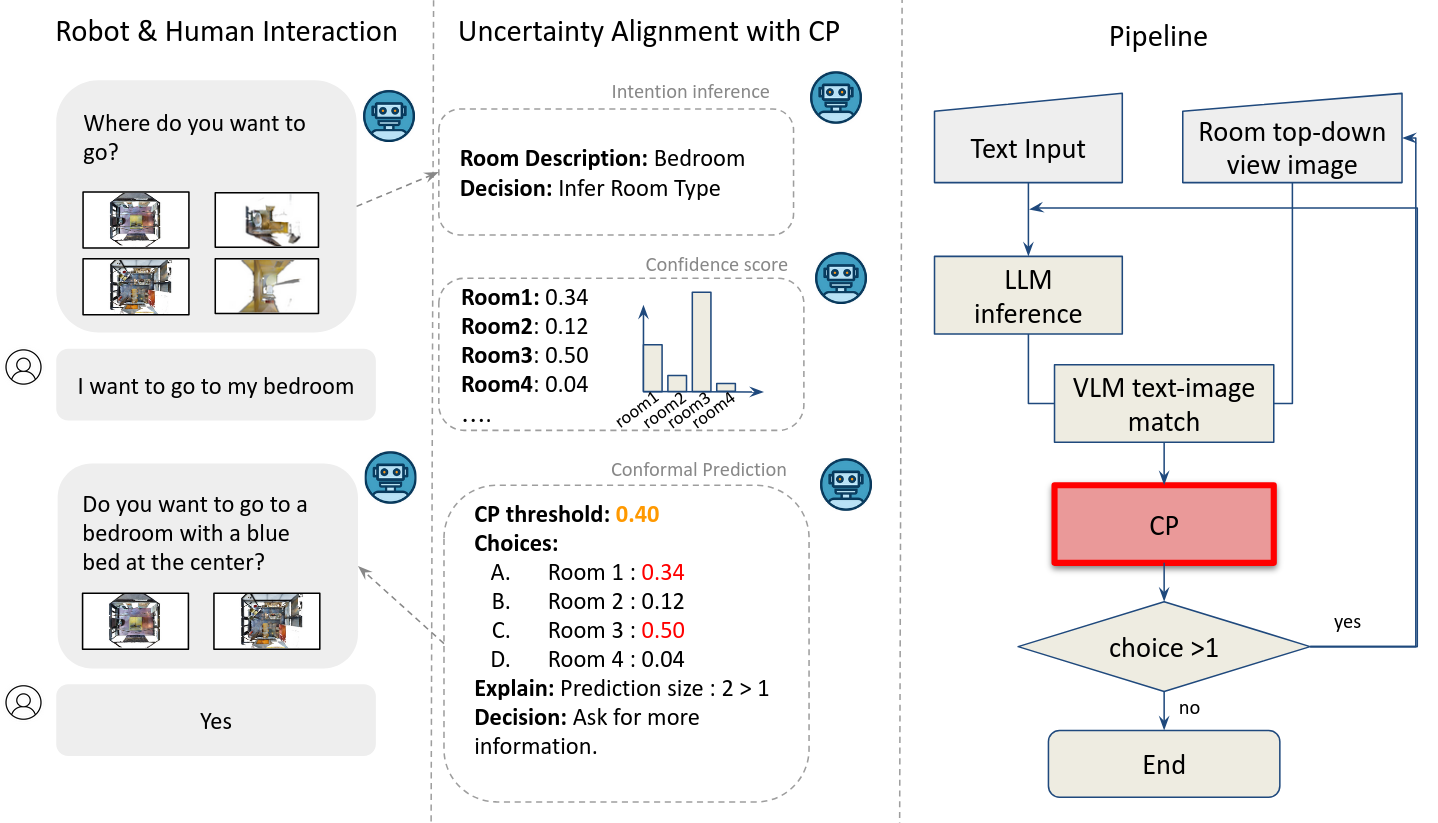
核心思路:论文的核心思路是利用Conformal Prediction理论,为VLM的场景识别结果提供统计保证。通过构建一个置信度集合,模型可以判断其预测结果是否足够可信。如果置信度较低,则表明模型不确定,需要寻求人工帮助。这种方法能够在保证识别准确率的同时,减少不必要的人工干预。
技术框架:SwPC框架主要包含以下几个阶段:1) VLM场景识别:使用VLM对输入图像进行场景识别,得到预测结果和相应的置信度分数。2) Conformal Prediction:利用Conformal Prediction方法,基于历史数据构建置信度集合,并计算当前预测结果的p-value。3) 不确定性评估:将p-value与预设的显著性水平进行比较,判断模型是否足够自信。如果p-value低于显著性水平,则认为模型不确定,需要人工干预。4) 人工辅助(可选):如果模型不确定,则请求人工帮助,获取正确的场景标签。
关键创新:SwPC的关键创新在于将Conformal Prediction理论应用于VLM的场景识别任务,从而能够量化模型的不确定性,并提供统计保证。与现有方法相比,SwPC无需对VLM进行微调,可以直接使用,具有轻量级和通用性的优点。此外,SwPC能够自适应地调整人工干预的频率,从而在保证识别准确率的同时,最大限度地减少对人工帮助的需求。
关键设计:SwPC的关键设计包括:1) 使用非参数的Conformal Prediction方法,避免对VLM的输出分布进行假设。2) 选择合适的显著性水平,以平衡识别准确率和人工干预的频率。3) 采用滑动窗口的方式更新置信度集合,以适应环境的变化。4) 使用Matterport3D数据集进行实验验证,该数据集包含丰富的室内场景注释,能够充分评估SwPC的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SwPC在Matterport3D数据集上显著提高了场景识别的成功率,并减少了所需的人工干预量。具体而言,相对于现有技术,SwPC在保持相同成功率的情况下,可以将人工干预的次数减少约20%-30%。此外,SwPC无需对VLM进行微调,可以直接使用,具有良好的通用性和可扩展性。
🎯 应用场景
该研究成果可应用于辅助机器人、智能家居、自动驾驶等领域。在辅助机器人领域,可以提高机器人在复杂室内环境中的导航和交互能力,为残疾人士提供更安全可靠的服务。在智能家居领域,可以提升智能设备的场景理解能力,实现更智能化的控制和管理。在自动驾驶领域,可以增强车辆对周围环境的感知能力,提高驾驶安全性。
📄 摘要(原文)
In assistive robotics serving people with disabilities (PWD), accurate place recognition in built environments is crucial to ensure that robots navigate and interact safely within diverse indoor spaces. Language interfaces, particularly those powered by Large Language Models (LLM) and Vision Language Models (VLM), hold significant promise in this context, as they can interpret visual scenes and correlate them with semantic information. However, such interfaces are also known for their hallucinated predictions. In addition, language instructions provided by humans can also be ambiguous and lack precise details about specific locations, objects, or actions, exacerbating the hallucination issue. In this work, we introduce Seeing with Partial Certainty (SwPC) - a framework designed to measure and align uncertainty in VLM-based place recognition, enabling the model to recognize when it lacks confidence and seek assistance when necessary. This framework is built on the theory of conformal prediction to provide statistical guarantees on place recognition while minimizing requests for human help in complex indoor environment settings. Through experiments on the widely used richly-annotated scene dataset Matterport3D, we show that SwPC significantly increases the success rate and decreases the amount of human intervention required relative to the prior art. SwPC can be utilized with any VLMs directly without requiring model fine-tuning, offering a promising, lightweight approach to uncertainty modeling that complements and scales alongside the expanding capabilities of foundational models.