Graph-Based Multimodal and Multi-view Alignment for Keystep Recognition
作者: Julia Lee Romero, Kyle Min, Subarna Tripathi, Morteza Karimzadeh
分类: cs.CV
发布日期: 2025-01-07
备注: 9 pages, 6 figures
💡 一句话要点
提出基于图学习的多模态多视角对齐框架,用于提升第一人称视角视频中的关键步骤识别精度。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 第一人称视角视频 关键步骤识别 图学习 多模态融合 多视角对齐 Ego-Exo4D 节点分类
📋 核心要点
- 第一人称视角视频因动态背景、频繁运动和遮挡,给准确的关键步骤识别带来挑战。
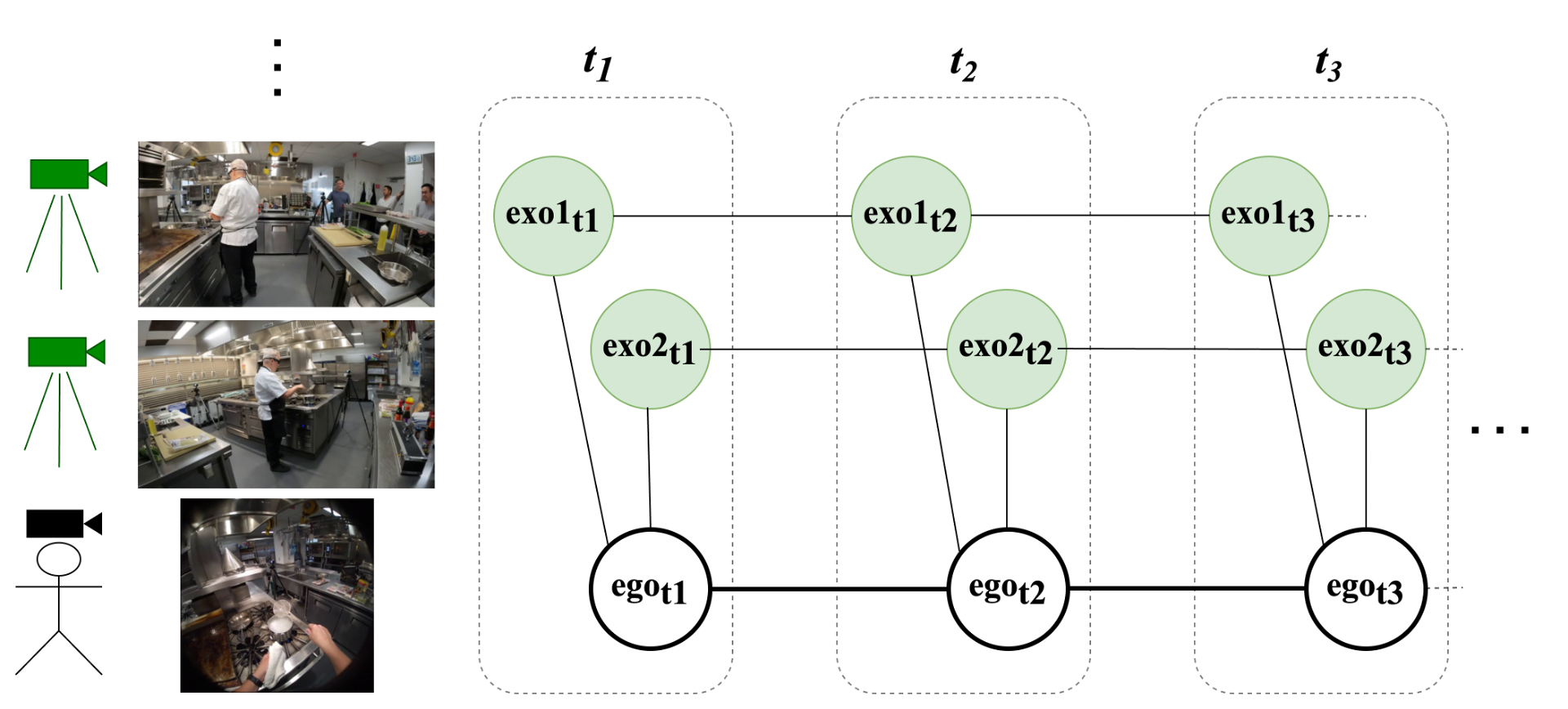
- 构建图结构,将视频片段作为节点,利用图学习建模长期依赖,并对齐第一人称和第三人称视角视频。
- 在 Ego-Exo4D 数据集上,该方法显著优于现有方法,准确率提升超过 12 个百分点,且计算高效。
📝 摘要(中文)
本研究提出了一种灵活的图学习框架,用于细粒度的关键步骤识别,旨在有效利用第一人称视角视频中的长期依赖关系,并在训练期间利用第一人称和第三人称视角视频之间的对齐来改进第一人称视角视频的推理。该方法构建了一个图,其中第一人称视角视频的每个视频片段对应一个节点。在训练期间,将每个第三人称视角视频的每个片段(如果可用)视为附加节点。研究探讨了定义这些节点之间连接的几种策略,并将关键步骤识别作为构建图上的节点分类任务。在 Ego-Exo4D 数据集上进行了大量实验,结果表明,所提出的基于图的灵活框架明显优于现有方法,准确率提高了 12 个百分点以上。此外,构建的图是稀疏且计算高效的。还进行了一项研究,探讨了在异构图上利用包括叙述、深度和对象类别标签在内的多种模态特征,并讨论了它们对关键步骤识别性能的相应贡献。
🔬 方法详解
问题定义:现有的关键步骤识别方法在处理第一人称视角视频时,由于动态背景、频繁运动和遮挡等因素,难以有效捕捉视频中的长期依赖关系,导致识别精度不高。此外,如何有效利用多视角信息(例如,同时利用第一人称和第三人称视角视频)也是一个挑战。
核心思路:论文的核心思路是将关键步骤识别问题转化为图上的节点分类问题。通过构建图结构,将视频片段作为节点,并利用图学习方法建模节点之间的关系,从而捕捉视频中的长期依赖关系。同时,通过在训练阶段引入第三人称视角视频,并将其与第一人称视角视频对齐,从而提升模型的泛化能力。
技术框架:该框架主要包含以下几个步骤:1) 视频片段提取:将第一人称视角视频分割成多个视频片段,每个片段对应一个节点。2) 图构建:根据一定的策略(例如,时间相邻、特征相似等)连接节点,构建图结构。在训练阶段,如果存在第三人称视角视频,则将其也分割成视频片段,并作为额外的节点添加到图中。3) 特征提取:提取每个节点的特征,例如,视觉特征、语音特征、深度特征等。4) 图学习:利用图神经网络(GNN)学习节点的表示,并进行节点分类,从而识别关键步骤。
关键创新:该论文的关键创新在于:1) 提出了一种基于图学习的框架,能够有效建模第一人称视角视频中的长期依赖关系。2) 提出了一种多视角对齐策略,能够利用第三人称视角视频的信息来提升第一人称视角视频的识别精度。3) 提出了一种灵活的图构建方法,能够根据不同的任务和数据选择合适的连接策略。
关键设计:在图构建方面,论文探讨了多种连接策略,例如,基于时间相邻的连接、基于特征相似度的连接等。在图学习方面,可以使用不同的图神经网络,例如,GCN、GAT 等。在损失函数方面,可以使用交叉熵损失函数或其他的节点分类损失函数。论文还探讨了如何融合多种模态的特征,例如,视觉特征、语音特征、深度特征等,并将其应用到异构图中。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在 Ego-Exo4D 数据集上取得了显著的性能提升,准确率超过现有方法 12 个百分点以上。这表明该方法能够有效利用第一人称视角视频中的长期依赖关系,并能够有效利用多视角信息来提升识别精度。此外,构建的图是稀疏且计算高效的,表明该方法具有良好的可扩展性。
🎯 应用场景
该研究成果可应用于智能助手、可穿戴设备、工业培训等领域。例如,在工业培训中,可以通过第一人称视角视频记录操作过程,并利用该方法识别关键步骤,从而为工人提供实时的指导和反馈。此外,该方法还可以应用于运动分析、医疗辅助等领域,具有广泛的应用前景。
📄 摘要(原文)
Egocentric videos capture scenes from a wearer's viewpoint, resulting in dynamic backgrounds, frequent motion, and occlusions, posing challenges to accurate keystep recognition. We propose a flexible graph-learning framework for fine-grained keystep recognition that is able to effectively leverage long-term dependencies in egocentric videos, and leverage alignment between egocentric and exocentric videos during training for improved inference on egocentric videos. Our approach consists of constructing a graph where each video clip of the egocentric video corresponds to a node. During training, we consider each clip of each exocentric video (if available) as additional nodes. We examine several strategies to define connections across these nodes and pose keystep recognition as a node classification task on the constructed graphs. We perform extensive experiments on the Ego-Exo4D dataset and show that our proposed flexible graph-based framework notably outperforms existing methods by more than 12 points in accuracy. Furthermore, the constructed graphs are sparse and compute efficient. We also present a study examining on harnessing several multimodal features, including narrations, depth, and object class labels, on a heterogeneous graph and discuss their corresponding contribution to the keystep recognition performance.