LargeAD: Large-Scale Cross-Sensor Data Pretraining for Autonomous Driving
作者: Lingdong Kong, Xiang Xu, Youquan Liu, Jun Cen, Runnan Chen, Wenwei Zhang, Liang Pan, Kai Chen, Ziwei Liu
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-01-07 (更新: 2025-12-03)
备注: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
DOI: 10.1109/TPAMI.2025.3617126
💡 一句话要点
LargeAD:面向自动驾驶的大规模跨传感器数据预训练框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 跨传感器数据 预训练 视觉基础模型 对比学习 多模态融合 LiDAR点云
📋 核心要点
- 现有方法在3D场景理解,尤其是在自动驾驶应用中,对视觉基础模型(VFMs)的潜力挖掘不足。
- LargeAD利用VFMs提取2D图像的语义超像素,与LiDAR点云对齐,通过对比学习增强跨模态语义一致性。
- 实验表明,LargeAD在LiDAR分割和目标检测上显著优于现有方法,并在多个数据集上验证了其性能。
📝 摘要(中文)
本文提出LargeAD,一个通用且可扩展的框架,用于在各种真实驾驶数据集上进行大规模3D预训练。该框架利用视觉基础模型(VFMs)从2D图像中提取富含语义的超像素,并将其与LiDAR点云对齐,以生成高质量的对比样本。这种对齐有助于跨模态表征学习,增强2D和3D数据之间的语义一致性。论文的关键创新包括:(i) VFM驱动的超像素生成,用于详细的语义表征;(ii) VFM辅助的对比学习策略,用于对齐多模态特征;(iii) 超点时间一致性,以保持跨时间的稳定表征;(iv) 多源数据预训练,以泛化到各种LiDAR配置。该方法在基于LiDAR的分割和目标检测的线性探测和微调方面取得了显著提升,在11个大规模多传感器数据集上的大量实验证明了其卓越性能,展示了在真实自动驾驶场景中的适应性、效率和鲁棒性。
🔬 方法详解
问题定义:现有方法在自动驾驶领域,特别是3D场景理解方面,对视觉基础模型(VFMs)的潜力挖掘不足。如何有效地利用大规模多传感器数据,提升3D感知的性能,是当前面临的挑战。现有方法难以充分利用2D图像的语义信息,并且在跨模态数据对齐方面存在局限性。
核心思路:LargeAD的核心思路是利用视觉基础模型(VFMs)从2D图像中提取富含语义的超像素,然后将这些超像素与LiDAR点云进行对齐,从而实现跨模态的语义信息融合。通过对比学习,增强2D和3D数据之间的语义一致性,提升3D场景理解的性能。这种设计能够充分利用2D图像的语义信息,并实现有效的跨模态数据对齐。
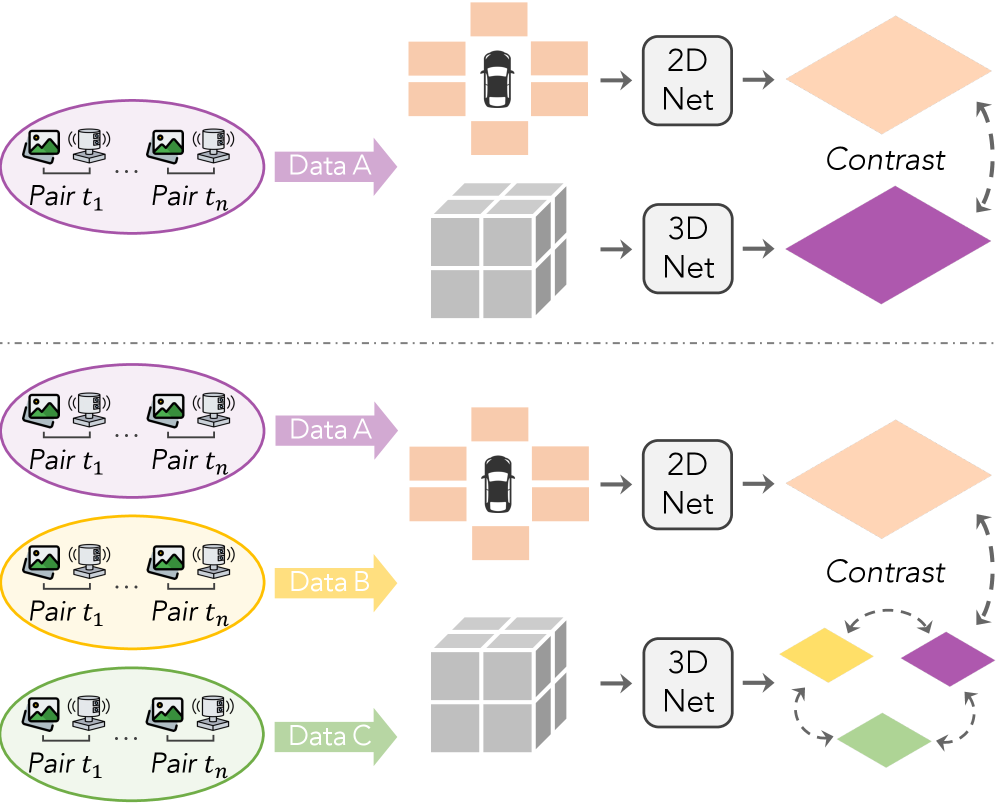
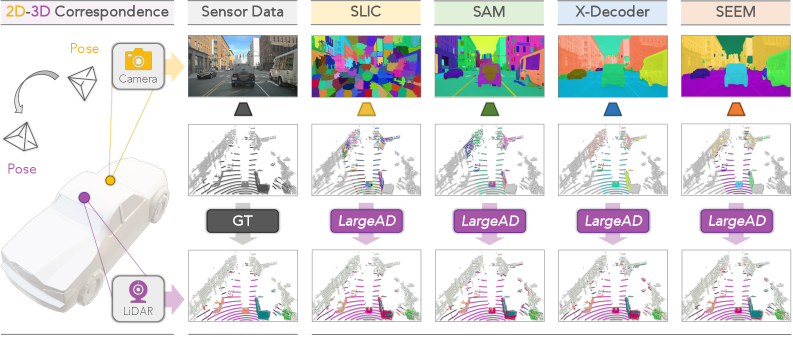
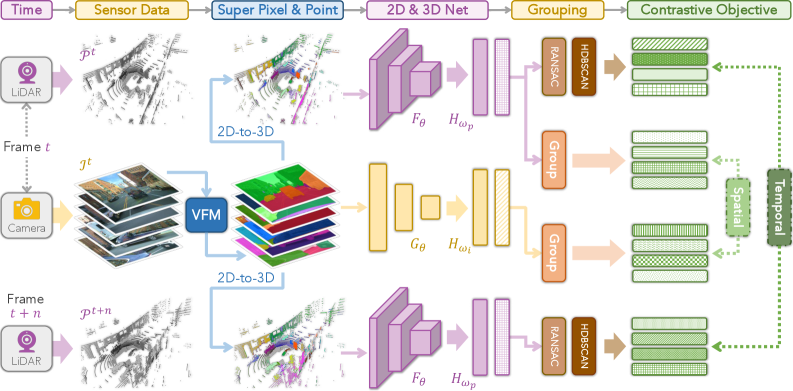
技术框架:LargeAD的整体框架包括以下几个主要模块:1) VFM驱动的超像素生成模块:利用视觉基础模型从2D图像中提取语义超像素。2) 跨模态对齐模块:将2D超像素与LiDAR点云进行对齐,生成对比学习的样本。3) 对比学习模块:利用VFM辅助的对比学习策略,对齐多模态特征。4) 时间一致性模块:维护超点的时间一致性,保证表征的稳定性。5) 多源数据预训练模块:利用多源数据进行预训练,提升模型的泛化能力。
关键创新:LargeAD的关键创新在于:1) 提出了VFM驱动的超像素生成方法,能够提取更详细的语义信息。2) 提出了VFM辅助的对比学习策略,能够更有效地对齐多模态特征。3) 引入了超点时间一致性,保证了表征的稳定性。4) 采用了多源数据预训练,提升了模型的泛化能力。与现有方法相比,LargeAD能够更充分地利用2D图像的语义信息,并实现更有效的跨模态数据对齐。
关键设计:在VFM驱动的超像素生成模块中,使用了预训练的视觉基础模型,例如DINO或CLIP,来提取图像特征。在对比学习模块中,采用了InfoNCE损失函数,用于最大化正样本之间的相似性,最小化负样本之间的相似性。在时间一致性模块中,使用了卡尔曼滤波等方法,用于平滑超点的位置和特征。在多源数据预训练模块中,使用了来自不同数据集的LiDAR点云和图像数据,以提升模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
LargeAD在11个大规模多传感器数据集上进行了广泛的实验,结果表明,该方法在LiDAR分割和目标检测任务上取得了显著的性能提升。例如,在nuScenes数据集上,LargeAD在分割任务上的mIoU指标提升了超过5个百分点,在目标检测任务上的mAP指标提升了超过3个百分点。这些结果充分证明了LargeAD的有效性和优越性。
🎯 应用场景
LargeAD的研究成果可广泛应用于自动驾驶领域,例如环境感知、目标检测、语义分割等任务。该框架能够提升自动驾驶系统对复杂场景的理解能力,提高驾驶安全性。此外,该方法还可以应用于机器人导航、三维重建等领域,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Recent advancements in vision foundation models (VFMs) have revolutionized visual perception in 2D, yet their potential for 3D scene understanding, particularly in autonomous driving applications, remains underexplored. In this paper, we introduce LargeAD, a versatile and scalable framework designed for large-scale 3D pretraining across diverse real-world driving datasets. Our framework leverages VFMs to extract semantically rich superpixels from 2D images, which are aligned with LiDAR point clouds to generate high-quality contrastive samples. This alignment facilitates cross-modal representation learning, enhancing the semantic consistency between 2D and 3D data. We introduce several key innovations: (i) VFM-driven superpixel generation for detailed semantic representation, (ii) a VFM-assisted contrastive learning strategy to align multimodal features, (iii) superpoint temporal consistency to maintain stable representations across time, and (iv) multi-source data pretraining to generalize across various LiDAR configurations. Our approach achieves substantial gains over state-of-the-art methods in linear probing and fine-tuning for LiDAR-based segmentation and object detection. Extensive experiments on 11 large-scale multi-sensor datasets highlight our superior performance, demonstrating adaptability, efficiency, and robustness in real-world autonomous driving scenarios.