Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
作者: Haobo Yuan, Xiangtai Li, Tao Zhang, Yueyi Sun, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, Ming-Hsuan Yang
分类: cs.CV
发布日期: 2025-01-07 (更新: 2025-11-03)
备注: Code: https://github.com/Bytedance/Sa2VA
💡 一句话要点
Sa2VA:融合SAM2与LLaVA,实现图像和视频的密集型Grounded理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 图像理解 指代分割 大型语言模型 视觉语言模型 Grounded理解
📋 核心要点
- 现有多模态大语言模型在处理图像和视频任务时,往往受限于特定模态和任务,缺乏通用性。
- Sa2VA 融合 SAM-2 和 MLLM,将文本、图像和视频统一到 LLM 令牌空间,实现跨模态的Grounded理解。
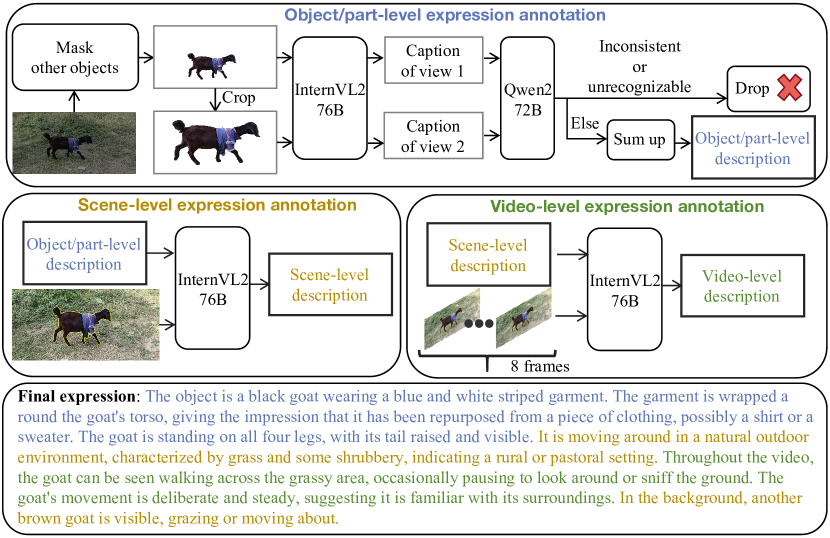
- Sa2VA 在指代视频对象分割等任务上表现出色,并提出了包含72k对象表达式的Ref-SAV数据集。
📝 摘要(中文)
本文提出了Sa2VA,这是首个用于图像和视频密集型Grounded理解的综合统一模型。与现有的多模态大型语言模型不同,Sa2VA 不仅限于特定的模态和任务,它支持广泛的图像和视频任务,包括指代分割和对话,只需最少的单样本指令微调。Sa2VA 结合了基础视频分割模型 SAM-2 和先进的视觉语言模型 MLLM,并将文本、图像和视频统一到一个共享的 LLM 令牌空间中。Sa2VA 使用 LLM 生成指令令牌,指导 SAM-2 生成精确的掩码,从而实现对静态和动态视觉内容的Grounded多模态理解。此外,我们还引入了 Ref-SAV,这是一个自动标注的数据集,包含复杂视频场景中超过 72k 个对象表达式,旨在提高模型性能。我们还手动验证了 Ref-SAV 数据集中 2k 个视频对象,以评估复杂环境中指代视频对象分割的性能。实验表明,Sa2VA 在多个任务中都取得了强大的性能,尤其是在指代视频对象分割方面,突显了其在复杂现实世界应用中的潜力。此外,Sa2VA 可以轻松扩展到各种 VLM 中,包括 Qwen-VL 和 Intern-VL,这些 VLM 可以通过当前开源 VLM 的快速流程进行更新。代码和模型已提供给社区。
🔬 方法详解
问题定义:现有的大型多模态模型在处理图像和视频时,通常针对特定任务设计,缺乏通用性和泛化能力。它们难以同时处理多种模态的信息,并且在理解视觉内容时缺乏精确的定位能力,尤其是在复杂的视频场景中。
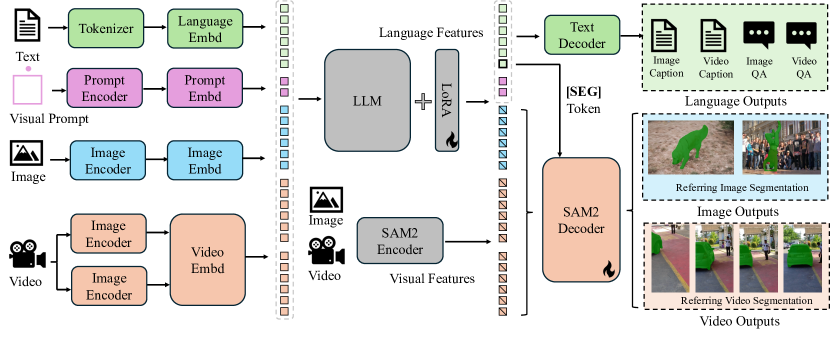
核心思路:Sa2VA 的核心思路是将视频分割模型 SAM-2 与视觉语言模型 LLaVA 结合,利用 LLaVA 的语言理解能力生成指令,指导 SAM-2 进行精确的视频对象分割。通过将不同模态的信息映射到共享的 LLM 令牌空间,实现跨模态的统一理解。
技术框架:Sa2VA 的整体框架包括以下几个主要模块:1) 视觉编码器:用于提取图像和视频的视觉特征。2) 语言模型 (LLM):用于处理文本指令,并生成指导 SAM-2 分割的指令令牌。3) 视频分割模型 (SAM-2):根据 LLM 生成的指令令牌,对视频中的对象进行分割。4) 跨模态对齐模块:用于将视觉特征和语言特征映射到共享的 LLM 令牌空间。整个流程是,首先将图像或视频输入视觉编码器,提取视觉特征;然后,将文本指令输入 LLM,生成指令令牌;最后,SAM-2 根据指令令牌对视觉特征进行分割,得到分割结果。
关键创新:Sa2VA 的关键创新在于将视频分割模型 SAM-2 与视觉语言模型 LLaVA 结合,实现了对图像和视频的密集型Grounded理解。与现有方法相比,Sa2VA 能够同时处理多种模态的信息,并且在理解视觉内容时具有更强的定位能力。此外,Sa2VA 还提出了一个自动标注的数据集 Ref-SAV,用于提高模型在复杂视频场景中的性能。
关键设计:Sa2VA 的关键设计包括:1) 使用 LLM 生成指令令牌,指导 SAM-2 进行分割。2) 将不同模态的信息映射到共享的 LLM 令牌空间。3) 提出了一个自动标注的数据集 Ref-SAV,用于提高模型在复杂视频场景中的性能。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Sa2VA 在指代视频对象分割任务上取得了显著的性能提升。论文中提到,Sa2VA 在 Ref-SAV 数据集上进行了实验,并与现有方法进行了比较。具体的性能数据和提升幅度在摘要中没有明确给出,属于未知信息。但论文强调 Sa2VA 在该任务上的表现优于其他方法,突显了其在复杂现实世界应用中的潜力。
🎯 应用场景
Sa2VA 在视频监控、自动驾驶、智能家居、医疗影像分析等领域具有广泛的应用前景。例如,在视频监控中,Sa2VA 可以用于自动识别和跟踪特定对象;在自动驾驶中,Sa2VA 可以用于理解交通场景,识别行人、车辆等;在医疗影像分析中,Sa2VA 可以用于辅助医生诊断疾病。Sa2VA 的出现将推动多模态理解技术的发展,为人工智能在各个领域的应用提供更强大的支持。
📄 摘要(原文)
This work presents Sa2VA, the first comprehensive, unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with MLLM, the advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves strong performance across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications. In addition, Sa2VA can be easily extended into various VLMs, including Qwen-VL and Intern-VL, which can be updated with rapid process in current open-sourced VLMs. Code and models have been provided to the community.