Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control
作者: Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, Yuan Liu
分类: cs.CV, cs.AI, cs.GR
发布日期: 2025-01-07 (更新: 2025-01-09)
备注: Project page: https://igl-hkust.github.io/das/ Codes: https://github.com/IGL-HKUST/DiffusionAsShader
💡 一句话要点
DaS:利用3D感知视频扩散模型实现多功能视频生成控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视频生成 扩散模型 3D感知 视频控制 时间一致性
📋 核心要点
- 现有视频生成方法缺乏对相机、内容等多种因素的精确控制,限制了其应用范围。
- DaS利用3D跟踪视频作为控制信号,使扩散模型具备3D感知能力,从而实现对视频生成过程的灵活控制。
- DaS仅需少量数据和计算资源,即可在多种视频控制任务上展现出强大的性能,并显著提升时间一致性。
📝 摘要(中文)
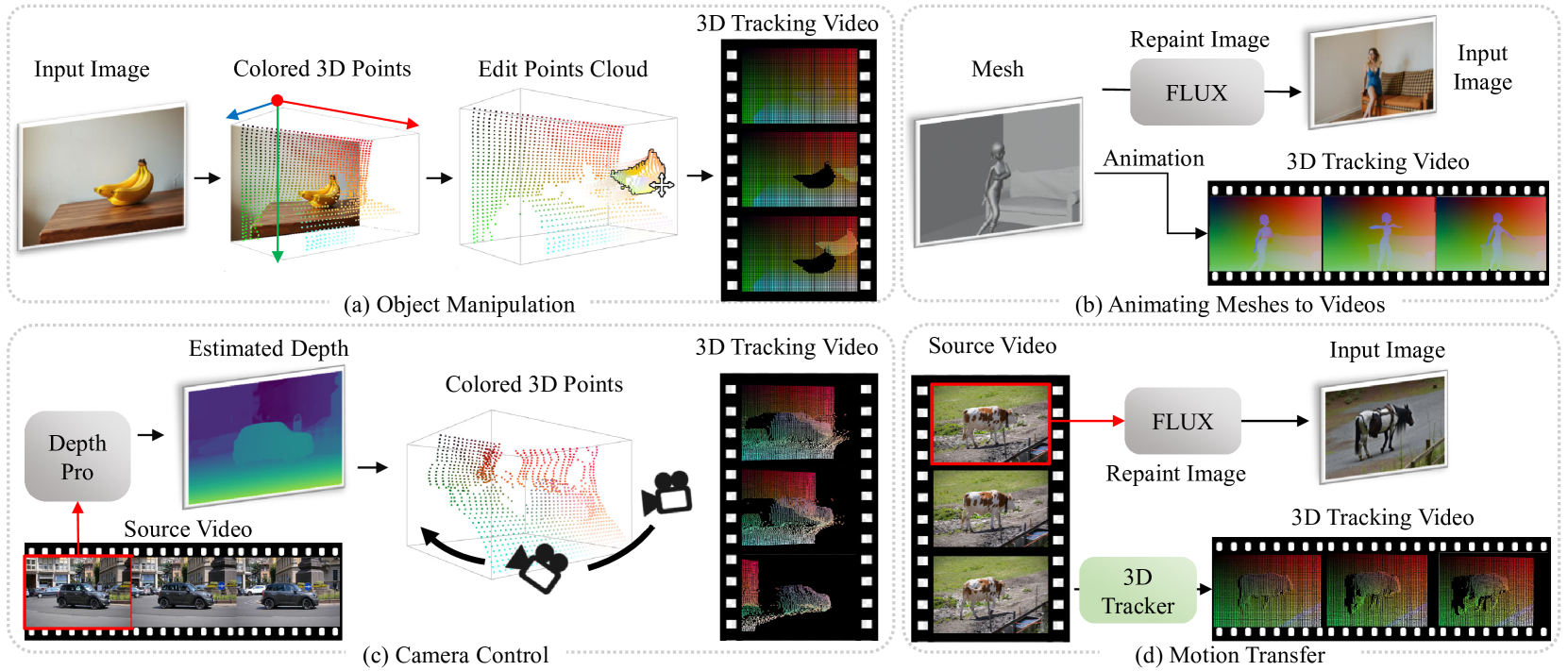
扩散模型在从文本提示或图像生成高质量视频方面表现出了令人印象深刻的性能。然而,对视频生成过程的精确控制,例如相机操作或内容编辑,仍然是一个重大挑战。现有的受控视频生成方法通常仅限于单一控制类型,缺乏处理多样化控制需求的灵活性。本文介绍了一种名为Diffusion as Shader (DaS) 的新方法,该方法在统一架构中支持多种视频控制任务。我们的核心思想是,实现多功能视频控制需要利用 3D 控制信号,因为视频本质上是动态 3D 内容的 2D 渲染。与先前仅限于 2D 控制信号的方法不同,DaS 利用 3D 跟踪视频作为控制输入,使视频扩散过程本质上具有 3D 感知能力。这种创新使 DaS 能够通过简单地操纵 3D 跟踪视频来实现广泛的视频控制。使用 3D 跟踪视频的另一个优点是它们能够有效地链接帧,从而显着增强生成视频的时间一致性。仅使用 8 个 H800 GPU 并在不到 1 万个视频上进行 3 天的微调,DaS 在各种任务(包括网格到视频生成、相机控制、运动传递和对象操作)中展示了强大的控制能力。
🔬 方法详解
问题定义:现有的视频生成方法通常只能处理单一类型的控制信号,例如文本或图像,无法同时控制相机运动、物体姿态等多个方面。此外,这些方法在生成长视频时容易出现时间不一致性问题,影响视频质量。
核心思路:DaS的核心思路是将视频生成过程视为对动态3D场景的渲染。通过引入3D跟踪视频作为控制信号,模型可以学习到3D场景的几何信息和运动规律,从而实现对视频内容和相机运动的精确控制。这种3D感知的扩散过程能够更好地保证生成视频的时间一致性。
技术框架:DaS的整体框架基于扩散模型,并引入了一个3D控制模块。该模块接收3D跟踪视频作为输入,提取出3D场景的特征表示。然后,这些特征表示被注入到扩散模型的去噪过程中,引导模型生成符合3D控制信号的视频。整个框架可以分为三个主要阶段:3D跟踪视频预处理、特征提取和扩散模型去噪。
关键创新:DaS最重要的创新点在于将3D跟踪视频作为控制信号引入到视频扩散模型中。与传统的2D控制信号相比,3D跟踪视频能够提供更丰富的场景几何信息和运动信息,从而实现更精确的视频控制。此外,DaS的设计使得模型能够同时处理多种控制任务,例如相机控制、物体操作和运动传递。
关键设计:DaS使用预训练的3D人体姿态估计模型来获取3D跟踪视频。为了更好地利用3D信息,DaS设计了一个3D特征提取器,该提取器由多个3D卷积层组成。在扩散模型的去噪过程中,DaS使用Cross-Attention机制将3D特征注入到UNet结构的中间层。损失函数主要包括L1损失和感知损失,以保证生成视频的质量和真实感。
🖼️ 关键图片


📊 实验亮点
DaS在多个视频控制任务上取得了显著的成果。例如,在相机控制任务中,DaS能够生成具有平滑相机运动和逼真场景变化的视频。在运动传递任务中,DaS能够将一个角色的运动风格迁移到另一个角色上,生成具有自然运动效果的视频。实验结果表明,DaS在视频质量和控制精度方面均优于现有的方法。
🎯 应用场景
DaS具有广泛的应用前景,例如虚拟现实内容创作、电影特效制作、游戏开发和机器人控制等。它可以帮助用户轻松地创建具有精确控制和高度真实感的视频内容,并为各种应用场景提供强大的视频生成工具。未来,DaS有望成为视频内容创作领域的重要技术。
📄 摘要(原文)
Diffusion models have demonstrated impressive performance in generating high-quality videos from text prompts or images. However, precise control over the video generation process, such as camera manipulation or content editing, remains a significant challenge. Existing methods for controlled video generation are typically limited to a single control type, lacking the flexibility to handle diverse control demands. In this paper, we introduce Diffusion as Shader (DaS), a novel approach that supports multiple video control tasks within a unified architecture. Our key insight is that achieving versatile video control necessitates leveraging 3D control signals, as videos are fundamentally 2D renderings of dynamic 3D content. Unlike prior methods limited to 2D control signals, DaS leverages 3D tracking videos as control inputs, making the video diffusion process inherently 3D-aware. This innovation allows DaS to achieve a wide range of video controls by simply manipulating the 3D tracking videos. A further advantage of using 3D tracking videos is their ability to effectively link frames, significantly enhancing the temporal consistency of the generated videos. With just 3 days of fine-tuning on 8 H800 GPUs using less than 10k videos, DaS demonstrates strong control capabilities across diverse tasks, including mesh-to-video generation, camera control, motion transfer, and object manipulation.