Bridged Semantic Alignment for Zero-shot 3D Medical Image Diagnosis
作者: Haoran Lai, Zihang Jiang, Qingsong Yao, Rongsheng Wang, Zhiyang He, Xiaodong Tao, Weifu Lv, Wei Wei, S. Kevin Zhou
分类: cs.CV
发布日期: 2025-01-07 (更新: 2025-11-11)
💡 一句话要点
提出桥接语义对齐框架BrgSA,用于零样本3D医学图像诊断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 3D医学图像诊断 视觉-语言对齐 跨模态知识交互 语义桥接
📋 核心要点
- 现有VLA方法在3D医学图像零样本诊断中,视觉和文本嵌入存在较大语义鸿沟,阻碍了有效对齐。
- 提出BrgSA框架,利用大型语言模型提取报告语义信息,并设计跨模态知识交互模块弥合模态差距。
- 在多个数据集上验证,BrgSA在零样本诊断,特别是代表性不足异常的诊断上,显著优于现有方法。
📝 摘要(中文)
三维医学图像,如计算机断层扫描,在临床实践中应用广泛,为自动诊断提供了巨大潜力。基于监督学习的方法取得了显著进展,但严重依赖于大量的手动标注,受限于训练数据的可用性和异常类型的多样性。视觉-语言对齐(VLA)提供了一种有前景的替代方案,通过实现零样本学习而无需额外的标注。然而,我们通过实验发现,现有VLA方法在对齐后,视觉和文本嵌入形成两个分离良好的簇,存在较大的差距需要弥合。为了弥合这一差距,我们提出了一个桥接语义对齐(BrgSA)框架。首先,我们利用大型语言模型对报告进行语义总结,提取高层次的语义信息。其次,我们设计了一个跨模态知识交互模块,该模块利用跨模态知识库作为语义桥梁,促进两种模态之间的交互,缩小差距,并改善它们的对齐。为了全面评估我们的方法,我们构建了一个包含15个代表性不足的异常的基准数据集,并使用了两个现有的基准数据集。实验结果表明,BrgSA在公共基准数据集和我们自定义标注的数据集上都取得了最先进的性能,在代表性不足的异常的零样本诊断方面有显著的改进。
🔬 方法详解
问题定义:现有基于监督学习的3D医学图像诊断方法依赖大量标注数据,难以泛化到未见过的或罕见病症。视觉-语言对齐(VLA)为零样本学习提供可能,但直接应用VLA时,视觉和文本特征空间存在较大语义鸿沟,导致对齐效果不佳,诊断精度受限。
核心思路:核心在于弥合视觉和文本模态之间的语义鸿沟。通过引入外部知识,将视觉和文本特征映射到更接近的语义空间,从而提升对齐效果。具体而言,利用大型语言模型(LLM)提取报告中的高层语义信息,并构建跨模态知识库,作为连接视觉和文本模态的桥梁。
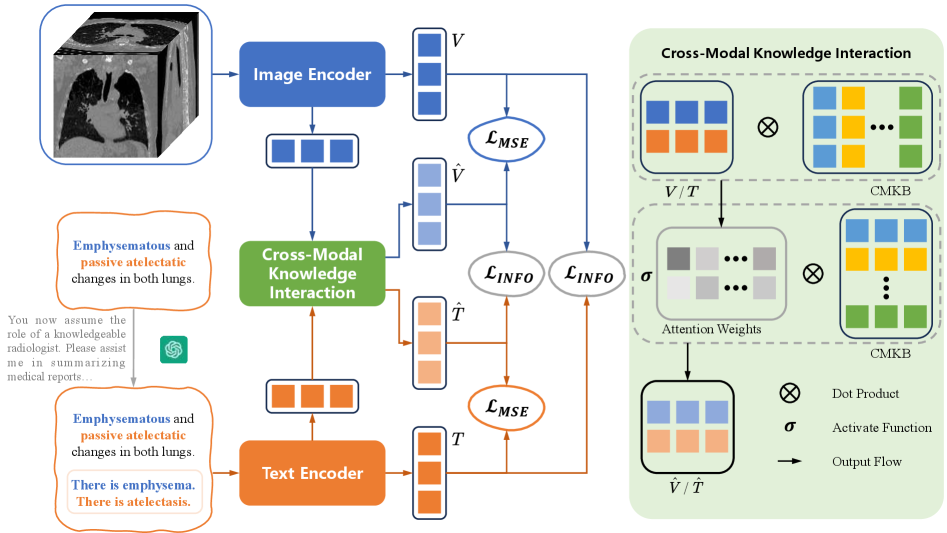
技术框架:BrgSA框架主要包含三个模块:1) 语义总结模块:利用LLM对医学报告进行语义总结,提取关键的语义信息。2) 跨模态知识交互模块:构建跨模态知识库,并利用该知识库促进视觉和文本模态之间的交互,缩小模态差距。3) 对齐模块:将视觉和文本特征对齐到共享的语义空间,用于零样本诊断。
关键创新:关键创新在于跨模态知识交互模块的设计。该模块通过构建跨模态知识库,显式地建模了视觉和文本模态之间的关系,从而有效地弥合了模态差距。与直接对齐视觉和文本特征的方法相比,该方法能够更好地利用医学报告中的语义信息,提升零样本诊断的准确性。
关键设计:跨模态知识库的构建是关键设计之一。知识库包含医学概念及其对应的视觉和文本表示。具体实现中,可以使用预训练的视觉和语言模型提取视觉和文本特征,并使用对比学习方法训练知识库,使得相关的视觉和文本表示在特征空间中更加接近。此外,损失函数的设计也至关重要,需要同时考虑对齐损失和知识库的约束损失。
🖼️ 关键图片


📊 实验亮点
BrgSA在三个基准数据集上均取得了SOTA性能。在自定义数据集上,针对15种代表性不足的异常,BrgSA的零样本诊断性能显著优于现有方法,证明了其在罕见病诊断方面的优势。实验结果表明,所提出的跨模态知识交互模块能够有效弥合视觉和文本模态之间的语义鸿沟,提升对齐效果。
🎯 应用场景
该研究成果可应用于多种3D医学图像的自动诊断,尤其是在缺乏标注数据的罕见疾病诊断方面。有助于提升诊断效率和准确性,减轻医生负担,并为患者提供更及时有效的治疗方案。未来可扩展到其他医学影像模态和疾病类型,具有广阔的应用前景。
📄 摘要(原文)
3D medical images such as computed tomography are widely used in clinical practice, offering a great potential for automatic diagnosis. Supervised learning-based approaches have achieved significant progress but rely heavily on extensive manual annotations, limited by the availability of training data and the diversity of abnormality types. Vision-language alignment (VLA) offers a promising alternative by enabling zero-shot learning without additional annotations. However, we empirically discover that the visual and textural embeddings after alignment endeavors from existing VLA methods form two well-separated clusters, presenting a wide gap to be bridged. To bridge this gap, we propose a Bridged Semantic Alignment (BrgSA) framework. First, we utilize a large language model to perform semantic summarization of reports, extracting high-level semantic information. Second, we design a Cross-Modal Knowledge Interaction module that leverages a cross-modal knowledge bank as a semantic bridge, facilitating interaction between the two modalities, narrowing the gap, and improving their alignment. To comprehensively evaluate our method, we construct a benchmark dataset that includes 15 underrepresented abnormalities as well as utilize two existing benchmark datasets. Experimental results demonstrate that BrgSA achieves state-of-the-art performances on both public benchmark datasets and our custom-labeled dataset, with significant improvements in zero-shot diagnosis of underrepresented abnormalities.