Human Gaze Boosts Object-Centered Representation Learning
作者: Timothy Schaumlöffel, Arthur Aubret, Gemma Roig, Jochen Triesch
分类: cs.CV, cs.LG
发布日期: 2025-01-06
备注: 13 pages
💡 一句话要点
提出基于人类注视机制的物体中心表征学习方法,提升自监督学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 自我中心视觉 自监督学习 人类注视预测 物体中心表征 生物启发式学习
📋 核心要点
- 现有自监督学习模型在处理自我中心视觉数据时,忽略了人类视觉系统对中心区域的关注,导致性能不佳。
- 该论文提出了一种模拟人类注视行为的方法,通过裁剪注视点周围的区域来模拟中心视觉,并用其训练自监督学习模型。
- 实验结果表明,该方法能够提升模型学习到的物体中心表征的质量,验证了中心视觉对视觉表征学习的重要性。
📝 摘要(中文)
与人类相比,最近在类人自我中心视觉输入上训练的自监督学习(SSL)模型在图像识别任务上的表现明显不足。这些模型在从头戴式相机收集的原始、均匀的视觉输入上进行训练。这与人类不同,因为视网膜和视觉皮层的解剖结构相对地放大了中心视觉信息,即人类注视位置周围的信息。人类的这种选择性放大可能有助于形成以物体为中心的视觉表征。本文研究了关注中心视觉信息是否能促进自我中心视觉物体学习。使用大规模Ego4D数据集模拟了5个月的自我中心视觉体验,并使用人类注视预测模型生成注视位置。为了考虑中心视觉在人类中的重要性,裁剪了注视位置周围的视觉区域。最后,在这些修改后的输入上训练了一个基于时间的SSL模型。实验表明,关注中心视觉能够产生更好的以物体为中心的表征。分析表明,SSL模型利用注视运动的时间动态来构建更强的视觉表征。总的来说,这项工作标志着在生物启发式视觉表征学习方面迈出了重要一步。
🔬 方法详解
问题定义:现有自监督学习方法在处理第一人称视角数据时,直接使用原始图像,忽略了人类视觉系统对中心区域(即注视点附近)的偏好。这种均匀处理方式导致模型难以学习到有效的、以物体为中心的视觉表征,从而影响了下游任务的性能。现有方法没有充分利用人类视觉系统的信息处理机制。
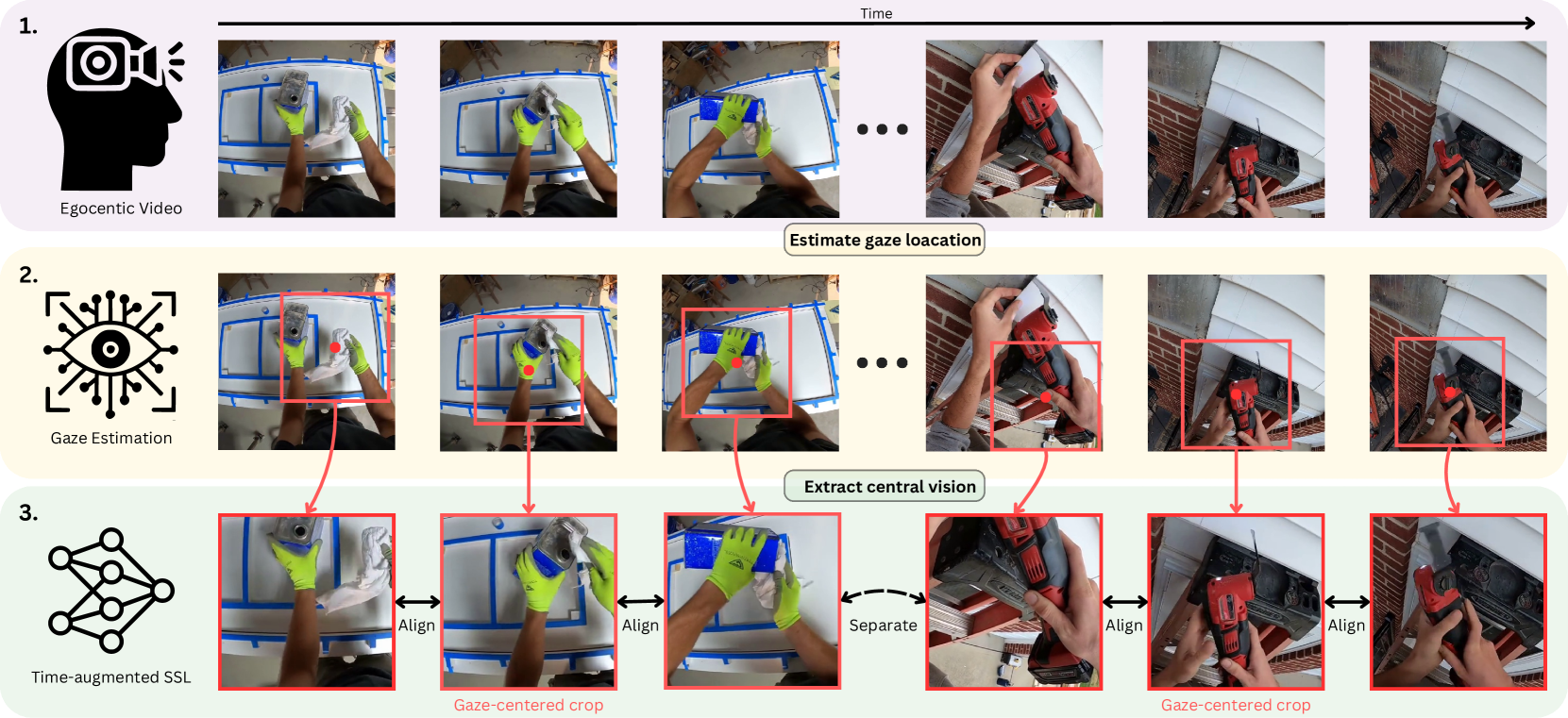
核心思路:该论文的核心思路是模拟人类的注视行为,通过裁剪图像中注视点周围的区域,模拟人类视觉系统对中心视觉信息的选择性放大。通过这种方式,模型可以更加关注图像中与注视点相关的物体,从而学习到更好的物体中心表征。这种方法借鉴了生物视觉的特性,旨在提升自监督学习模型的性能。
技术框架:整体框架包括以下几个主要步骤:1) 使用Ego4D数据集模拟自我中心视觉体验;2) 使用人类注视预测模型预测每一帧图像的注视位置;3) 根据预测的注视位置,裁剪图像中注视点周围的区域,作为模型的输入;4) 使用裁剪后的图像训练一个基于时间的自监督学习模型。该框架的核心在于模拟人类注视行为,并将其融入到自监督学习过程中。
关键创新:该论文的关键创新在于将人类注视机制引入到自监督学习中。通过模拟人类视觉系统对中心视觉信息的选择性放大,该方法能够提升模型学习到的物体中心表征的质量。与现有方法相比,该方法更加注重生物启发,能够更好地利用人类视觉系统的先验知识。
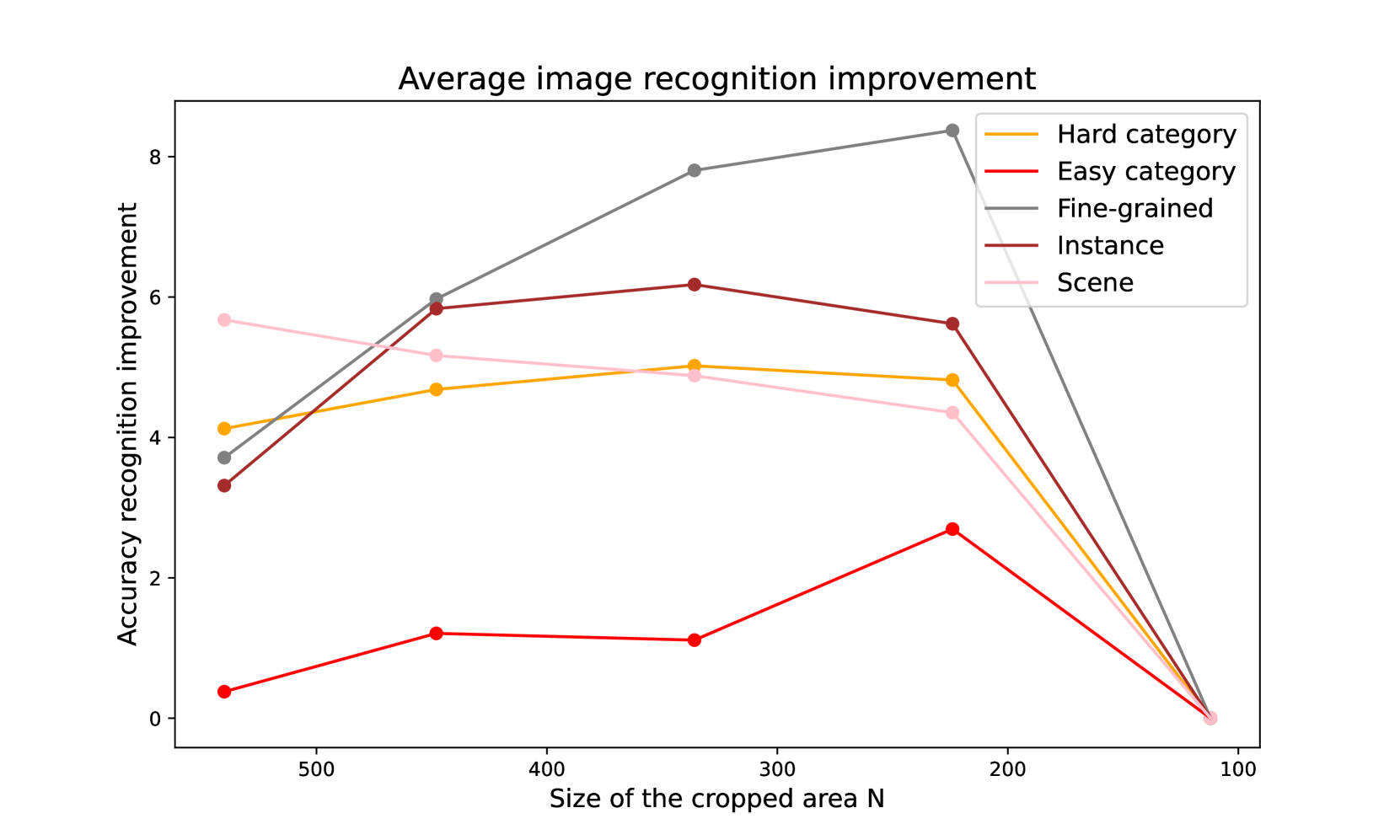
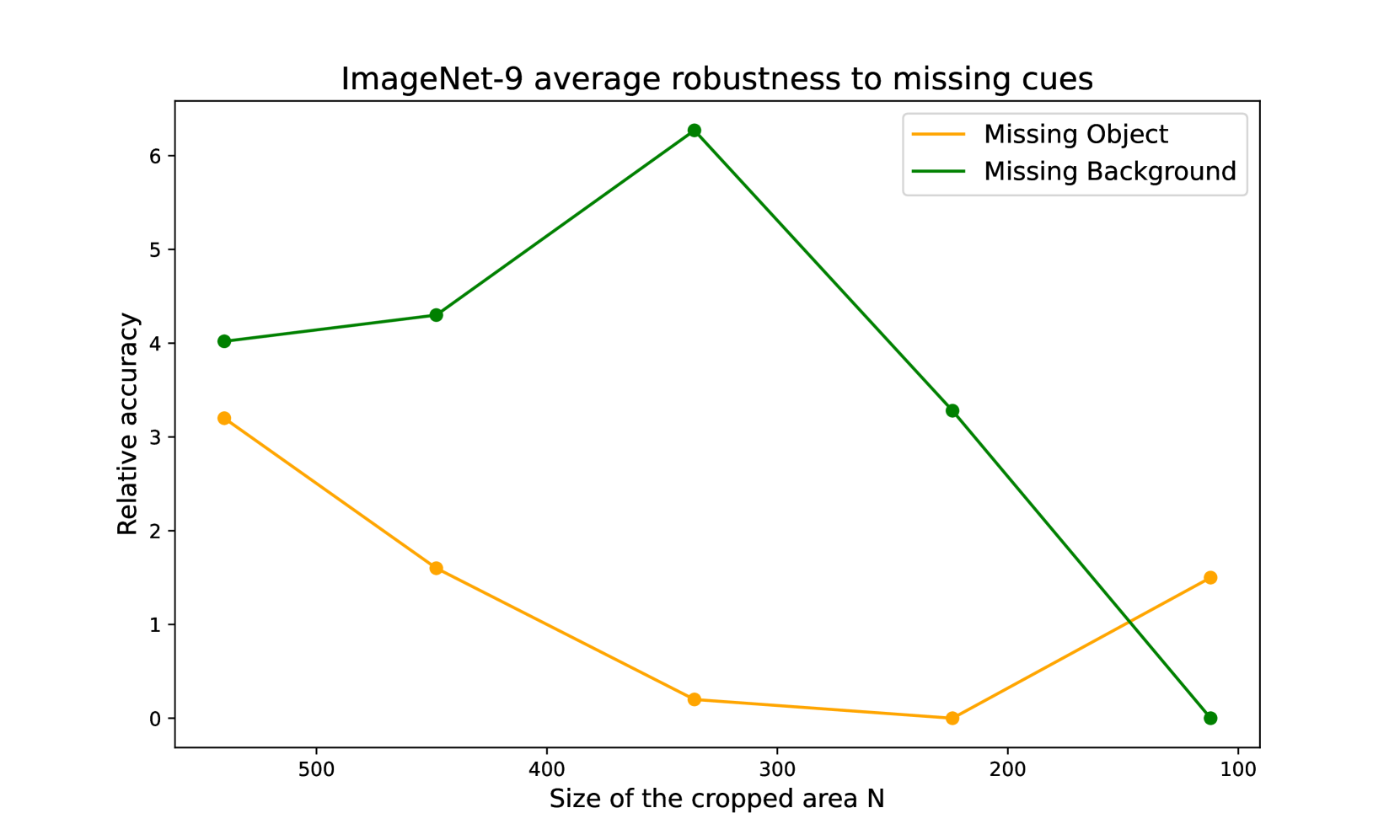
关键设计:论文使用了Ego4D数据集,该数据集提供了大量的自我中心视觉数据。注视预测模型用于预测每一帧图像的注视位置。裁剪区域的大小是一个关键参数,需要根据实际情况进行调整。自监督学习模型使用了基于时间对比学习的方法,旨在学习到具有时间一致性的视觉表征。具体的损失函数和网络结构的选择需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
该研究通过实验证明,关注中心视觉能够显著提升自监督学习模型的性能。具体而言,通过裁剪注视点周围的区域,模型学习到的物体中心表征更加有效,从而在下游任务中取得了更好的结果。该方法在Ego4D数据集上进行了验证,并与现有的自监督学习方法进行了比较,结果表明该方法具有明显的优势。
🎯 应用场景
该研究成果可应用于机器人视觉、自动驾驶、虚拟现实等领域。通过模拟人类的注视行为,可以提升机器人在复杂环境中的感知能力,使其能够更加准确地识别和理解周围的物体。此外,该方法还可以用于改善虚拟现实体验,使虚拟环境更加逼真和自然。未来,该研究有望推动人工智能技术在各个领域的应用。
📄 摘要(原文)
Recent self-supervised learning (SSL) models trained on human-like egocentric visual inputs substantially underperform on image recognition tasks compared to humans. These models train on raw, uniform visual inputs collected from head-mounted cameras. This is different from humans, as the anatomical structure of the retina and visual cortex relatively amplifies the central visual information, i.e. around humans' gaze location. This selective amplification in humans likely aids in forming object-centered visual representations. Here, we investigate whether focusing on central visual information boosts egocentric visual object learning. We simulate 5-months of egocentric visual experience using the large-scale Ego4D dataset and generate gaze locations with a human gaze prediction model. To account for the importance of central vision in humans, we crop the visual area around the gaze location. Finally, we train a time-based SSL model on these modified inputs. Our experiments demonstrate that focusing on central vision leads to better object-centered representations. Our analysis shows that the SSL model leverages the temporal dynamics of the gaze movements to build stronger visual representations. Overall, our work marks a significant step toward bio-inspired learning of visual representations.