Socratic Questioning: Learn to Self-guide Multimodal Reasoning in the Wild
作者: Wanpeng Hu, Haodi Liu, Lin Chen, Feng Zhou, Changming Xiao, Qi Yang, Changshui Zhang
分类: cs.CV, cs.AI
发布日期: 2025-01-06 (更新: 2025-01-07)
💡 一句话要点
提出Socratic Questioning框架,提升多模态LLM在复杂视觉推理中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉推理 大型语言模型 幻觉缓解 自我提问 启发式学习 视觉问答
📋 核心要点
- 复杂视觉推理面临幻觉和高训练成本等挑战,现有方法难以有效结合CoT和视觉指令调优。
- Socratic Questioning框架通过启发式自我提问,引导模型关注相关视觉线索,从而减少幻觉。
- 在CapQA数据集上,SQ方法使幻觉得分提高了31.2%,并在其他基准测试中表现出卓越的性能。
📝 摘要(中文)
本文提出了一种创新的多轮训练和推理框架Socratic Questioning (SQ),适用于轻量级多模态大型语言模型(MLLM)。该方法通过启发式地引导MLLM关注与目标问题相关的视觉线索,减少幻觉并增强模型描述细粒度图像细节的能力。这最终使模型能够在复杂的视觉推理和问答任务中表现良好。为了促进未来的研究,我们创建了一个名为CapQA的多模态小型数据集,其中包含1k个细粒度活动图像,用于视觉指令调整和评估。我们提出的SQ方法使幻觉得分提高了31.2%。在各种基准上的大量实验证明了SQ在启发式自我提问、零样本视觉推理和幻觉缓解方面的卓越能力。我们的模型和代码将公开提供。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在复杂视觉推理任务中存在的幻觉问题,以及如何更有效地利用视觉信息进行推理。现有方法,如Chain of Thought (CoT) 和视觉指令调优,虽然在一定程度上缓解了这些问题,但缺乏有机结合,且训练成本高昂。
核心思路:论文的核心思路是模仿苏格拉底式提问,让模型通过自我提问的方式,逐步聚焦于与问题相关的视觉线索。这种启发式的提问方式能够引导模型更准确地理解图像内容,减少不必要的推断和幻觉。
技术框架:Socratic Questioning (SQ) 框架包含多轮训练和推理过程。在训练阶段,模型学习如何根据问题生成有针对性的问题,并根据图像内容回答这些问题。在推理阶段,模型首先根据输入问题自我提问,然后利用视觉信息回答这些问题,最后综合所有信息给出最终答案。这个过程可以迭代多次,直到模型给出满意的答案为止。
关键创新:SQ框架的关键创新在于其启发式的自我提问机制。与传统的CoT方法不同,SQ不是简单地生成一系列推理步骤,而是根据问题动态地调整提问方向,从而更有效地利用视觉信息。此外,SQ框架的设计使其能够适用于轻量级的MLLM,降低了训练成本。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构。但是,可以推断,训练过程可能涉及到强化学习或模仿学习,以鼓励模型生成高质量的自我提问。损失函数可能包括奖励模型回答正确问题的奖励,以及惩罚模型生成不相关或错误问题的惩罚。
🖼️ 关键图片
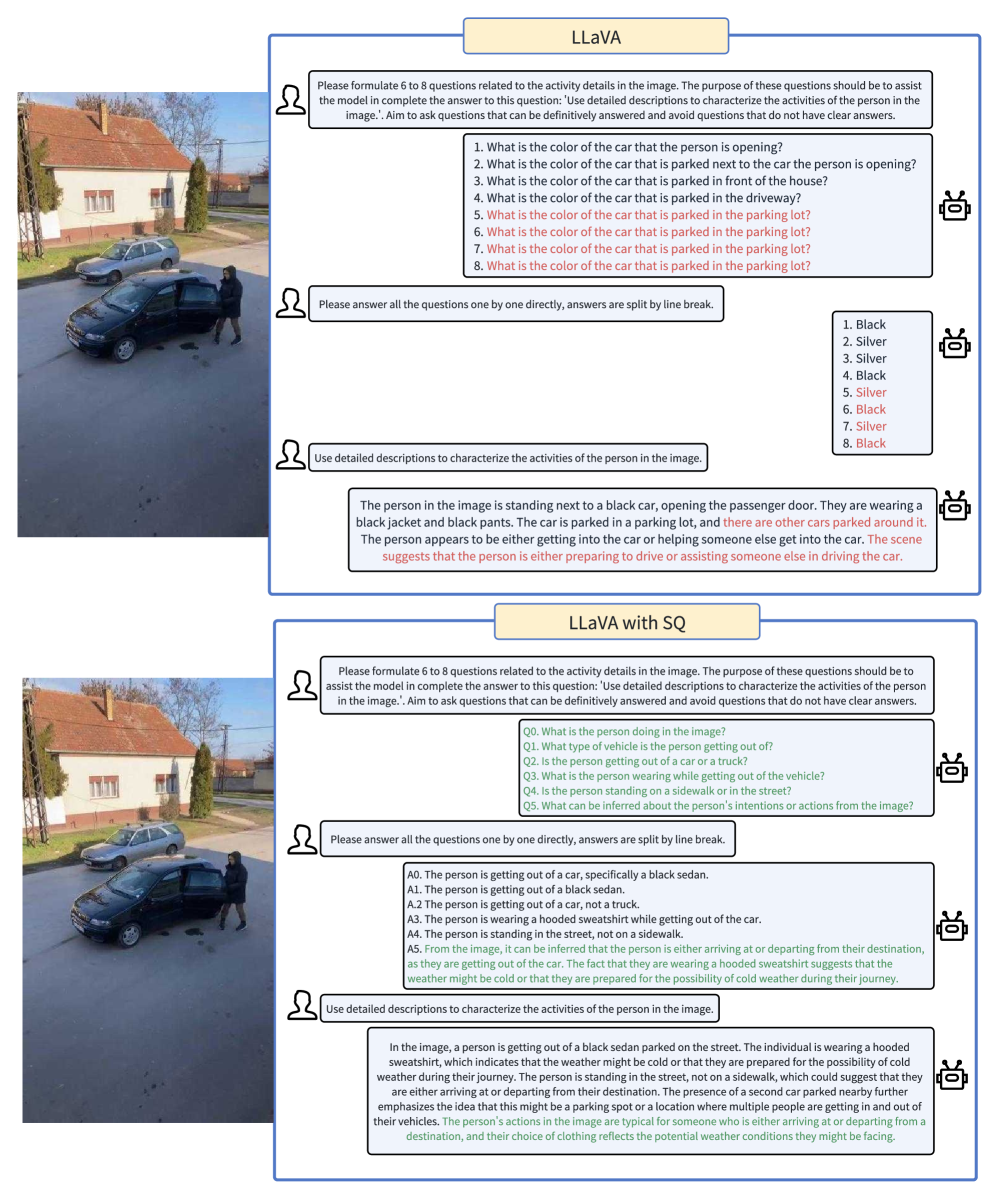


📊 实验亮点
Socratic Questioning (SQ) 方法在CapQA数据集上实现了31.2%的幻觉得分提升,表明其在缓解多模态LLM幻觉问题方面的有效性。此外,在其他视觉推理基准测试中,SQ也表现出卓越的性能,证明了其泛化能力和实用价值。该方法尤其适用于资源受限的场景,为轻量级MLLM的部署提供了新的思路。
🎯 应用场景
该研究成果可应用于智能客服、图像搜索、自动驾驶等领域。通过提升模型对图像内容的理解和推理能力,可以改善人机交互体验,提高决策的准确性。未来,该方法有望扩展到更多模态的数据,例如视频和语音,从而实现更全面的智能感知。
📄 摘要(原文)
Complex visual reasoning remains a key challenge today. Typically, the challenge is tackled using methodologies such as Chain of Thought (COT) and visual instruction tuning. However, how to organically combine these two methodologies for greater success remains unexplored. Also, issues like hallucinations and high training cost still need to be addressed. In this work, we devise an innovative multi-round training and reasoning framework suitable for lightweight Multimodal Large Language Models (MLLMs). Our self-questioning approach heuristically guides MLLMs to focus on visual clues relevant to the target problem, reducing hallucinations and enhancing the model's ability to describe fine-grained image details. This ultimately enables the model to perform well in complex visual reasoning and question-answering tasks. We have named this framework Socratic Questioning(SQ). To facilitate future research, we create a multimodal mini-dataset named CapQA, which includes 1k images of fine-grained activities, for visual instruction tuning and evaluation, our proposed SQ method leads to a 31.2% improvement in the hallucination score. Our extensive experiments on various benchmarks demonstrate SQ's remarkable capabilities in heuristic self-questioning, zero-shot visual reasoning and hallucination mitigation. Our model and code will be publicly available.