SceneVTG++: Controllable Multilingual Visual Text Generation in the Wild
作者: Jiawei Liu, Yuanzhi Zhu, Feiyu Gao, Zhibo Yang, Peng Wang, Junyang Lin, Xinggang Wang, Wenyu Liu
分类: cs.CV
发布日期: 2025-01-06 (更新: 2025-01-07)
💡 一句话要点
SceneVTG++:提出可控多语言场景视觉文本生成方法,解决自然场景图像文本生成难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文本生成 自然场景图像 多模态学习 扩散模型 文本布局 可控生成 OCR 大型语言模型
📋 核心要点
- 自然场景图像文本生成面临真实性、合理性、实用性和可控性四大挑战,现有方法难以同时满足。
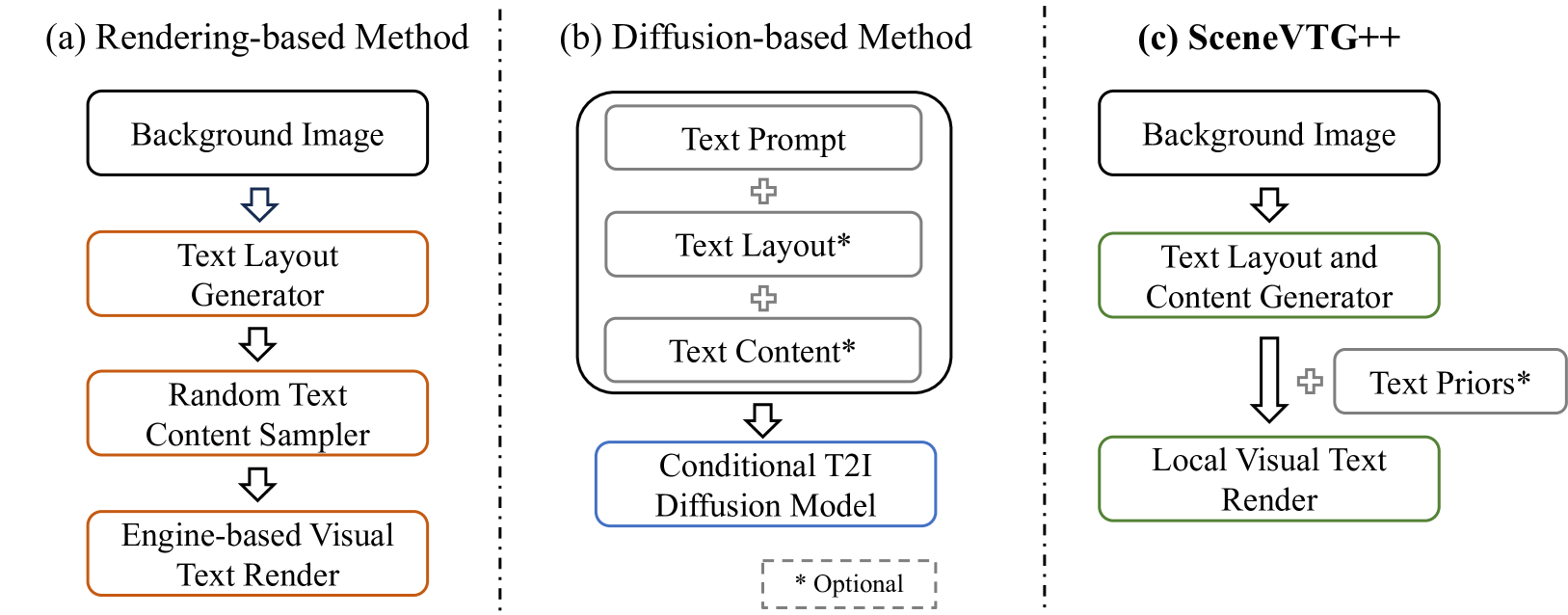
- SceneVTG++采用两阶段方法,先用TLCG确定文本布局和内容,再用CLTD生成可控多语言文本。
- 实验验证了SceneVTG++在文本生成质量和OCR任务实用性方面的优越性能,达到了最先进水平。
📝 摘要(中文)
本文提出了一种名为SceneVTG++的两阶段方法,旨在解决自然场景图像中生成视觉文本这一具有挑战性的任务。与在人工设计的图像上生成文本不同,自然场景图像中的文本需要满足四个关键标准:真实性(生成的文本应如照片般逼真且完全准确)、合理性(文本应生成在合理的载体区域上,内容应与场景相关)、实用性(生成的文本应有助于自然场景OCR任务的训练)和可控性(文本的属性应可按需控制)。SceneVTG++包含文本布局和内容生成器(TLCG)以及可控局部文本扩散(CLTD)。TLCG利用多模态大型语言模型的知识来寻找合理的文本区域,并根据自然场景背景图像推荐文本内容,而CLTD则基于扩散模型生成可控的多语言文本。通过大量实验,验证了TLCG和CLTD的有效性,并展示了SceneVTG++最先进的文本生成性能。此外,生成的图像在文本检测和文本识别等OCR任务中具有卓越的实用性。代码和数据集将可用。
🔬 方法详解
问题定义:论文旨在解决自然场景图像中视觉文本生成的问题。现有方法在真实性、合理性、实用性和可控性方面存在不足,难以生成既逼真又与场景相关的文本,并且难以控制文本的属性(如字体、颜色等)。此外,现有方法生成的文本在提升OCR任务性能方面的效果有限。
核心思路:论文的核心思路是将文本生成过程分解为两个阶段:首先,利用多模态大型语言模型的知识来确定合理的文本布局和内容;然后,基于扩散模型生成可控的局部文本。这种分解允许分别优化文本的布局和生成,从而提高生成文本的质量和可控性。
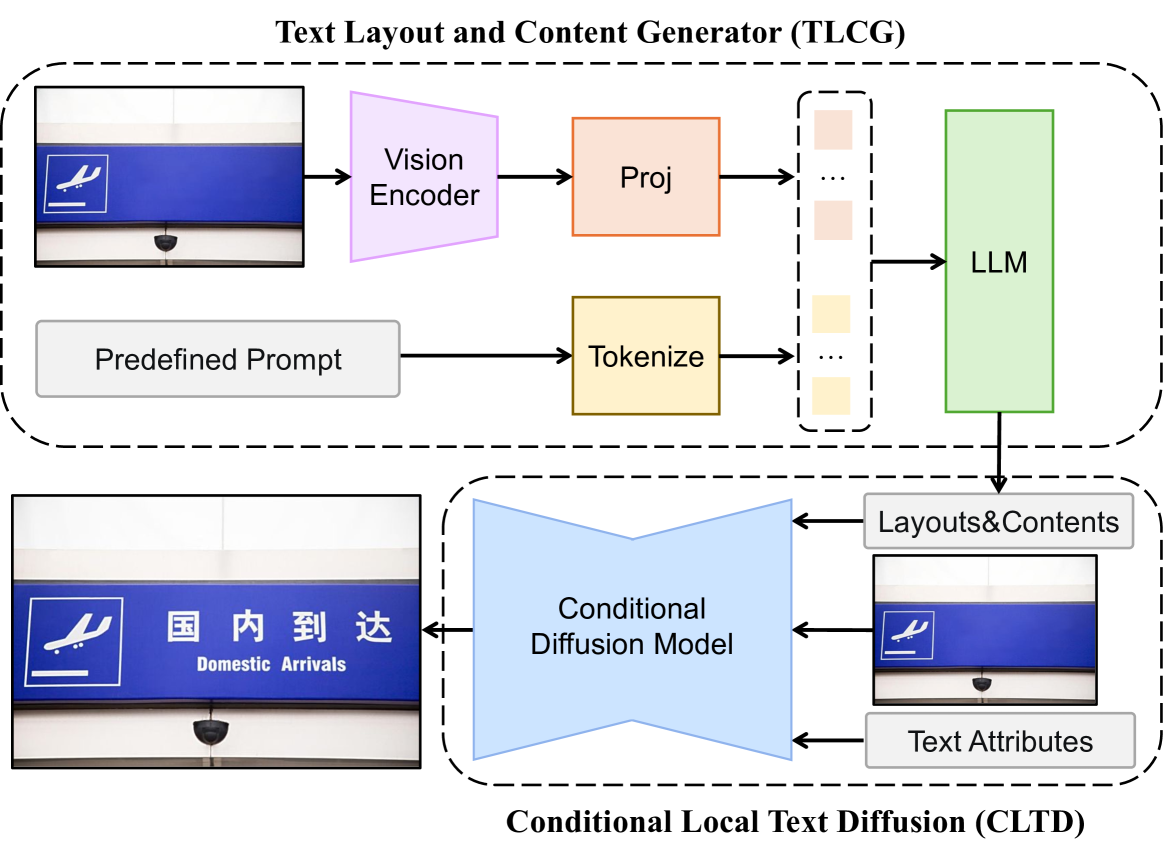
技术框架:SceneVTG++包含两个主要模块:文本布局和内容生成器(TLCG)以及可控局部文本扩散(CLTD)。TLCG首先分析自然场景图像,利用多模态LLM的知识,确定适合生成文本的区域,并根据场景内容推荐合适的文本内容。CLTD则基于扩散模型,根据用户指定的属性(如字体、颜色、语言等)生成最终的文本图像。
关键创新:该方法的关键创新在于将多模态大型语言模型和扩散模型相结合,用于自然场景图像中的文本生成。TLCG利用LLM的知识来提高文本生成的合理性,而CLTD则利用扩散模型来提高文本生成的真实性和可控性。这种结合使得SceneVTG++能够生成高质量、可控且与场景相关的文本。
关键设计:TLCG的关键设计在于如何有效地利用多模态LLM的知识来确定文本布局和内容。CLTD的关键设计在于如何控制扩散模型的生成过程,以生成具有指定属性的文本。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SceneVTG++在自然场景图像文本生成方面取得了显著的性能提升,生成文本的真实性、合理性和可控性均优于现有方法。此外,使用SceneVTG++生成的图像训练的OCR模型,在文本检测和文本识别任务中表现出更高的准确率,验证了其在OCR任务中的实用性。具体性能数据未知。
🎯 应用场景
SceneVTG++可应用于各种需要自然场景图像文本生成的领域,例如自动驾驶(生成路标、交通标志等)、增强现实(在真实场景中添加虚拟文本)、OCR数据增强(生成更多样化的训练数据)等。该研究有助于提高计算机视觉系统对自然场景的理解能力,并促进相关技术的发展。
📄 摘要(原文)
Generating visual text in natural scene images is a challenging task with many unsolved problems. Different from generating text on artificially designed images (such as posters, covers, cartoons, etc.), the text in natural scene images needs to meet the following four key criteria: (1) Fidelity: the generated text should appear as realistic as a photograph and be completely accurate, with no errors in any of the strokes. (2) Reasonability: the text should be generated on reasonable carrier areas (such as boards, signs, walls, etc.), and the generated text content should also be relevant to the scene. (3) Utility: the generated text can facilitate to the training of natural scene OCR (Optical Character Recognition) tasks. (4) Controllability: The attribute of the text (such as font and color) should be controllable as needed. In this paper, we propose a two stage method, SceneVTG++, which simultaneously satisfies the four aspects mentioned above. SceneVTG++ consists of a Text Layout and Content Generator (TLCG) and a Controllable Local Text Diffusion (CLTD). The former utilizes the world knowledge of multi modal large language models to find reasonable text areas and recommend text content according to the nature scene background images, while the latter generates controllable multilingual text based on the diffusion model. Through extensive experiments, we respectively verified the effectiveness of TLCG and CLTD, and demonstrated the state-of-the-art text generation performance of SceneVTG++. In addition, the generated images have superior utility in OCR tasks like text detection and text recognition. Codes and datasets will be available.