Large Language Models for Video Surveillance Applications
作者: Ulindu De Silva, Leon Fernando, Billy Lau Pik Lik, Zann Koh, Sam Conrad Joyce, Belinda Yuen, Chau Yuen
分类: cs.CV
发布日期: 2025-01-06
备注: Accepted for TENCON 2024
💡 一句话要点
提出基于视觉语言模型的视频监控摘要生成方法,提升分析精度和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频监控 视觉语言模型 视频摘要 生成式AI CCTV 智能安防 视频分析
📋 核心要点
- 现有视频分析方法通常提供通用摘要或有限的动作识别,难以满足用户对特定事件的快速定位需求。
- 利用视觉语言模型,根据用户自定义查询生成定制的文本摘要,聚焦于视频数据集中的相关信息。
- 实验结果表明,该方法在时间和空间质量以及一致性方面分别达到了 80% 和 70% 的准确率。
📝 摘要(中文)
视频内容产生量的快速增长带来了巨大的数据量,对高效分析和资源管理提出了严峻挑战。为了解决这个问题,强大的视频分析工具至关重要。本文提出了一种创新的概念验证,利用生成式人工智能(GenAI),具体来说是视觉语言模型,来增强下游视频分析过程。我们的工具根据用户定义的查询生成定制的文本摘要,从而在广泛的视频数据集中提供重点明确的见解。与提供通用摘要或有限动作识别的传统方法不同,我们的方法利用视觉语言模型提取相关信息,从而提高分析的精度和效率。所提出的方法从大量的闭路电视录像中生成文本摘要,与视频相比,这些摘要可以无限期地存储在非常小的存储空间中,从而使用户能够快速导航和验证重要事件,而无需进行详尽的手动审查。定性评估结果表明,该管道在时间和空间质量以及一致性方面的准确率分别为 80% 和 70%。
🔬 方法详解
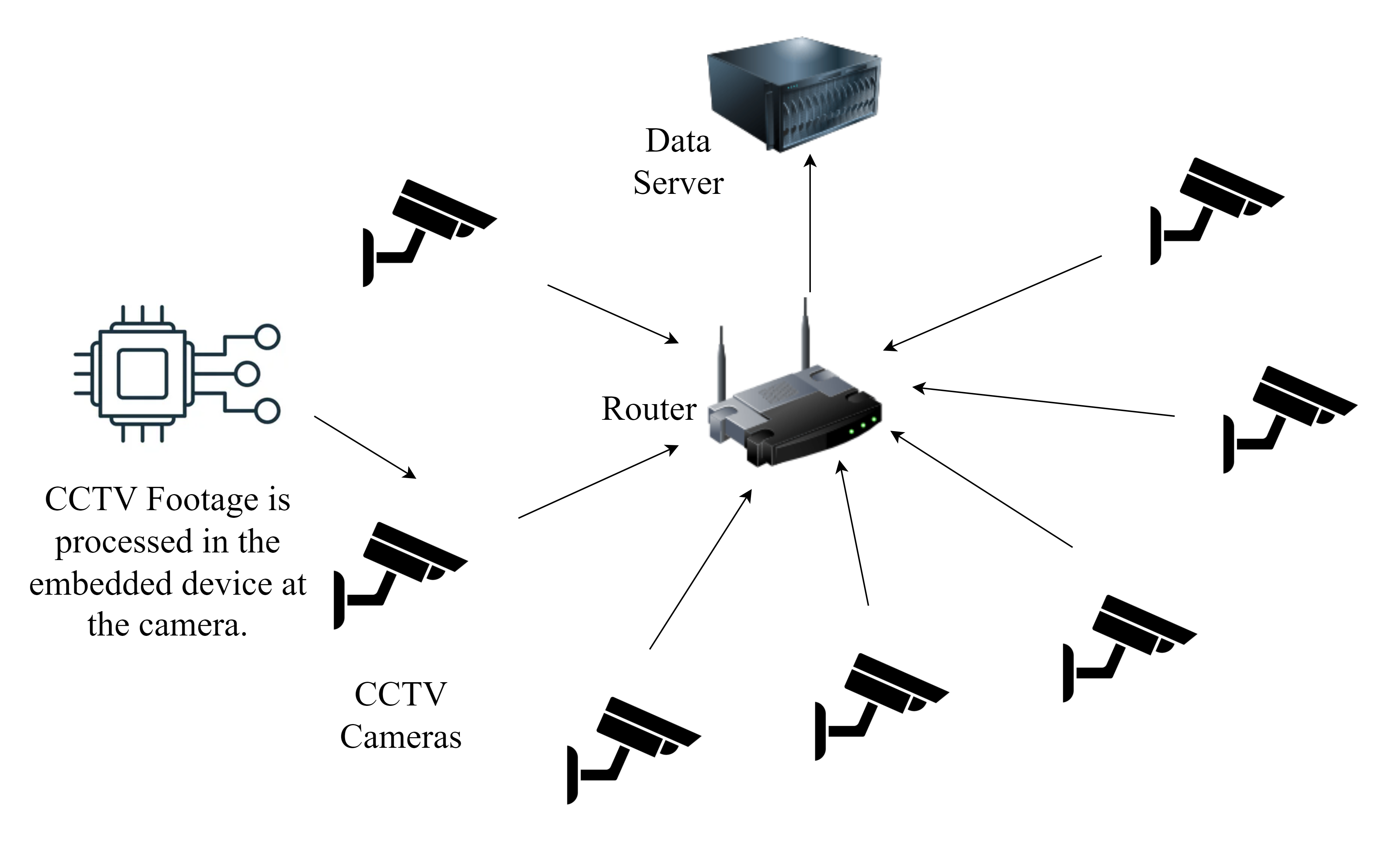
问题定义:当前视频监控系统产生海量数据,人工审核效率低下。传统视频分析方法(如通用摘要、动作识别)无法根据用户需求快速定位关键事件,存在信息冗余和分析精度不足的问题。
核心思路:利用视觉语言模型的强大能力,将视频内容转化为高度概括性的文本摘要,并允许用户通过自定义查询来引导摘要生成,从而实现精准、高效的视频内容检索和分析。这种方法旨在减少人工干预,提高信息提取效率。
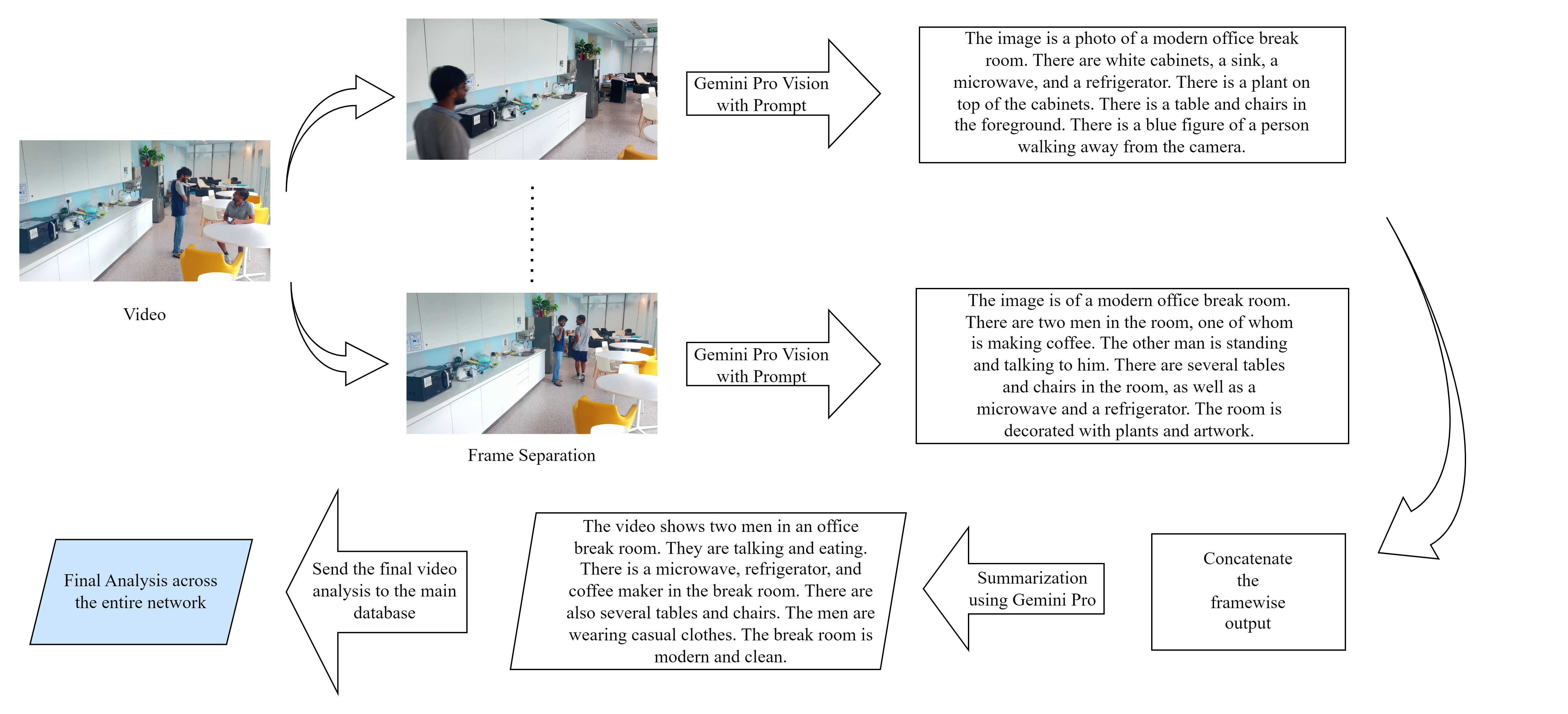
技术框架:该方法的核心是一个基于视觉语言模型的管道。首先,输入CCTV视频片段。然后,用户提供自定义查询,例如“特定时间段内特定区域发生的事件”。视觉语言模型分析视频内容,并根据用户查询生成相应的文本摘要。最后,将生成的文本摘要存储,以便后续快速检索和验证。
关键创新:该方法的核心创新在于利用视觉语言模型进行定制化的视频摘要生成。与传统方法相比,它能够根据用户需求提取视频中的关键信息,生成更具针对性和信息量的文本摘要。这种方法极大地提高了视频分析的效率和精度。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的具体细节。视觉语言模型的选择和训练是关键,但具体实现细节未知。用户查询的设计和解析也是重要环节,需要将自然语言查询转化为模型可理解的输入。
🖼️ 关键图片

📊 实验亮点
该研究通过定性评估验证了所提出方法的有效性。实验结果表明,该管道在时间和空间质量以及一致性方面的准确率分别达到了 80% 和 70%。这表明该方法能够有效地提取视频中的关键信息,并生成高质量的文本摘要。
🎯 应用场景
该研究成果可广泛应用于智能安防、交通监控、工业安全等领域。通过自动生成视频摘要,可以大幅减少人工审核的工作量,提高事件响应速度。此外,该技术还可用于视频内容检索、智能客服等场景,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
The rapid increase in video content production has resulted in enormous data volumes, creating significant challenges for efficient analysis and resource management. To address this, robust video analysis tools are essential. This paper presents an innovative proof of concept using Generative Artificial Intelligence (GenAI) in the form of Vision Language Models to enhance the downstream video analysis process. Our tool generates customized textual summaries based on user-defined queries, providing focused insights within extensive video datasets. Unlike traditional methods that offer generic summaries or limited action recognition, our approach utilizes Vision Language Models to extract relevant information, improving analysis precision and efficiency. The proposed method produces textual summaries from extensive CCTV footage, which can then be stored for an indefinite time in a very small storage space compared to videos, allowing users to quickly navigate and verify significant events without exhaustive manual review. Qualitative evaluations result in 80% and 70% accuracy in temporal and spatial quality and consistency of the pipeline respectively.