CCStereo: Audio-Visual Contextual and Contrastive Learning for Binaural Audio Generation
作者: Yuanhong Chen, Kazuki Shimada, Christian Simon, Yukara Ikemiya, Takashi Shibuya, Yuki Mitsufuji
分类: cs.SD, cs.CV, eess.AS
发布日期: 2025-01-06 (更新: 2025-08-06)
💡 一句话要点
提出基于音视频上下文对比学习的双耳音频生成模型,提升空间细节表现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双耳音频生成 音视频融合 对比学习 条件归一化 空间音频 多模态学习 测试时增强
📋 核心要点
- 现有双耳音频生成模型容易过拟合房间环境,丢失细粒度的空间细节信息。
- 利用视觉上下文信息,动态调整音频特征的均值和方差,并设计对比学习方法增强空间感知。
- 通过测试时增强提高性能,并在 FAIR-Play 和 MUSIC-Stereo 数据集上取得 SOTA 结果。
📝 摘要(中文)
本文提出了一种新的音视频双耳音频生成模型,该模型利用音视频条件归一化层,通过视觉上下文动态调整目标差分音频特征的均值和方差。同时,引入了一种新的对比学习方法,通过挖掘打乱的视觉特征作为负样本,来增强模型的空间敏感性。此外,还提出了一种经济高效的方法,利用视频数据中的测试时增强来提高性能。该方法在FAIR-Play和MUSIC-Stereo基准测试中实现了最先进的生成精度。
🔬 方法详解
问题定义:双耳音频生成(BAG)旨在利用视觉提示将单声道音频转换为立体声音频,这需要对空间和语义信息有深入的理解。现有模型容易过拟合训练环境中的房间特性,并且难以捕捉到精细的空间细节,导致生成音频的空间感不强。
核心思路:论文的核心思路是利用视觉信息作为条件,指导音频特征的生成,从而更好地模拟真实场景中的声音空间分布。通过音视频的联合学习,模型可以学习到视觉场景和音频空间信息之间的对应关系,从而生成更逼真的双耳音频。此外,对比学习的引入旨在增强模型对空间信息的敏感度。
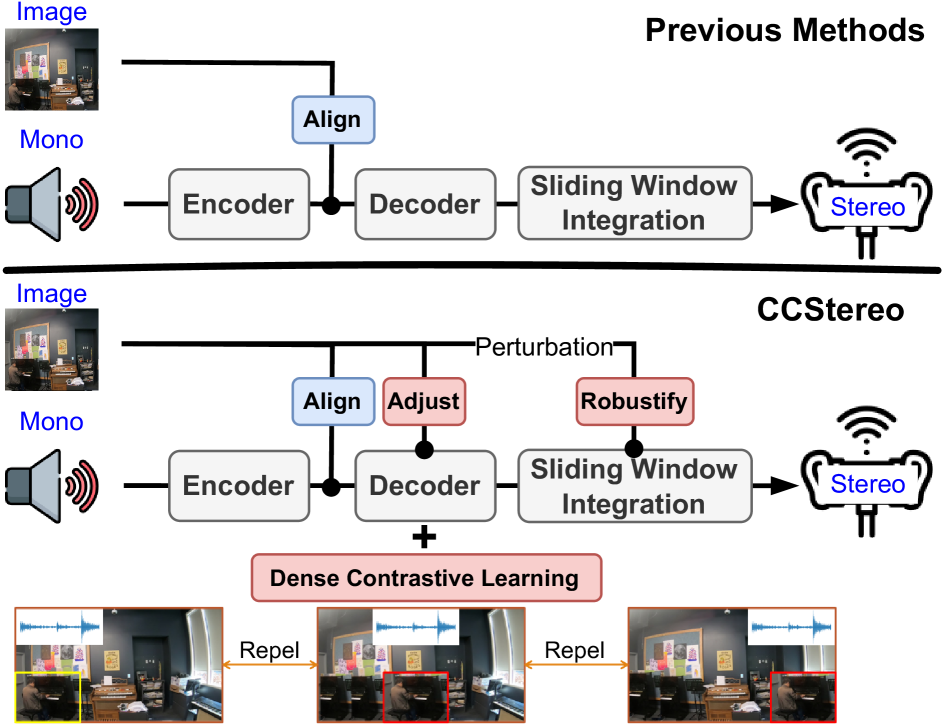
技术框架:该模型主要包含以下几个模块:1) 音频特征提取模块:用于提取单声道音频的特征表示。2) 视觉特征提取模块:用于提取视觉场景的特征表示。3) 音视频条件归一化层:利用视觉特征动态调整音频特征的均值和方差,实现音视频特征的融合。4) 双耳音频生成模块:根据融合后的特征生成双耳音频。5) 对比学习模块:通过对比正负样本,增强模型对空间信息的敏感度。
关键创新:主要的创新点包括:1) 音视频条件归一化层:该层能够动态地将视觉信息融入到音频特征中,从而更好地模拟真实场景中的声音空间分布。2) 对比学习方法:通过挖掘打乱的视觉特征作为负样本,增强模型对空间信息的敏感度。3) 测试时增强:提出了一种经济高效的测试时增强方法,进一步提高模型的性能。
关键设计:音视频条件归一化层通过计算视觉特征的均值和方差,然后将其用于调整音频特征的均值和方差。对比学习方法使用InfoNCE损失函数,正样本为原始的音视频特征对,负样本为打乱的视觉特征和原始音频特征的组合。测试时增强通过对视频进行多次采样,然后将多次生成的双耳音频进行平均,从而提高模型的鲁棒性。
🖼️ 关键图片


📊 实验亮点
该方法在 FAIR-Play 和 MUSIC-Stereo 数据集上取得了 state-of-the-art 的结果,证明了其有效性。具体性能提升数据未知,但摘要明确指出达到了最先进的生成精度。对比学习和测试时增强策略显著提升了模型的空间感知能力和生成质量。
🎯 应用场景
该研究成果可应用于虚拟现实(VR)、增强现实(AR)、游戏、电影制作等领域,提升用户在虚拟环境中的沉浸感和真实感。例如,在VR游戏中,可以根据玩家的视角和场景中的物体位置,生成逼真的双耳音频,从而增强游戏的沉浸感。在电影制作中,可以利用该技术将单声道音频转换为立体声音频,从而提升电影的音效质量。
📄 摘要(原文)
Binaural audio generation (BAG) aims to convert monaural audio to stereo audio using visual prompts, requiring a deep understanding of spatial and semantic information. However, current models risk overfitting to room environments and lose fine-grained spatial details. In this paper, we propose a new audio-visual binaural generation model incorporating an audio-visual conditional normalisation layer that dynamically aligns the mean and variance of the target difference audio features using visual context, along with a new contrastive learning method to enhance spatial sensitivity by mining negative samples from shuffled visual features. We also introduce a cost-efficient way to utilise test-time augmentation in video data to enhance performance. Our approach achieves state-of-the-art generation accuracy on the FAIR-Play and MUSIC-Stereo benchmarks.