Visual Large Language Models for Generalized and Specialized Applications
作者: Yifan Li, Zhixin Lai, Wentao Bao, Zhen Tan, Anh Dao, Kewei Sui, Jiayi Shen, Dong Liu, Huan Liu, Yu Kong
分类: cs.CV, cs.AI
发布日期: 2025-01-06
🔗 代码/项目: GITHUB
💡 一句话要点
综述视觉大语言模型在通用和专用场景下的应用,并探讨其挑战与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉大语言模型 多模态学习 通用人工智能 视觉语言融合 跨模态应用
📋 核心要点
- 现有VLLM文献在应用层面,尤其是在跨模态的通用和专用场景中,覆盖不够全面。
- 该综述旨在全面考察VLLM在视觉、动作和语言模态中的应用,并分析其伦理挑战。
- 通过对VLLM应用场景、挑战和未来方向的综合分析,为该领域的未来研究提供指导。
📝 摘要(中文)
视觉语言模型(VLM)已成为学习视觉和语言统一嵌入空间的强大工具。受到大型语言模型的启发,后者展示了强大的推理和多任务能力,视觉大型语言模型(VLLM)在构建通用VLM方面正受到越来越多的关注。尽管VLLM取得了显著进展,但相关文献仍然有限,特别是从全面的应用角度来看,包括跨视觉(图像、视频、深度)、动作和语言模态的通用和专用应用。本综述侧重于VLLM的多样化应用,考察它们的使用场景,识别伦理考量和挑战,并讨论其未来发展方向。通过综合这些内容,我们旨在提供一个全面的指南,为VLLM的未来创新和更广泛的应用铺平道路。论文列表仓库地址:https://github.com/JackYFL/awesome-VLLMs。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)虽然在统一视觉和语言嵌入空间方面取得了进展,但缺乏对视觉大语言模型(VLLM)在各种实际应用场景,特别是通用和专用场景下的系统性研究和分析。现有文献对VLLM的应用覆盖不够全面,尤其是在跨视觉(图像、视频、深度)、动作和语言模态的场景中。此外,对VLLM的伦理考量和挑战也缺乏深入探讨。
核心思路:该综述的核心思路是对现有VLLM的研究和应用进行全面的梳理和分析,重点关注其在不同模态和场景下的应用。通过分析VLLM的使用场景、识别伦理考量和挑战,并讨论其未来发展方向,为VLLM的未来创新和更广泛的应用提供指导。
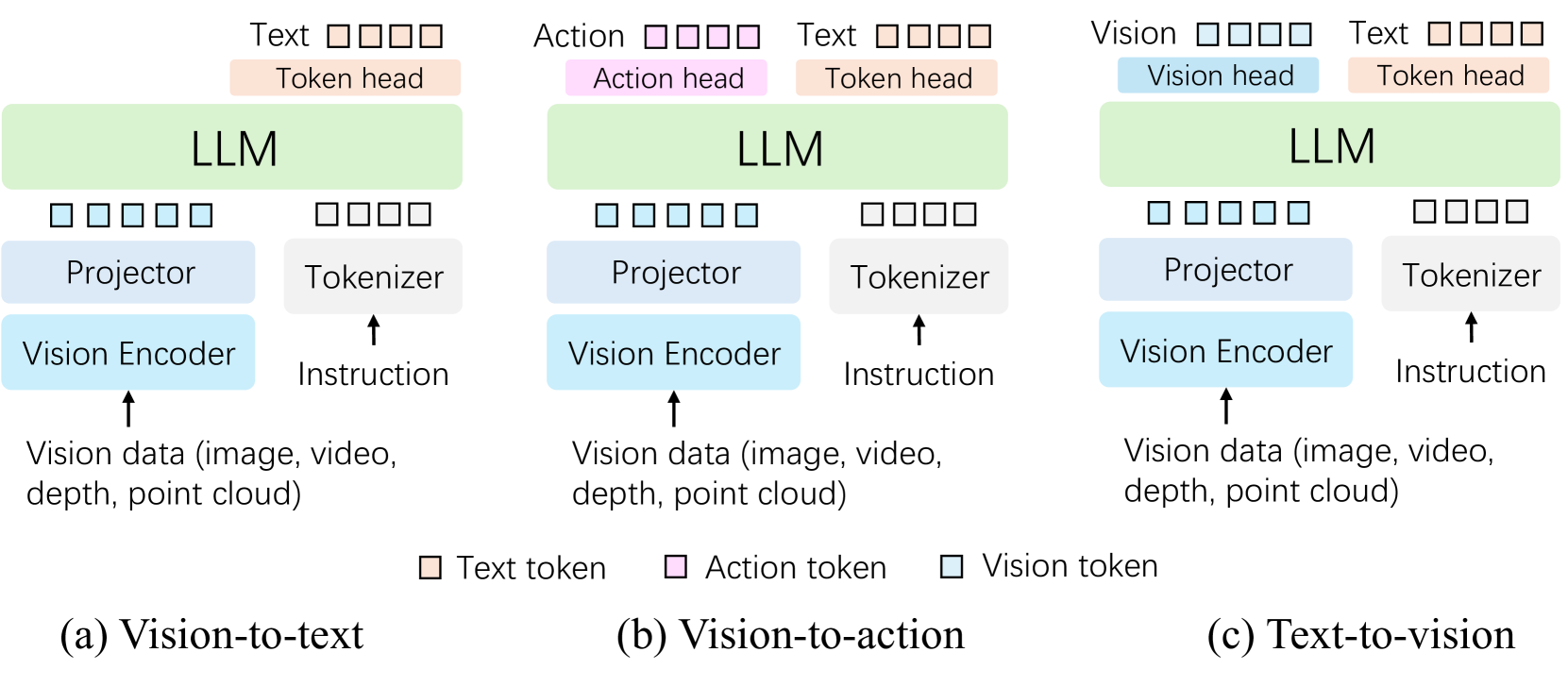
技术框架:该综述的技术框架主要包括以下几个方面:1) 对VLLM的定义和发展历程进行概述;2) 详细分析VLLM在各种应用场景下的应用,包括图像、视频、深度、动作和语言模态;3) 识别VLLM在应用过程中面临的伦理考量和挑战;4) 讨论VLLM的未来发展方向,包括技术创新和应用拓展。
关键创新:该综述的关键创新在于其对VLLM应用场景的全面性和系统性分析。不同于以往的研究主要关注VLLM的技术细节,该综述更加关注VLLM在实际应用中的表现和潜力。此外,该综述还首次对VLLM的伦理考量和挑战进行了深入探讨,为VLLM的健康发展提供了重要参考。
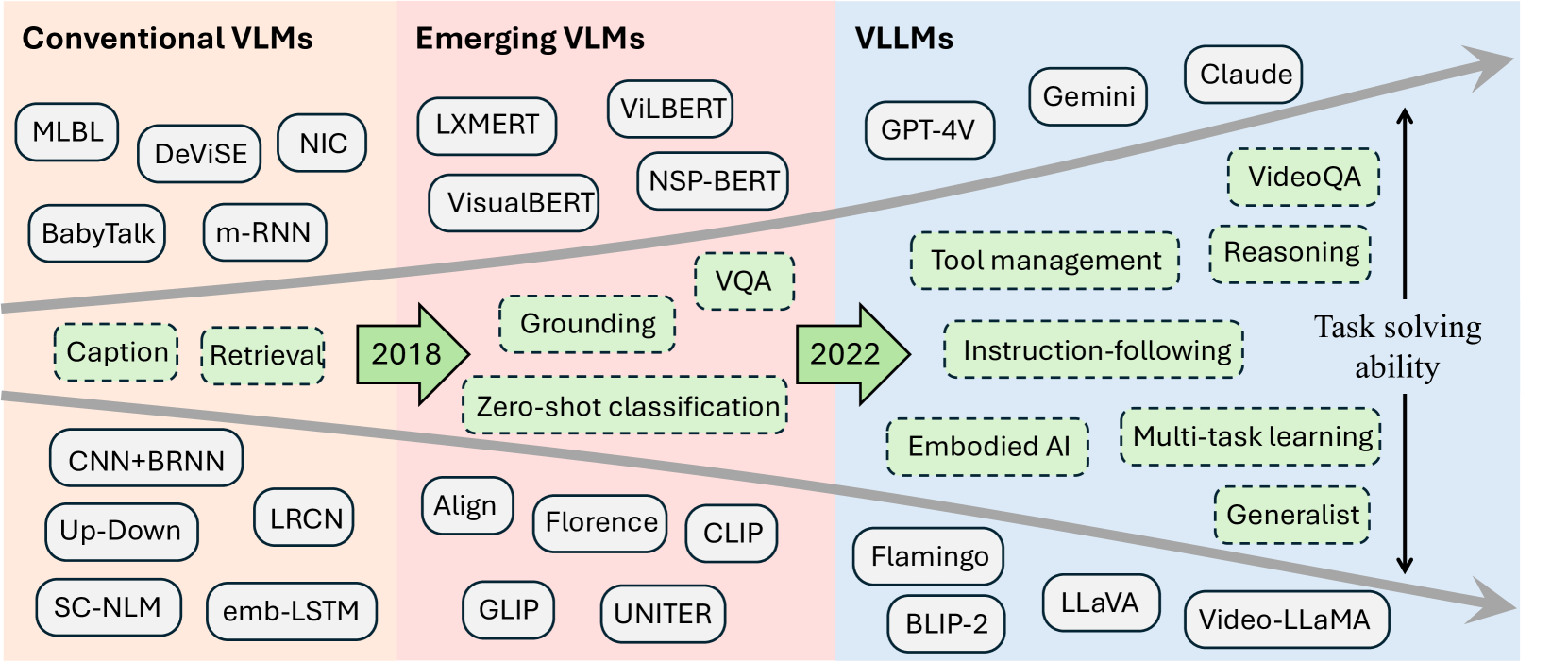
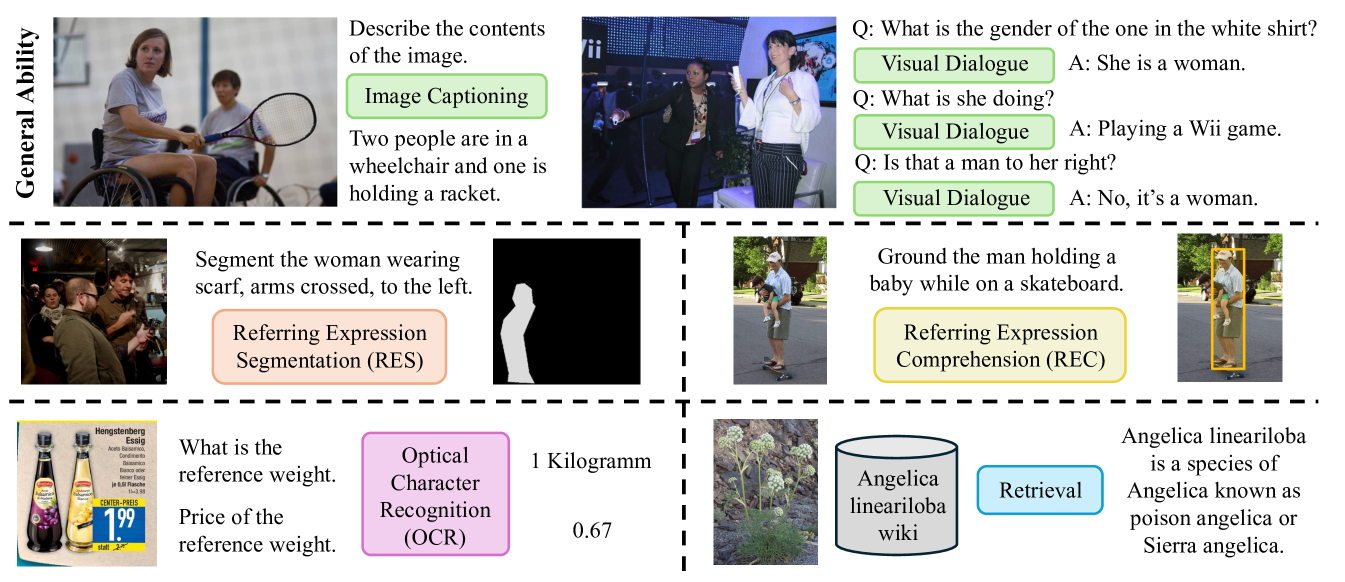
关键设计:该综述的关键设计在于其对VLLM应用场景的分类和组织方式。该综述将VLLM的应用场景分为通用应用和专用应用,并进一步细分为图像、视频、深度、动作和语言模态。这种分类方式有助于读者更好地理解VLLM在不同场景下的应用特点和优势。此外,该综述还采用了大量的案例研究和实验结果,以支持其观点和结论。
🖼️ 关键图片
📊 实验亮点
该综述整理了大量VLLM相关的论文,并对其应用场景进行了详细的分类和分析。通过对这些论文的总结,该综述为VLLM的研究人员提供了一个全面的参考指南。此外,该综述还指出了VLLM在应用过程中面临的伦理考量和挑战,为VLLM的健康发展提供了重要参考。
🎯 应用场景
该研究成果可应用于多个领域,包括智能机器人、自动驾驶、智能家居、医疗诊断等。通过利用VLLM的强大能力,可以实现更智能、更高效的人机交互和决策。例如,在智能机器人领域,VLLM可以帮助机器人更好地理解人类的指令和环境,从而完成更复杂的任务。在自动驾驶领域,VLLM可以帮助车辆更好地感知周围环境,从而提高驾驶安全性。
📄 摘要(原文)
Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.