DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
作者: Ziyang Song, Zerong Wang, Bo Li, Hao Zhang, Ruijie Zhu, Li Liu, Peng-Tao Jiang, Tianzhu Zhang
分类: cs.CV
发布日期: 2025-01-05
备注: 11 pages, 6 figures, 6 tables
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DepthMaster:利用扩散模型提升单目深度估计的泛化性和细节保持能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 扩散模型 特征对齐 傅里叶增强 深度学习 生成模型 判别模型
📋 核心要点
- 现有基于扩散模型的单目深度估计方法泛化性强但推理速度慢,单步确定性方法忽略了生成特征和判别特征之间的差距,导致性能次优。
- DepthMaster通过特征对齐模块缓解纹理过拟合,并利用傅里叶增强模块平衡低频结构和高频细节,从而适配生成特征。
- 实验结果表明,DepthMaster在泛化性和细节保持方面优于其他基于扩散的方法,并在多个数据集上取得了SOTA性能。
📝 摘要(中文)
本文提出DepthMaster,一种单步扩散模型,旨在将生成特征适配于判别式深度估计任务。为了缓解生成特征引入的纹理细节过拟合问题,提出了特征对齐模块,该模块融合高质量语义特征以增强去噪网络的表征能力。针对单步确定性框架缺乏精细细节的问题,提出了傅里叶增强模块,自适应地平衡低频结构和高频细节。采用两阶段训练策略,充分利用两个模块的潜力。第一阶段侧重于利用特征对齐模块学习全局场景结构,第二阶段利用傅里叶增强模块提升视觉质量。实验结果表明,该模型在泛化性和细节保持方面均达到了最先进的性能,优于其他基于扩散的方法。
🔬 方法详解
问题定义:单目深度估计旨在从单张图像中预测场景的深度信息。现有基于扩散模型的单目深度估计方法虽然具有较好的泛化能力,但推理速度较慢。为了提高推理效率,一些方法采用单步确定性框架,但忽略了生成特征和判别特征之间的差距,导致深度估计结果不够理想,尤其是在细节恢复方面存在不足。
核心思路:DepthMaster的核心思路是将扩散模型的生成能力与判别式深度估计任务相结合,通过特征对齐和傅里叶增强两个模块,弥合生成特征与判别特征之间的差距,从而在保证推理速度的同时,提升深度估计的精度和细节保持能力。这样设计的目的是充分利用扩散模型的全局建模能力,同时避免其在细节上的不足。
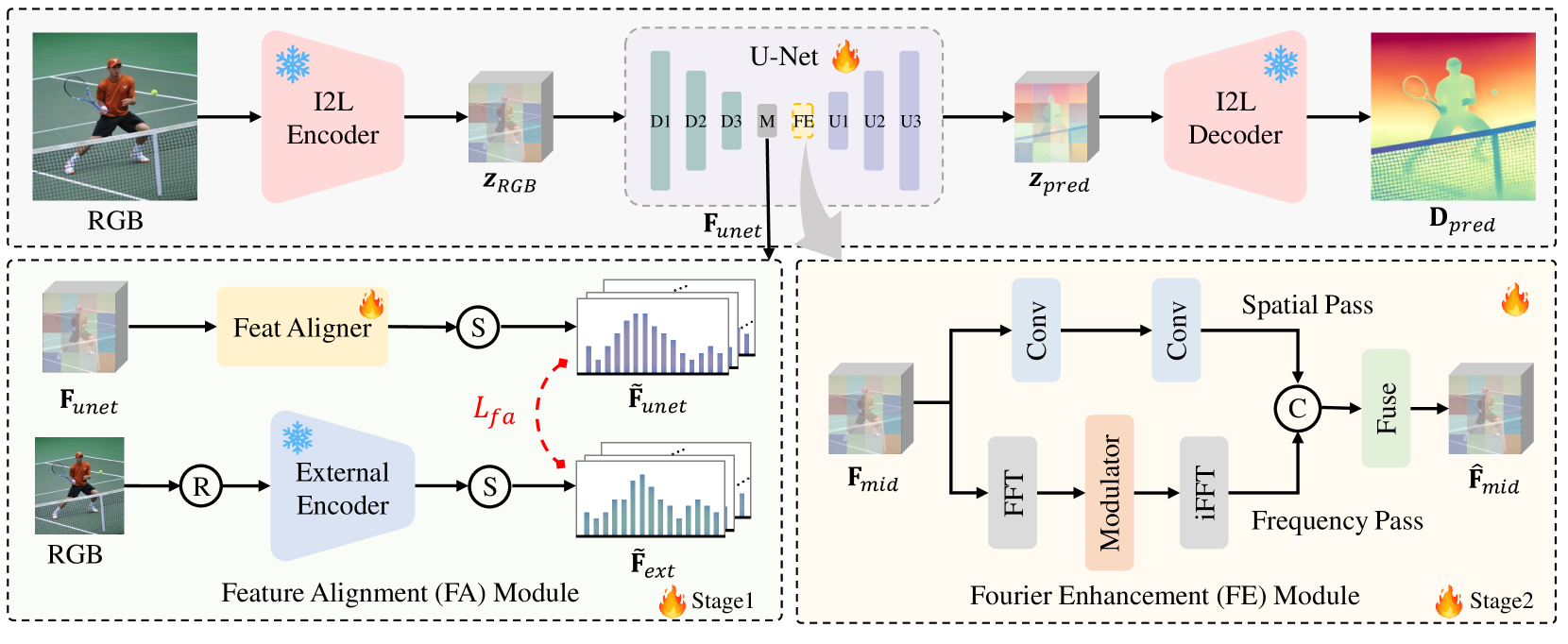
技术框架:DepthMaster采用单步扩散模型框架,包含特征对齐模块和傅里叶增强模块。整体流程如下:首先,输入图像经过特征提取网络得到初始特征;然后,特征对齐模块将初始特征与高质量语义特征对齐,增强网络的表征能力;接着,傅里叶增强模块自适应地平衡低频结构和高频细节,提升深度图的视觉质量;最后,经过深度预测头得到最终的深度估计结果。采用两阶段训练策略,第一阶段训练特征对齐模块,学习全局场景结构,第二阶段训练傅里叶增强模块,提升视觉质量。
关键创新:DepthMaster的关键创新在于提出了特征对齐模块和傅里叶增强模块。特征对齐模块通过融合高质量语义特征,缓解了生成特征引入的纹理细节过拟合问题。傅里叶增强模块通过自适应地平衡低频结构和高频细节,解决了单步确定性框架缺乏精细细节的问题。与现有方法的本质区别在于,DepthMaster更加注重生成特征与判别特征之间的适配,从而在保证推理速度的同时,提升了深度估计的精度和细节保持能力。
关键设计:特征对齐模块的关键设计在于如何选择和融合高质量语义特征。论文中具体采用的语义特征来源未知。傅里叶增强模块的关键设计在于如何自适应地平衡低频结构和高频细节,具体实现方式未知。两阶段训练策略的关键设计在于如何合理地安排两个模块的训练顺序和权重,具体参数设置未知。损失函数的设计也未知。
🖼️ 关键图片
📊 实验亮点
DepthMaster在多个数据集上取得了state-of-the-art的性能,尤其是在细节保持方面表现出色。具体性能数据和对比基线在论文中给出,但此处未提供具体数值。实验结果表明,DepthMaster能够有效地缓解纹理过拟合问题,并提升深度估计的精度和视觉质量。与现有的基于扩散的方法相比,DepthMaster在推理速度和性能之间取得了更好的平衡。
🎯 应用场景
DepthMaster在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。高精度、高效率的单目深度估计可以帮助自动驾驶系统更好地理解周围环境,提高导航的准确性和安全性。在机器人导航中,可以帮助机器人进行场景理解和路径规划。在增强现实中,可以为虚拟物体提供更真实的深度信息,提升用户体验。未来,该研究可以进一步扩展到视频深度估计、动态场景深度估计等领域。
📄 摘要(原文)
Monocular depth estimation within the diffusion-denoising paradigm demonstrates impressive generalization ability but suffers from low inference speed. Recent methods adopt a single-step deterministic paradigm to improve inference efficiency while maintaining comparable performance. However, they overlook the gap between generative and discriminative features, leading to suboptimal results. In this work, we propose DepthMaster, a single-step diffusion model designed to adapt generative features for the discriminative depth estimation task. First, to mitigate overfitting to texture details introduced by generative features, we propose a Feature Alignment module, which incorporates high-quality semantic features to enhance the denoising network's representation capability. Second, to address the lack of fine-grained details in the single-step deterministic framework, we propose a Fourier Enhancement module to adaptively balance low-frequency structure and high-frequency details. We adopt a two-stage training strategy to fully leverage the potential of the two modules. In the first stage, we focus on learning the global scene structure with the Feature Alignment module, while in the second stage, we exploit the Fourier Enhancement module to improve the visual quality. Through these efforts, our model achieves state-of-the-art performance in terms of generalization and detail preservation, outperforming other diffusion-based methods across various datasets. Our project page can be found at https://indu1ge.github.io/DepthMaster_page.