AHMSA-Net: Adaptive Hierarchical Multi-Scale Attention Network for Micro-Expression Recognition
作者: Lijun Zhang, Yifan Zhang, Weicheng Tang, Xinzhi Sun, Xiaomeng Wang, Zhanshan Li
分类: cs.CV
发布日期: 2025-01-05
💡 一句话要点
提出AHMSA-Net,通过自适应分层多尺度注意力网络提升微表情识别精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 微表情识别 注意力机制 光流特征 自适应分层 多尺度融合
📋 核心要点
- 微表情识别面临的挑战在于微表情运动的短暂性和细微性,现有方法在特征捕获和动态适应方面存在不足。
- AHMSA-Net通过自适应分层框架和多尺度注意力机制,从不同粒度和尺度捕获微表情的细微变化,提升识别精度。
- 实验结果表明,AHMSA-Net在多个微表情数据库上取得了有竞争力的结果,显著提高了识别准确率。
📝 摘要(中文)
微表情识别(MER)由于运动变化的短暂和细微性而面临重大挑战。近年来,基于注意力机制的深度学习方法在MER中取得了一些突破。然而,这些方法在应对微表情的瞬时细微运动变化时,仍然存在特征捕获不足和动态适应性差的局限性。因此,本文设计了一种用于MER的自适应分层多尺度注意力网络(AHMSA-Net)。具体来说,我们首先利用微表情序列的起始帧和顶点帧来提取三维(3D)光流图,包括水平光流、垂直光流和光流应变。随后,光流特征图被输入到AHMSA-Net中,该网络由两部分组成:自适应分层框架和多尺度注意力机制。基于自适应下采样分层注意力框架,AHMSA-Net通过动态调整每层光流特征图的大小,从不同粒度(精细和粗略)捕获微表情的细微变化。基于多尺度注意力机制,AHMSA-Net通过融合来自不同尺度(通道和空间)的特征来学习微表情动作信息。这两个模块协同工作,全面提高MER的准确性。此外,严格的实验表明,所提出的方法在主要的微表情数据库上取得了有竞争力的结果,AHMSA-Net在复合数据库(SMIC、SAMM、CASMEII)上实现了高达78.21%的识别准确率,在CASME^3数据库上实现了77.08%的识别准确率。
🔬 方法详解
问题定义:微表情识别旨在识别面部短暂而细微的情感表达。现有方法在捕捉微表情的细微运动变化方面存在不足,尤其是在动态适应不同微表情序列时表现不佳。这些方法通常难以充分提取关键特征,导致识别精度受限。
核心思路:AHMSA-Net的核心思路是利用自适应分层框架动态调整特征图大小,从而在不同粒度上捕捉微表情的细微变化。同时,采用多尺度注意力机制融合不同尺度的特征,学习更全面的微表情动作信息。这种设计旨在提高模型对微表情瞬时变化的敏感性和适应性。
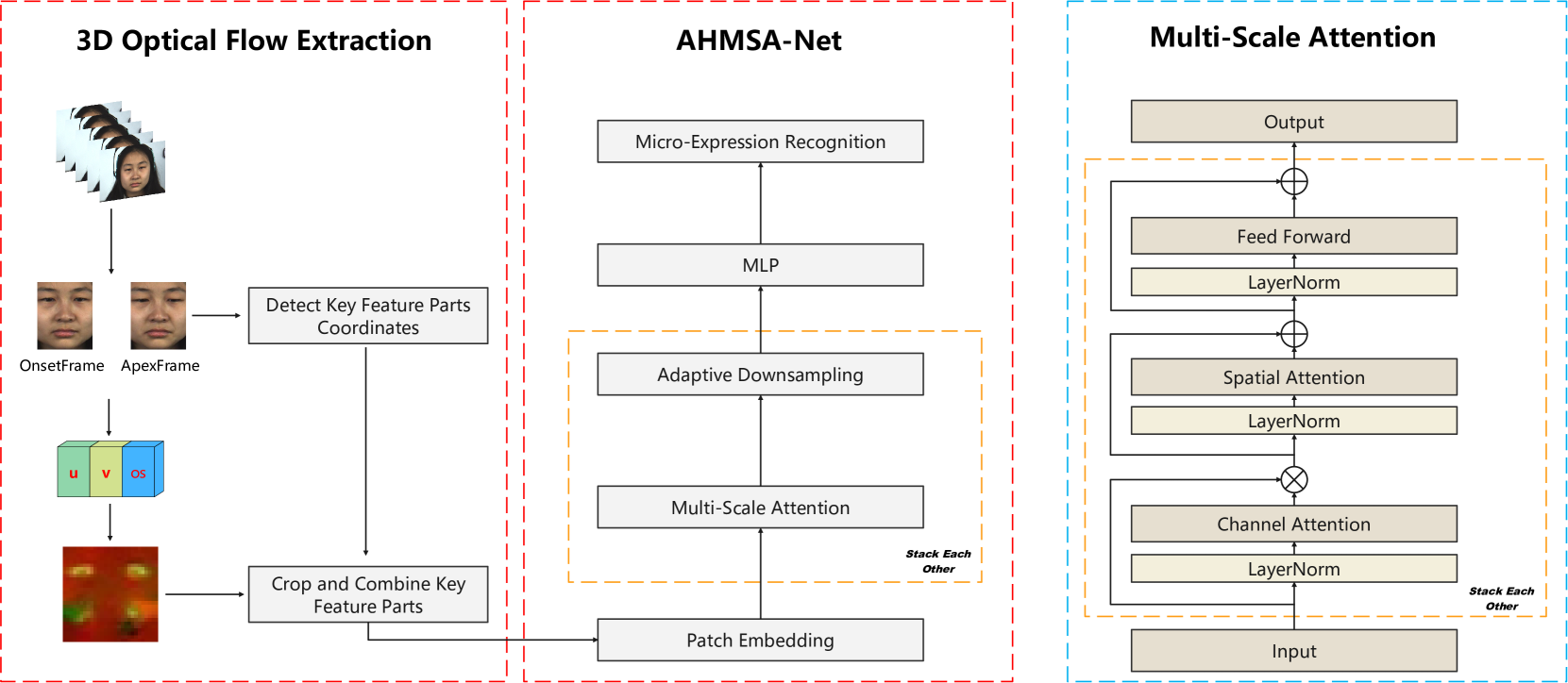
技术框架:AHMSA-Net的整体架构包括以下几个主要阶段:1) 3D光流提取:利用微表情序列的起始帧和顶点帧提取水平、垂直光流和光流应变。2) 自适应分层框架:通过自适应下采样动态调整特征图大小,形成分层结构。3) 多尺度注意力机制:在通道和空间维度上融合不同尺度的特征。4) 分类器:利用提取的特征进行微表情分类。
关键创新:AHMSA-Net的关键创新在于自适应分层框架和多尺度注意力机制的结合。自适应分层框架能够动态调整特征图大小,从而在不同粒度上捕捉微表情的细微变化。多尺度注意力机制则能够融合不同尺度的特征,学习更全面的微表情动作信息。这种结合使得AHMSA-Net能够更有效地捕捉和利用微表情的细微运动变化。
关键设计:在自适应分层框架中,下采样率是关键参数,需要根据不同数据集进行调整。多尺度注意力机制中,通道注意力和空间注意力的权重需要通过实验进行优化。损失函数通常采用交叉熵损失函数,以优化分类性能。网络结构方面,卷积层、池化层和注意力模块的组合方式也需要仔细设计。
🖼️ 关键图片

📊 实验亮点
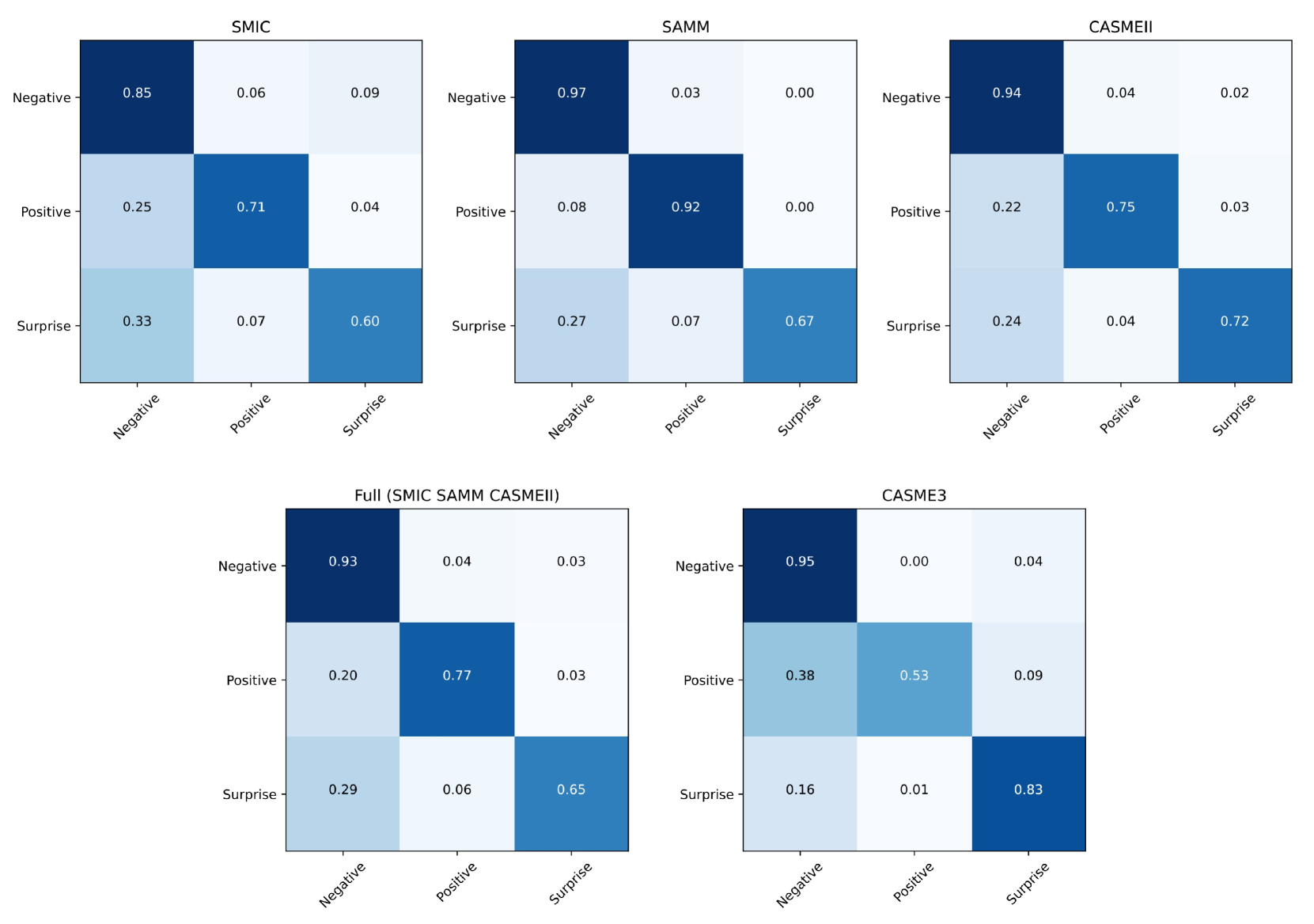
AHMSA-Net在复合数据库(SMIC、SAMM、CASMEII)上实现了高达78.21%的识别准确率,在CASME^3数据库上实现了77.08%的识别准确率。这些结果表明,AHMSA-Net在微表情识别方面具有显著的优势,优于现有方法。
🎯 应用场景
该研究成果可应用于心理学研究、安全监控、人机交互等领域。例如,在心理学研究中,可以帮助研究人员更准确地分析个体的情感状态。在安全监控中,可以用于检测潜在的威胁行为。在人机交互中,可以提高机器对人类情感的理解能力,从而实现更自然、更智能的交互。
📄 摘要(原文)
Micro-expression recognition (MER) presents a significant challenge due to the transient and subtle nature of the motion changes involved. In recent years, deep learning methods based on attention mechanisms have made some breakthroughs in MER. However, these methods still suffer from the limitations of insufficient feature capture and poor dynamic adaptation when coping with the instantaneous subtle movement changes of micro-expressions. Therefore, in this paper, we design an Adaptive Hierarchical Multi-Scale Attention Network (AHMSA-Net) for MER. Specifically, we first utilize the onset and apex frames of the micro-expression sequence to extract three-dimensional (3D) optical flow maps, including horizontal optical flow, vertical optical flow, and optical flow strain. Subsequently, the optical flow feature maps are inputted into AHMSA-Net, which consists of two parts: an adaptive hierarchical framework and a multi-scale attention mechanism. Based on the adaptive downsampling hierarchical attention framework, AHMSA-Net captures the subtle changes of micro-expressions from different granularities (fine and coarse) by dynamically adjusting the size of the optical flow feature map at each layer. Based on the multi-scale attention mechanism, AHMSA-Net learns micro-expression action information by fusing features from different scales (channel and spatial). These two modules work together to comprehensively improve the accuracy of MER. Additionally, rigorous experiments demonstrate that the proposed method achieves competitive results on major micro-expression databases, with AHMSA-Net achieving recognition accuracy of up to 78.21% on composite databases (SMIC, SAMM, CASMEII) and 77.08% on the CASME^{}3 database.