Face-MakeUp: Multimodal Facial Prompts for Text-to-Image Generation
作者: Dawei Dai, Mingming Jia, Yinxiu Zhou, Hang Xing, Chenghang Li
分类: cs.CV, cs.AI
发布日期: 2025-01-05
🔗 代码/项目: GITHUB
💡 一句话要点
Face-MakeUp:利用多模态面部提示提升文本到图像生成的人脸质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸生成 文本到图像 扩散模型 多模态融合 图像提示
📋 核心要点
- 现有文本到图像生成模型在人脸生成方面存在挑战,难以仅通过文本提示精确控制生成结果。
- Face-MakeUp 提出提取并融合多尺度内容和姿态特征,增强扩散模型对面部身份信息的保持能力。
- 通过 FaceCaptionHQ-4M 数据集训练,并在人脸数据集上验证,Face-MakeUp 取得了最佳的综合性能。
📝 摘要(中文)
面部图像具有广泛的实际应用。虽然目前的大规模文本-图像扩散模型表现出强大的生成能力,但仅使用文本提示生成所需的面部图像仍然具有挑战性。图像提示是一个合理的选择。然而,目前此类方法通常侧重于通用领域。本文旨在优化图像化妆技术,以生成所需的面部图像。具体来说,(1) 我们基于 LAION-Face 构建了一个包含 400 万高质量面部图像-文本对的数据集 (FaceCaptionHQ-4M),以训练我们的 Face-MakeUp 模型;(2) 为了保持与参考面部图像的一致性,我们提取/学习面部图像的多尺度内容特征和姿势特征,并将这些特征集成到扩散模型中,以增强扩散模型对面部身份特征的保留。在两个与面部相关的测试数据集上的验证表明,我们的 Face-MakeUp 可以实现最佳的综合性能。
🔬 方法详解
问题定义:论文旨在解决仅使用文本提示难以生成高质量、符合要求的特定人脸图像的问题。现有方法在人脸生成方面存在身份保持不佳、细节控制不足等痛点,尤其是在需要参考图像进行风格迁移或属性编辑时,效果往往不尽如人意。
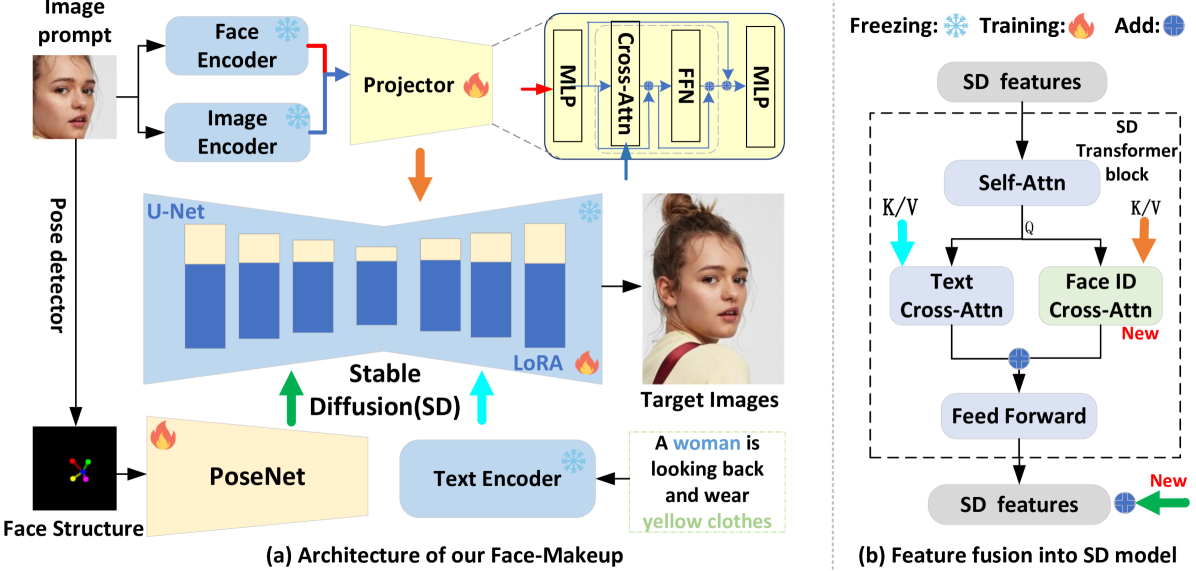
核心思路:论文的核心思路是利用参考人脸图像的多模态信息(包括内容和姿态),将其融入到文本到图像的扩散模型中,从而在生成过程中更好地保持人脸的身份特征和结构信息。通过提取参考图像的特征,并将其作为额外的条件输入,引导扩散模型生成更符合要求的面部图像。
技术框架:Face-MakeUp 的整体框架基于扩散模型,主要包含以下几个模块:1) 数据集构建:构建高质量的人脸图像-文本对数据集 FaceCaptionHQ-4M。2) 特征提取:提取参考人脸图像的多尺度内容特征和姿态特征。3) 特征融合:将提取的特征融入到扩散模型的去噪过程中,作为额外的条件信息。4) 图像生成:利用融合了多模态特征的扩散模型生成最终的人脸图像。
关键创新:论文的关键创新在于提出了多模态面部提示的概念,并设计了一种有效的方法将图像提示(内容和姿态特征)融入到文本到图像的扩散模型中。这种方法能够更好地保持人脸的身份特征,并实现更精细的控制。与现有方法相比,Face-MakeUp 能够生成更逼真、更符合要求的面部图像。
关键设计:论文的关键设计包括:1) 多尺度内容特征提取:使用预训练的卷积神经网络提取不同尺度的特征,以捕捉人脸图像的不同层次的信息。2) 姿态特征提取:使用人脸关键点检测器提取人脸的姿态信息,并将其编码为特征向量。3) 特征融合方式:采用自适应的方式将提取的特征融入到扩散模型的去噪过程中,以平衡文本提示和图像提示的影响。
🖼️ 关键图片

📊 实验亮点
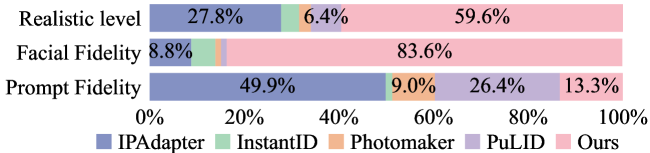
Face-MakeUp 在两个与人脸相关的测试数据集上进行了验证,实验结果表明,该方法在人脸生成质量、身份保持和文本相关性等方面均取得了最佳的综合性能。相较于现有方法,Face-MakeUp 能够生成更逼真、更符合要求的面部图像,并在定量指标和视觉效果上均有显著提升。具体性能数据未知,但论文强调了其综合性能的优越性。
🎯 应用场景
Face-MakeUp 技术可应用于虚拟形象定制、人脸属性编辑、照片修复、影视特效等领域。该技术能够根据用户提供的文本描述和参考图像,生成具有特定风格和属性的高质量人脸图像,具有广泛的应用前景和商业价值。未来,该技术有望在社交娱乐、游戏、广告等领域发挥重要作用。
📄 摘要(原文)
Facial images have extensive practical applications. Although the current large-scale text-image diffusion models exhibit strong generation capabilities, it is challenging to generate the desired facial images using only text prompt. Image prompts are a logical choice. However, current methods of this type generally focus on general domain. In this paper, we aim to optimize image makeup techniques to generate the desired facial images. Specifically, (1) we built a dataset of 4 million high-quality face image-text pairs (FaceCaptionHQ-4M) based on LAION-Face to train our Face-MakeUp model; (2) to maintain consistency with the reference facial image, we extract/learn multi-scale content features and pose features for the facial image, integrating these into the diffusion model to enhance the preservation of facial identity features for diffusion models. Validation on two face-related test datasets demonstrates that our Face-MakeUp can achieve the best comprehensive performance.All codes are available at:https://github.com/ddw2AIGROUP2CQUPT/Face-MakeUp