FOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
作者: Haicheng Wang, Zhemeng Yu, Gabriele Spadaro, Chen Ju, Victor Quétu, Shuai Xiao, Enzo Tartaglione
分类: cs.CV
发布日期: 2025-01-05 (更新: 2025-04-10)
💡 一句话要点
FOLDER:通过增强性能加速多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token减少 模型加速 信息保留 计算效率 实时应用 性能提升
📋 核心要点
- 现有的多模态大语言模型处理长视觉token序列时,计算和内存开销巨大,限制了其在实时应用中的部署。
- FOLDER模块通过减少视觉token序列的长度,降低计算和内存需求,同时尽量保留关键信息,减少信息损失。
- 实验表明,FOLDER能显著加速MLLM的推理速度,并能在训练时作为加速器或性能提升器,同时减少高达70%的视觉token。
📝 摘要(中文)
多模态大语言模型(MLLMs)由于其生成和理解跨模态数据的能力,在多模态任务中表现出卓越的有效性。然而,处理从视觉骨干网络提取的长视觉token序列对实时应用部署提出了挑战。为了解决这个问题,我们引入了FOLDER,一个简单而有效的即插即用模块,旨在减少视觉token序列的长度,从而减轻训练和推理过程中的计算和内存需求。通过对token减少过程的全面分析,我们分析了不同减少策略引入的信息损失,并开发了FOLDER以在消除视觉冗余的同时保留关键信息。我们通过将FOLDER集成到多个MLLM的视觉骨干网络中,展示了其有效性,从而显著加速了推理阶段。此外,我们评估了它作为MLLM的训练加速器甚至性能提升器的效用。在这两种情况下,FOLDER都实现了与原始模型相当甚至更好的性能,同时通过消除高达70%的视觉token来显著降低复杂性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)处理长视觉token序列时面临的计算和内存瓶颈问题。现有方法在处理大量视觉token时效率低下,限制了MLLMs在实时应用中的部署。
核心思路:论文的核心思路是通过减少视觉token的数量来降低计算和内存需求,同时尽可能保留关键信息。FOLDER模块通过分析不同token减少策略的信息损失,旨在消除视觉冗余,保留对模型性能至关重要的信息。
技术框架:FOLDER作为一个即插即用模块,可以集成到MLLMs的视觉骨干网络中。其主要流程包括:1) 接收视觉骨干网络提取的视觉token序列;2) 使用特定的token减少策略(具体策略未知)减少token数量;3) 将减少后的token序列传递给后续的MLLM模块。
关键创新:FOLDER的关键创新在于其在减少视觉token数量的同时,能够有效保留关键信息。通过分析不同token减少策略的信息损失,FOLDER能够自适应地选择合适的策略,从而在降低计算复杂度的同时,保持甚至提升模型性能。
关键设计:论文中并未详细描述FOLDER模块内部的关键设计细节,例如具体的token减少策略、损失函数或网络结构。但是,强调了FOLDER作为一个即插即用模块的通用性,可以方便地集成到不同的MLLMs中。具体的参数设置和网络结构等细节未知。
🖼️ 关键图片

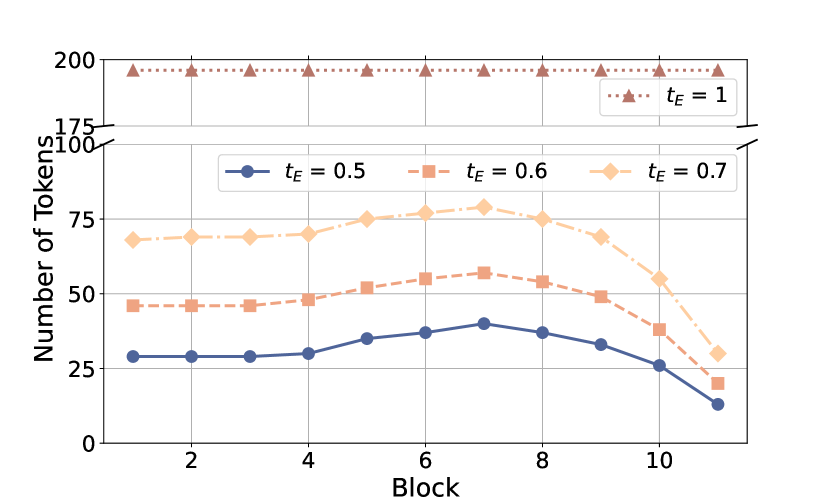

📊 实验亮点
实验结果表明,FOLDER能够显著加速MLLMs的推理速度,同时在训练过程中作为加速器或性能提升器。通过消除高达70%的视觉token,FOLDER在保持甚至提升模型性能的同时,显著降低了计算复杂度。具体的性能数据和对比基线在摘要中未提供,需要查阅原文。
🎯 应用场景
FOLDER模块具有广泛的应用前景,可用于加速各种多模态大语言模型的推理和训练过程。尤其适用于对实时性要求较高的应用场景,如智能监控、自动驾驶、机器人导航等。通过降低计算和内存需求,FOLDER有望推动MLLMs在资源受限设备上的部署,并促进多模态人工智能技术的普及。
📄 摘要(原文)
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.