AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
作者: Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha
分类: cs.CV, cs.AI
发布日期: 2025-01-03
💡 一句话要点
AVTrustBench:评估并提升音视频大语言模型的可靠性和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频理解 多模态学习 大语言模型 鲁棒性 可信度评估 对抗攻击 组合推理
📋 核心要点
- 现有MLLM基准侧重视觉评估,忽略了音视频的整体理解和模型在扰动下的校准能力。
- 提出AVTrustBench基准,包含60万样本和9个任务,从三个维度评估AVLLM的可信度。
- 提出CAVPref训练策略,通过校准音视频偏好优化,显著提升了模型的鲁棒性和可靠性。
📝 摘要(中文)
随着多模态大语言模型(MLLMs)的快速发展,涌现出多个诊断基准来评估这些模型的多模态推理能力。然而,这些基准主要集中于评估视觉方面,忽略了对整体音视频(AV)理解的考察。此外,目前缺乏针对AVLLMs在面对扰动输入时校准其响应能力的基准。为此,我们提出了音视频可信度评估基准(AVTrustBench),包含60万个样本,涵盖9个精心设计的任务,从对抗攻击、组合推理和模态特定依赖三个维度评估AVLLMs的能力。我们使用该基准广泛评估了13个最先进的AVLLMs。结果表明,现有模型在实现类人理解方面存在显著不足,为未来的研究方向提供了有价值的见解。为了缓解现有方法的局限性,我们进一步提出了一种鲁棒的、模型无关的基于校准音视频偏好优化的训练策略CAVPref,在所有9个任务中获得了高达30.19%的增益。我们将公开发布我们的代码和基准,以促进未来在该方向的研究。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLMs)在音视频理解方面存在不足,尤其是在处理对抗性攻击、进行组合推理以及理解模态特定依赖关系时。现有的基准测试主要集中在视觉方面,缺乏对音视频同步理解能力的全面评估,并且没有考虑到模型在面对噪声或恶意扰动时的鲁棒性和可信度问题。
核心思路:本文的核心思路是构建一个全面的音视频可信度评估基准(AVTrustBench),并提出一种新的训练策略(CAVPref)来提升模型的鲁棒性和可靠性。AVTrustBench旨在通过精心设计的任务来测试模型在不同场景下的音视频理解能力,而CAVPref则通过校准音视频偏好来优化模型的训练过程,使其能够更好地处理各种挑战。
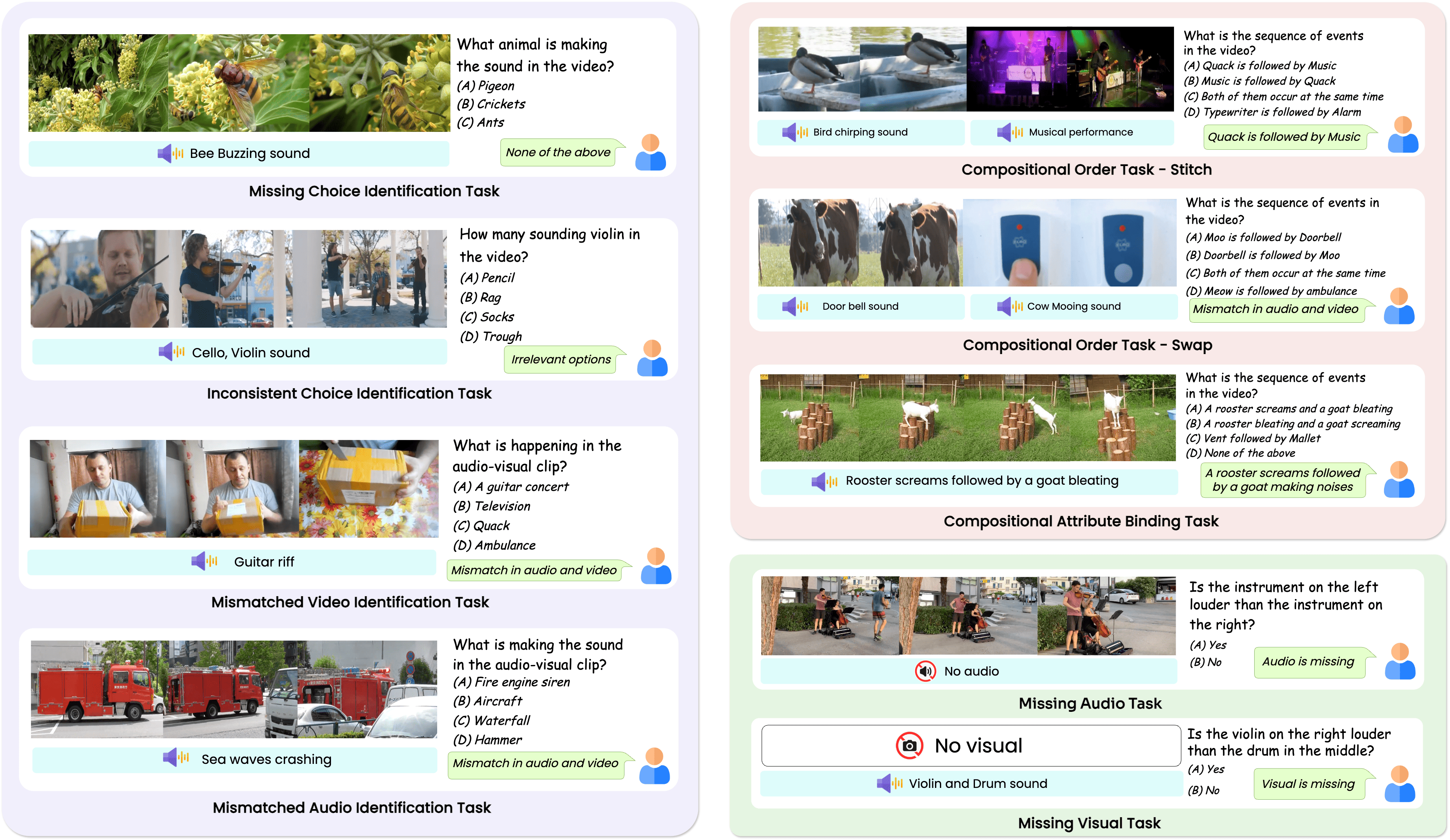
技术框架:AVTrustBench包含60万个样本,涵盖9个精心设计的任务,这些任务旨在评估AVLLMs在三个关键维度上的能力:对抗攻击(Adversarial attack)、组合推理(Compositional reasoning)和模态特定依赖(Modality-specific dependency)。CAVPref是一种模型无关的训练策略,它通过校准音视频偏好来优化模型的训练过程。具体来说,它利用偏好学习的方法,让模型学习到在不同情况下应该更加关注哪个模态的信息,从而提高其鲁棒性和可靠性。
关键创新:该论文的关键创新在于提出了AVTrustBench基准,这是第一个专门用于评估音视频大语言模型可信度的基准。此外,CAVPref训练策略也是一个重要的创新,它通过校准音视频偏好来提高模型的鲁棒性和可靠性,而无需对模型结构进行修改。
关键设计:AVTrustBench中的9个任务涵盖了各种不同的音视频理解场景,例如,对抗攻击任务旨在测试模型在面对恶意扰动时的鲁棒性,组合推理任务旨在测试模型对复杂场景的理解能力,模态特定依赖任务旨在测试模型对不同模态之间关系的理解能力。CAVPref训练策略的关键在于如何定义和学习音视频偏好。具体来说,作者使用了一种基于排序的损失函数来训练模型,使其能够区分不同音视频组合的优劣,并学习到在不同情况下应该更加关注哪个模态的信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的AVLLMs在AVTrustBench上的表现远低于人类水平,表明音视频理解仍有很大的提升空间。通过应用CAVPref训练策略,模型在所有9个任务上都获得了显著的性能提升,最高提升幅度达到30.19%,验证了该方法的有效性。这些结果为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、人机交互等领域。通过提升音视频大语言模型的可靠性和鲁棒性,可以提高这些系统在复杂环境下的性能和安全性。例如,在自动驾驶中,模型需要准确理解车辆周围的音视频信息,以做出正确的决策。该研究还可以促进多模态学习和可信人工智能的发展。
📄 摘要(原文)
With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.