DreamMask: Boosting Open-vocabulary Panoptic Segmentation with Synthetic Data
作者: Yuanpeng Tu, Xi Chen, Ser-Nam Lim, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-01-03 (更新: 2025-05-28)
备注: Accepted by SIGGRAPH2025 Project url: https://yuanpengtu.github.io/Dreammask-Page/
💡 一句话要点
DreamMask:利用合成数据提升开放词汇全景分割性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇全景分割 合成数据 数据生成 领域自适应 深度学习
📋 核心要点
- 现有开放词汇全景分割方法在新类别上的泛化能力不足,限制了其在实际场景中的应用。
- DreamMask提出了一种自动数据生成流程,并设计了合成-真实对齐损失,以弥合数据差距。
- 实验表明,DreamMask显著提升了模型在开放词汇全景分割任务上的性能,例如在ADE20K上提升了2.1% mIoU。
📝 摘要(中文)
开放词汇全景分割因其在现实世界中的适用性而备受关注。尽管之前的研究声称具有强大的泛化能力,但我们发现其性能提升主要归功于训练过的类别,暴露出对新类别的泛化能力不足。本文从数据中心角度出发,探索如何提升现有模型。我们提出了DreamMask,系统地探索如何在开放词汇设置中生成训练数据,以及如何使用真实数据和合成数据训练模型。对于数据生成部分,我们提出了一个使用现有模型的自动数据生成流程,并为词汇扩展、布局安排和数据过滤等提出了关键设计。配备这些技术后,我们生成的数据显著优于手动收集的网络数据。为了使用生成的数据训练模型,我们设计了一个合成-真实对齐损失来弥合表征差距,从而在多个基准测试中带来显著改进。总的来说,DreamMask显著简化了大规模训练数据的收集,可作为现有方法的即插即用增强。例如,在COCO上训练并在ADE20K上测试时,配备DreamMask的模型比之前的最先进方法提高了2.1% mIoU。
🔬 方法详解
问题定义:开放词汇全景分割旨在对图像中的所有像素进行语义类别和实例分割,难点在于模型需要识别和分割训练集中未见过的类别。现有方法虽然在已训练类别上表现良好,但对新类别的泛化能力较差,主要原因是缺乏包含丰富新类别标注的大规模训练数据。人工标注成本高昂,难以满足需求。
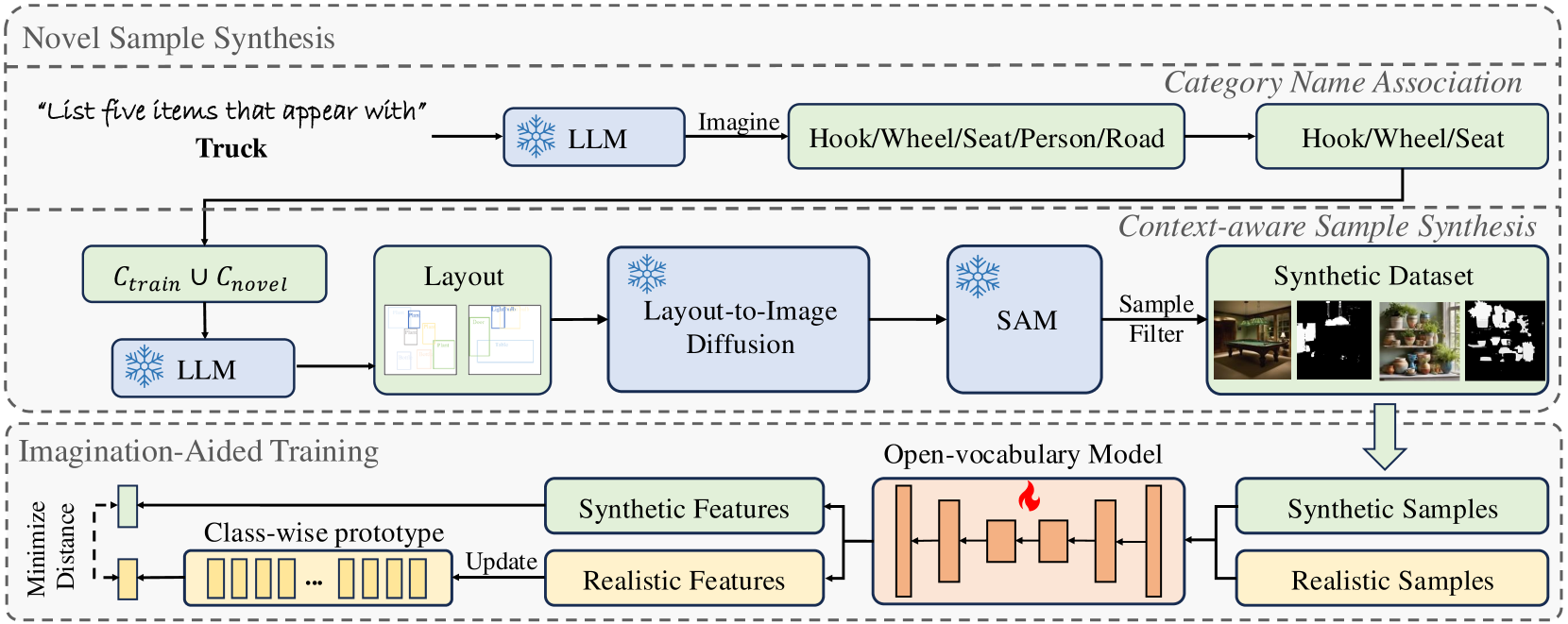
核心思路:DreamMask的核心思路是利用合成数据来扩充训练集,从而提高模型对新类别的泛化能力。通过自动化的数据生成流程,可以低成本地创建包含各种新类别和场景的合成图像,并结合真实数据进行训练。关键在于如何生成高质量的合成数据,以及如何弥合合成数据和真实数据之间的差距。
技术框架:DreamMask包含两个主要阶段:数据生成和模型训练。数据生成阶段,首先进行词汇扩展,确定需要生成的新类别。然后,利用现成的模型(如文本到图像生成模型)生成包含这些类别的图像片段。接着,进行布局安排,将这些图像片段组合成完整的合成图像。最后,进行数据过滤,筛选掉质量较差的合成图像。在模型训练阶段,将合成数据和真实数据混合,并使用合成-真实对齐损失来训练模型。
关键创新:DreamMask的关键创新在于提出了一种自动化的、可控的合成数据生成流程,并设计了合成-真实对齐损失。与以往依赖人工标注或简单数据增强的方法不同,DreamMask能够系统地生成包含丰富新类别的合成数据,从而显著提高模型对新类别的泛化能力。合成-真实对齐损失能够有效地弥合合成数据和真实数据之间的表征差距,进一步提升模型性能。
关键设计:在数据生成阶段,采用了多种策略来提高合成数据的质量,例如使用高质量的文本到图像生成模型,进行精细的布局安排,以及使用图像质量评估指标进行数据过滤。在模型训练阶段,合成-真实对齐损失的设计至关重要,它通过最小化合成数据和真实数据在特征空间的距离,来提高模型的泛化能力。具体的损失函数形式未知,但其目标是使模型能够更好地利用合成数据中的信息。
🖼️ 关键图片


📊 实验亮点
DreamMask在多个基准测试中取得了显著的性能提升。例如,在COCO上训练并在ADE20K上测试时,配备DreamMask的模型比之前的最先进方法提高了2.1% mIoU。实验结果表明,DreamMask能够有效地提高模型对新类别的泛化能力,并且可以作为现有方法的即插即用增强。
🎯 应用场景
DreamMask在机器人、自动驾驶、图像编辑等领域具有广泛的应用前景。例如,在机器人领域,它可以帮助机器人识别和操作未见过的物体。在自动驾驶领域,它可以提高自动驾驶系统对新场景和新物体的感知能力。在图像编辑领域,它可以用于生成逼真的图像合成效果。该研究降低了开放词汇全景分割对大规模标注数据的依赖,为相关领域的发展提供了新的思路。
📄 摘要(原文)
Open-vocabulary panoptic segmentation has received significant attention due to its applicability in the real world. Despite claims of robust generalization, we find that the advancements of previous works are attributed mainly on trained categories, exposing a lack of generalization to novel classes. In this paper, we explore boosting existing models from a data-centric perspective. We propose DreamMask, which systematically explores how to generate training data in the open-vocabulary setting, and how to train the model with both real and synthetic data. For the first part, we propose an automatic data generation pipeline with off-the-shelf models. We propose crucial designs for vocabulary expansion, layout arrangement, data filtering, etc. Equipped with these techniques, our generated data could significantly outperform the manually collected web data. To train the model with generated data, a synthetic-real alignment loss is designed to bridge the representation gap, bringing noticeable improvements across multiple benchmarks. In general, DreamMask significantly simplifies the collection of large-scale training data, serving as a plug-and-play enhancement for existing methods. For instance, when trained on COCO and tested on ADE20K, the model equipped with DreamMask outperforms the previous state-of-the-art by a substantial margin of 2.1% mIoU.