VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
作者: Wenyan Cong, Hanqing Zhu, Kevin Wang, Jiahui Lei, Colton Stearns, Yuanhao Cai, Leonidas Guibas, Zhangyang Wang, Zhiwen Fan
分类: cs.CV
发布日期: 2025-01-03 (更新: 2025-07-07)
备注: project page: https://videolifter.github.io
💡 一句话要点
VideoLifter:利用快速分层立体对齐将视频提升为3D模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频3D重建 单目视频 分层重建 3D高斯 场景理解
📋 核心要点
- 现有单目视频3D重建方法计算开销大,且易累积误差,难以扩展到长视频。
- VideoLifter采用局部到全局的策略,先利用3D先验进行局部片段重建,再分层合并片段。
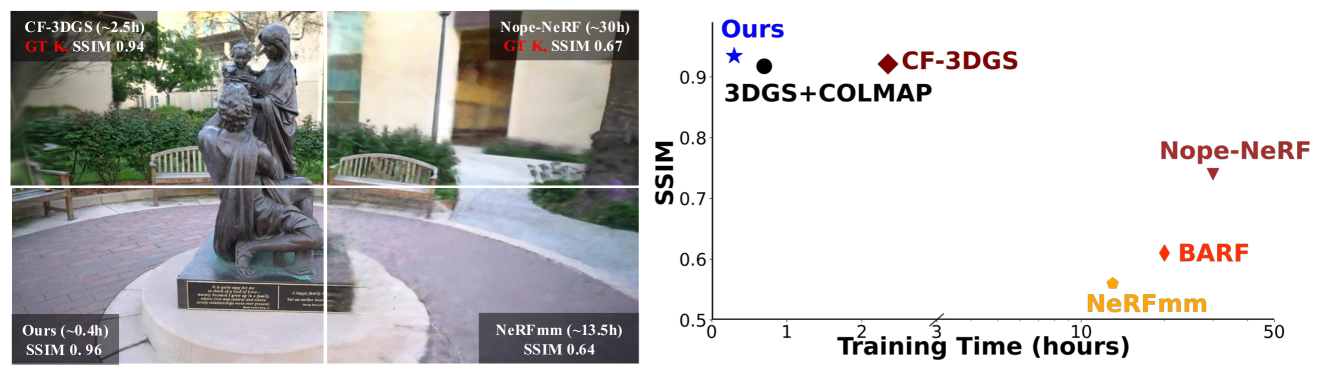
- 实验表明,VideoLifter在保证视觉质量的同时,训练时间减少了82%以上,效率显著提升。
📝 摘要(中文)
从单目视频中高效重建3D场景是计算机视觉领域的核心挑战,对于虚拟现实、机器人和场景理解等应用至关重要。目前,逐帧渐进式重建方法在无需相机位姿的情况下被广泛采用,但当视频长度增加时,会产生较高的计算开销和累积误差。为了解决这些问题,我们提出了VideoLifter,一种新颖的视频到3D重建流程,它利用基于片段的局部到全局策略,实现了极高的效率和最先进的质量。在局部,VideoLifter利用可学习的3D先验来注册片段,提取必要的信息,用于后续的3D高斯初始化,并强制片段间的一致性,优化效率。在全局,它采用基于树的分层合并方法,利用关键帧引导进行片段间对齐,通过高斯点剪枝进行两两合并,并进行后续的联合优化,以确保全局一致性,同时有效地减轻累积误差。这种方法显著加速了重建过程,在保持比当前SOTA方法更好的视觉质量的同时,将训练时间减少了82%以上。
🔬 方法详解
问题定义:论文旨在解决单目视频3D重建中,现有方法计算效率低、易累积误差的问题,尤其是在处理长视频时,逐帧重建的策略会导致计算量线性增长,且误差会随着帧数的增加而累积,最终影响重建质量。
核心思路:VideoLifter的核心思路是将视频分割成多个片段,首先在局部片段内进行高效的3D重建,然后通过分层合并的方式将这些片段对齐并融合,从而避免了逐帧重建带来的计算负担和误差累积。这种局部到全局的策略允许模型在局部保持高效率,并在全局保持一致性。
技术框架:VideoLifter的整体框架包含两个主要阶段:局部片段重建和全局分层合并。在局部片段重建阶段,模型利用可学习的3D先验知识,对每个片段进行3D高斯初始化,并强制片段间的一致性。在全局分层合并阶段,模型采用基于树的分层结构,利用关键帧引导进行片段间的两两合并,并通过高斯点剪枝来减少计算量,最后进行联合优化以保证全局一致性。
关键创新:VideoLifter的关键创新在于其局部到全局的分层重建策略,以及在每个阶段所采用的高效算法。具体来说,利用可学习的3D先验进行局部片段重建,可以快速提取片段的3D信息;而分层合并策略则可以有效地减轻误差累积,并显著提高重建效率。
关键设计:VideoLifter的关键设计包括:1) 可学习的3D先验,用于初始化局部片段的3D结构;2) 基于树的分层合并结构,用于高效地对齐和融合片段;3) 高斯点剪枝策略,用于减少合并过程中的计算量;4) 联合优化方法,用于保证全局一致性。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
VideoLifter在重建效率上取得了显著提升,训练时间比当前SOTA方法减少了82%以上。同时,在视觉质量方面,VideoLifter也优于现有方法,能够生成更准确、更逼真的3D模型。具体的量化指标和对比结果在论文中有详细展示(未知)。
🎯 应用场景
VideoLifter在虚拟现实、机器人和场景理解等领域具有广泛的应用前景。例如,它可以用于快速构建VR/AR场景,为机器人提供准确的环境感知,以及帮助计算机更好地理解和分析视频内容。该研究的突破将推动相关领域的发展,并为未来的研究提供新的思路。
📄 摘要(原文)
Efficiently reconstructing 3D scenes from monocular video remains a core challenge in computer vision, vital for applications in virtual reality, robotics, and scene understanding. Recently, frame-by-frame progressive reconstruction without camera poses is commonly adopted, incurring high computational overhead and compounding errors when scaling to longer videos. To overcome these issues, we introduce VideoLifter, a novel video-to-3D pipeline that leverages a local-to-global strategy on a fragment basis, achieving both extreme efficiency and SOTA quality. Locally, VideoLifter leverages learnable 3D priors to register fragments, extracting essential information for subsequent 3D Gaussian initialization with enforced inter-fragment consistency and optimized efficiency. Globally, it employs a tree-based hierarchical merging method with key frame guidance for inter-fragment alignment, pairwise merging with Gaussian point pruning, and subsequent joint optimization to ensure global consistency while efficiently mitigating cumulative errors. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while holding better visual quality than current SOTA methods.