MoEE: Mixture of Emotion Experts for Audio-Driven Portrait Animation
作者: Huaize Liu, Wenzhang Sun, Donglin Di, Shibo Sun, Jiahui Yang, Changqing Zou, Hujun Bao
分类: cs.CV
发布日期: 2025-01-03 (更新: 2025-01-09)
💡 一句话要点
提出MoEE模型和DH-FaceEmoVid-150数据集,用于生成具有复杂情感的音频驱动人像动画。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频驱动 人像动画 情感建模 混合专家 多模态融合
📋 核心要点
- 现有方法缺乏对单一基本情感表达建模的框架,限制了复合情感等复杂情感的生成。
- 论文提出混合情感专家(MoEE)模型,解耦基本情感,实现单一和复合情感的精确合成。
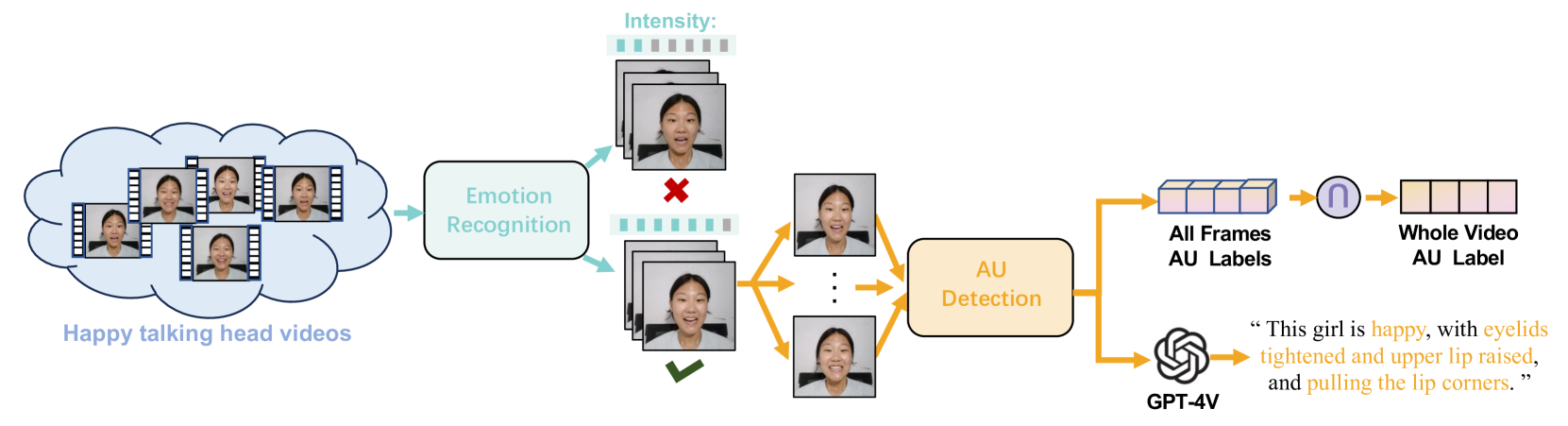
- 构建DH-FaceEmoVid-150数据集,包含基本和复合情感,并结合MoEE模型,显著提升情感表达效果。
📝 摘要(中文)
本文针对现有音频驱动人像动画方法在捕捉广泛情感和细微面部表情方面的不足,提出了两项创新:一是混合情感专家(MoEE)模型,该模型解耦了六种基本情感,从而能够精确合成单一和复合情感状态;二是DH-FaceEmoVid-150数据集,该数据集专门包含六种常见的人类情感表达以及四种复合情感,从而扩展了情感驱动模型的训练潜力。此外,为了增强情感控制的灵活性,本文提出了一种情感到潜在空间模块,该模块利用多模态输入,对齐音频、文本和标签等多种控制信号,以确保更多样化的控制输入以及仅使用音频控制情感的能力。通过广泛的定量和定性评估,证明了MoEE框架与DH-FaceEmoVid-150数据集相结合,在生成复杂情感表达和细致面部细节方面表现出色,为该领域树立了新的基准。这些数据集将公开发布。
🔬 方法详解
问题定义:现有音频驱动人像动画方法难以生成具有丰富情感和细微表情的逼真视频。主要痛点在于缺乏对基本情感的有效建模,以及缺乏包含足够情感表达的数据集,导致模型难以生成复杂的情感。
核心思路:论文的核心思路是将复杂情感的生成分解为对基本情感的组合。通过解耦六种基本情感,并使用混合专家模型(MoEE)来学习这些基本情感的表达,从而能够灵活地合成各种单一和复合情感。同时,构建包含丰富情感表达的数据集,为模型训练提供充足的数据支撑。
技术框架:整体框架包含三个主要模块:1) 音频特征提取模块,用于提取音频中的情感相关特征;2) 混合情感专家(MoEE)模块,该模块包含多个专家网络,每个专家网络负责学习一种基本情感的表达,通过混合这些专家网络的输出,可以生成各种情感表达;3) 渲染模块,用于将情感表达转化为最终的人像动画视频。此外,还包含一个情感到潜在空间模块,用于将不同的控制信号(如音频、文本、标签)映射到统一的潜在空间,从而实现多模态情感控制。
关键创新:最重要的技术创新点在于混合情感专家(MoEE)模型。与现有方法直接学习复杂情感表达不同,MoEE模型通过解耦基本情感,实现了对情感表达的更精细控制和更灵活的组合。此外,DH-FaceEmoVid-150数据集的构建也为情感驱动人像动画领域提供了宝贵的数据资源。
关键设计:MoEE模型中,每个专家网络可以采用不同的网络结构,例如卷积神经网络或Transformer网络,以适应不同情感的表达特点。损失函数的设计需要考虑情感分类的准确性以及生成视频的逼真度。情感到潜在空间模块可以使用对比学习等方法,确保不同模态的控制信号能够映射到语义一致的潜在空间。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MoEE模型在生成复杂情感表达和细致面部细节方面优于现有方法。通过定量评估,MoEE模型在情感分类准确率和生成视频的逼真度方面均取得了显著提升。与基线方法相比,MoEE模型能够生成更自然、更富有表现力的人像动画视频。
🎯 应用场景
该研究成果可应用于虚拟主播、数字人、游戏角色动画、情感化语音助手等领域。通过精确控制人像的情感表达,可以提升用户交互的真实感和沉浸感,增强用户体验。未来,该技术还可应用于心理健康评估、情感识别等领域。
📄 摘要(原文)
The generation of talking avatars has achieved significant advancements in precise audio synchronization. However, crafting lifelike talking head videos requires capturing a broad spectrum of emotions and subtle facial expressions. Current methods face fundamental challenges: a) the absence of frameworks for modeling single basic emotional expressions, which restricts the generation of complex emotions such as compound emotions; b) the lack of comprehensive datasets rich in human emotional expressions, which limits the potential of models. To address these challenges, we propose the following innovations: 1) the Mixture of Emotion Experts (MoEE) model, which decouples six fundamental emotions to enable the precise synthesis of both singular and compound emotional states; 2) the DH-FaceEmoVid-150 dataset, specifically curated to include six prevalent human emotional expressions as well as four types of compound emotions, thereby expanding the training potential of emotion-driven models. Furthermore, to enhance the flexibility of emotion control, we propose an emotion-to-latents module that leverages multimodal inputs, aligning diverse control signals-such as audio, text, and labels-to ensure more varied control inputs as well as the ability to control emotions using audio alone. Through extensive quantitative and qualitative evaluations, we demonstrate that the MoEE framework, in conjunction with the DH-FaceEmoVid-150 dataset, excels in generating complex emotional expressions and nuanced facial details, setting a new benchmark in the field. These datasets will be publicly released.