LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction
作者: Er Jin, Qihui Feng, Yongli Mou, Stefan Decker, Gerhard Lakemeyer, Oliver Simons, Johannes Stegmaier
分类: cs.CV
发布日期: 2025-01-03 (更新: 2025-01-08)
备注: Accepted for publication at aaai25, project page: https://jasonjin34.github.io/logicad.github.io/
💡 一句话要点
LogicAD:基于VLM文本特征提取的可解释异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异常检测 视觉语言模型 逻辑推理 可解释性 工业质检
📋 核心要点
- 现有异常检测方法依赖先验知识,需大量标注、算力和数据,成本高昂且效率低下。
- LogicAD利用视觉语言模型(VLM)强大的视觉推理能力,结合格式嵌入和逻辑推理器进行异常检测。
- 在MVTec LOCO AD数据集上,LogicAD的AUROC达到86.0%,F1-max达到83.7%,显著超越现有最佳方法。
📝 摘要(中文)
逻辑图像理解涉及对图像视觉内容中的关系和一致性进行解释和推理。这种能力在工业检测等应用中至关重要,在这些应用中,逻辑异常检测对于维持高质量标准和最大限度地减少代价高昂的召回至关重要。以往的异常检测(AD)研究依赖于先验知识来设计算法,这通常需要大量的手动标注、大量的计算能力和大量的数据进行训练。自回归多模态视觉语言模型(AVLMs)由于其在各种领域的视觉推理方面的卓越性能,提供了一种有希望的替代方案。尽管如此,它们在逻辑AD中的应用仍未被探索。在这项工作中,我们研究了使用AVLMs进行逻辑AD,并证明它们非常适合这项任务。通过将AVLMs与格式嵌入和逻辑推理器相结合,我们在公共基准MVTec LOCO AD上实现了SOTA性能,AUROC为86.0%,F1-max为83.7%,并提供了异常解释。这大大优于现有的SOTA方法。
🔬 方法详解
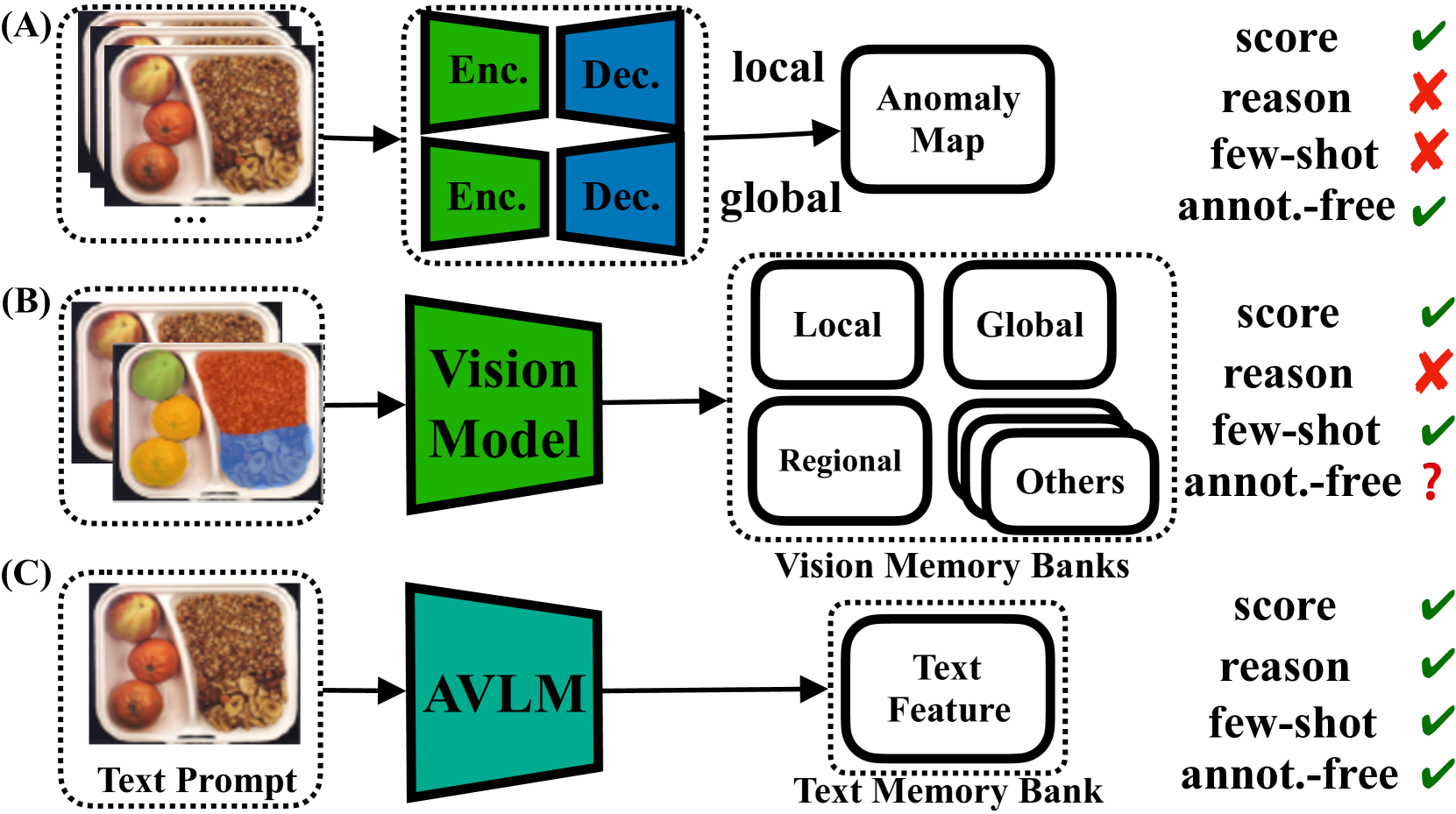
问题定义:论文旨在解决工业场景中逻辑异常检测问题,现有方法依赖大量标注数据和人工设计的特征,泛化能力差,且缺乏可解释性。这些方法难以适应复杂多变的工业环境,并且无法提供异常原因的解释,不利于问题诊断和改进。
核心思路:论文的核心思路是利用视觉语言模型(VLM)强大的视觉推理能力,将图像信息转化为文本特征,并结合逻辑推理器进行异常检测。VLM能够理解图像中的对象、属性和关系,从而实现更高级别的语义理解,无需大量标注数据即可进行有效训练。通过文本特征提取,可以将视觉信息转化为易于推理的形式,从而实现可解释的异常检测。
技术框架:LogicAD的整体框架包括三个主要模块:1)视觉语言模型(VLM):用于提取图像的文本特征,将图像信息转化为文本描述。2)格式嵌入:用于将文本特征嵌入到逻辑推理器可以理解的格式中。3)逻辑推理器:用于根据预定义的逻辑规则对文本特征进行推理,判断是否存在异常。整个流程是:输入图像 -> VLM提取文本特征 -> 格式嵌入 -> 逻辑推理 -> 异常检测结果及解释。
关键创新:该方法最重要的创新点在于将视觉语言模型应用于逻辑异常检测,并结合格式嵌入和逻辑推理器,实现了高性能和可解释性的异常检测。与传统方法相比,该方法无需大量标注数据,具有更强的泛化能力和可解释性。此外,该方法通过文本特征提取,将视觉信息转化为易于推理的形式,为异常检测提供了新的思路。
关键设计:论文中关键的设计包括:1)选择合适的视觉语言模型,例如自回归多模态视觉语言模型(AVLMs)。2)设计有效的格式嵌入方法,将文本特征嵌入到逻辑推理器可以理解的格式中。3)定义合适的逻辑规则,用于判断是否存在异常。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


📊 实验亮点
LogicAD在MVTec LOCO AD数据集上取得了显著的性能提升,AUROC达到86.0%,F1-max达到83.7%,大幅超越了现有的SOTA方法。此外,LogicAD还能够提供异常的解释,这对于问题诊断和改进具有重要意义。实验结果表明,LogicAD是一种有效且可解释的异常检测方法。
🎯 应用场景
LogicAD可应用于工业质检、医疗影像分析、安防监控等领域。在工业质检中,可用于检测产品表面的缺陷、零件缺失等异常情况,提高产品质量和生产效率。在医疗影像分析中,可用于辅助医生诊断疾病,提高诊断准确率。在安防监控中,可用于检测异常行为,提高安全防范能力。该研究具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Logical image understanding involves interpreting and reasoning about the relationships and consistency within an image's visual content. This capability is essential in applications such as industrial inspection, where logical anomaly detection is critical for maintaining high-quality standards and minimizing costly recalls. Previous research in anomaly detection (AD) has relied on prior knowledge for designing algorithms, which often requires extensive manual annotations, significant computing power, and large amounts of data for training. Autoregressive, multimodal Vision Language Models (AVLMs) offer a promising alternative due to their exceptional performance in visual reasoning across various domains. Despite this, their application to logical AD remains unexplored. In this work, we investigate using AVLMs for logical AD and demonstrate that they are well-suited to the task. Combining AVLMs with format embedding and a logic reasoner, we achieve SOTA performance on public benchmarks, MVTec LOCO AD, with an AUROC of 86.0% and F1-max of 83.7%, along with explanations of anomalies. This significantly outperforms the existing SOTA method by a large margin.