Interpretable Face Anti-Spoofing: Enhancing Generalization with Multimodal Large Language Models
作者: Guosheng Zhang, Keyao Wang, Haixiao Yue, Ajian Liu, Gang Zhang, Kun Yao, Errui Ding, Jingdong Wang
分类: cs.CV
发布日期: 2025-01-03 (更新: 2025-01-24)
备注: Accepted to AAAI2025(Oral)
💡 一句话要点
提出I-FAS:利用多模态大语言模型提升人脸反欺骗的泛化能力与可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸反欺骗 多模态大语言模型 视觉问答 可解释性 跨域泛化 欺骗感知 全局感知
📋 核心要点
- 现有的人脸反欺骗方法通常缺乏解释性,且在跨域场景下的泛化能力不足,难以应对未知的攻击类型。
- I-FAS通过将人脸反欺骗任务转化为视觉问答形式,利用多模态大语言模型提供可解释的判断依据。
- 实验表明,I-FAS在多个跨域基准测试中显著优于现有方法,证明了其优越的泛化性能。
📝 摘要(中文)
人脸反欺骗(FAS)对于确保面部识别系统的安全性和可靠性至关重要。现有的大多数FAS方法都被表述为二元分类任务,仅提供置信度分数而缺乏解释性,并且在新的环境或未见过的欺骗类型等领域外场景中泛化能力有限。本文提出了一种用于FAS的多模态大语言模型(MLLM)框架,称为可解释人脸反欺骗(I-FAS),它将FAS任务转换为可解释的视觉问答(VQA)范例。具体来说,我们提出了一种欺骗感知字幕和过滤(SCF)策略,为FAS图像生成高质量的字幕,用自然语言解释来丰富模型的监督。为了减轻训练期间噪声字幕的影响,我们开发了一种不对称语言模型(L-LM)损失函数,该函数将判断和解释的损失计算分开,优先优化前者。此外,为了增强模型对全局视觉特征的感知,我们设计了一个全局感知连接器(GAC),以将多层次的视觉表示与语言模型对齐。在标准和新设计的包含12个公共数据集的One to Eleven跨域基准上的大量实验表明,我们的方法显著优于最先进的方法。
🔬 方法详解
问题定义:现有的人脸反欺骗(FAS)方法通常被建模为二元分类问题,仅输出置信度分数,缺乏可解释性。此外,这些方法在面对新的环境或未见过的欺骗类型时,泛化能力较差,难以适应实际应用中的复杂场景。因此,如何提高FAS方法的可解释性和泛化能力是一个重要的研究问题。
核心思路:本文的核心思路是将FAS任务转化为一个可解释的视觉问答(VQA)问题。通过利用多模态大语言模型(MLLM),模型不仅可以判断输入图像是否为欺骗,还可以生成自然语言描述来解释其判断依据。这种方式能够提供更丰富的信息,并提高模型的可信度和泛化能力。
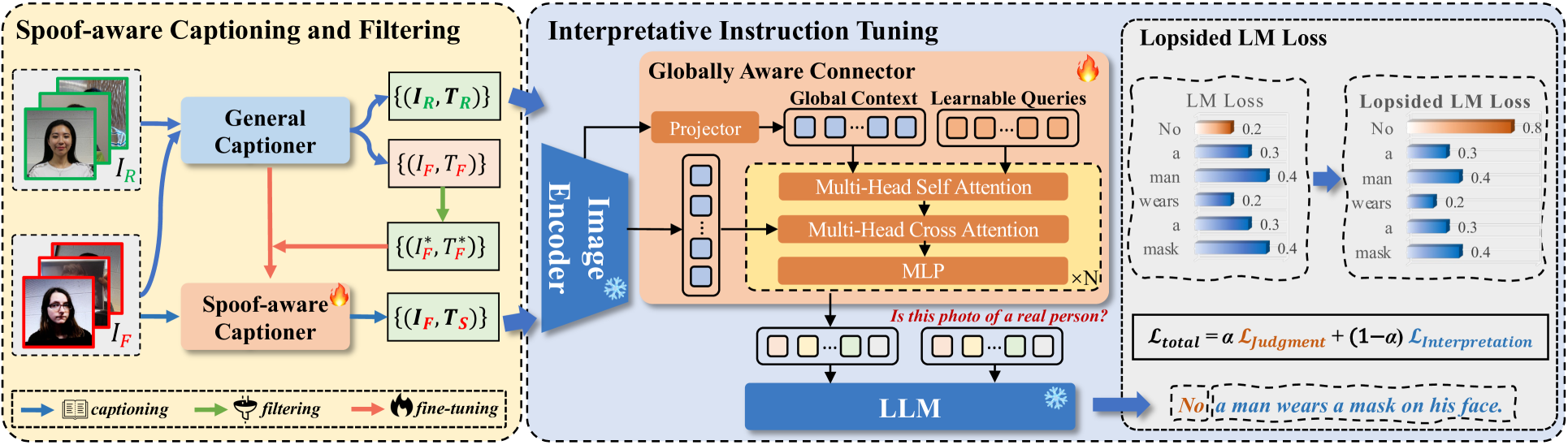
技术框架:I-FAS框架主要包含以下几个模块:1) 图像编码器:用于提取输入人脸图像的视觉特征。2) 欺骗感知字幕和过滤(SCF)模块:用于生成高质量的图像字幕,描述图像中的欺骗线索。3) 全局感知连接器(GAC):用于将多层次的视觉特征与语言模型对齐,增强模型对全局视觉信息的感知。4) 多模态大语言模型(MLLM):用于接收视觉特征和字幕信息,并生成最终的判断结果和解释。
关键创新:本文的关键创新在于以下几个方面:1) 将FAS任务转化为可解释的VQA问题,利用MLLM提供判断依据。2) 提出了欺骗感知字幕和过滤(SCF)策略,用于生成高质量的图像字幕。3) 设计了不对称语言模型(L-LM)损失函数,用于优化模型的判断准确性和解释能力。4) 引入了全局感知连接器(GAC),用于增强模型对全局视觉信息的感知。
关键设计:SCF模块通过结合人工标注和自动生成的方式,生成包含欺骗信息的图像字幕。L-LM损失函数将判断损失和解释损失分开计算,并赋予判断损失更高的权重,以保证模型的判断准确性。GAC模块利用注意力机制,将不同层次的视觉特征与语言模型进行对齐,从而增强模型对全局视觉信息的感知。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,I-FAS在多个跨域基准测试中显著优于现有方法。例如,在One to Eleven跨域基准测试中,I-FAS的性能比最先进的方法提高了显著的百分比(具体数值请参考论文)。这些结果证明了I-FAS在提高人脸反欺骗系统的泛化能力和可解释性方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要人脸识别的场景,例如移动支付、门禁系统、身份验证等。通过提高人脸反欺骗系统的安全性和可靠性,可以有效防止欺诈行为,保护用户的信息安全和财产安全。未来,该技术还可以应用于更复杂的场景,例如视频会议、远程教育等,为用户提供更安全、更便捷的服务。
📄 摘要(原文)
Face Anti-Spoofing (FAS) is essential for ensuring the security and reliability of facial recognition systems. Most existing FAS methods are formulated as binary classification tasks, providing confidence scores without interpretation. They exhibit limited generalization in out-of-domain scenarios, such as new environments or unseen spoofing types. In this work, we introduce a multimodal large language model (MLLM) framework for FAS, termed Interpretable Face Anti-Spoofing (I-FAS), which transforms the FAS task into an interpretable visual question answering (VQA) paradigm. Specifically, we propose a Spoof-aware Captioning and Filtering (SCF) strategy to generate high-quality captions for FAS images, enriching the model's supervision with natural language interpretations. To mitigate the impact of noisy captions during training, we develop a Lopsided Language Model (L-LM) loss function that separates loss calculations for judgment and interpretation, prioritizing the optimization of the former. Furthermore, to enhance the model's perception of global visual features, we design a Globally Aware Connector (GAC) to align multi-level visual representations with the language model. Extensive experiments on standard and newly devised One to Eleven cross-domain benchmarks, comprising 12 public datasets, demonstrate that our method significantly outperforms state-of-the-art methods.