MoVE-KD: Knowledge Distillation for VLMs with Mixture of Visual Encoders
作者: Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning MA, Shanghang Zhang
分类: cs.CV, cs.AI
发布日期: 2025-01-03 (更新: 2025-03-18)
备注: Accepted by CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MoVE-KD,通过知识蒸馏将多个视觉编码器的能力迁移到单个高效VLM中。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 知识蒸馏 混合专家 低秩适应 注意力机制 模型压缩 多模态学习
📋 核心要点
- 现有VLM模型为了利用不同视觉编码器的优势,集成了多个编码器,导致计算成本显著增加。
- MoVE-KD通过知识蒸馏,将多个视觉编码器的能力迁移到单个编码器,降低计算成本并保持性能。
- 实验表明,MoVE-KD在LLaVA和LLaVA-NeXT等VLM上有效,验证了其在知识迁移方面的能力。
📝 摘要(中文)
本文提出了一种混合视觉编码器知识蒸馏(MoVE-KD)的新框架,旨在将多个视觉编码器的独特能力提炼到一个单一、高效的编码器模型中。为了减轻冲突并保留每个教师编码器的独特特征,我们采用低秩适应(LoRA)和混合专家(MoEs)来基于输入特征选择性地激活专门知识,从而提高适应性和效率。为了规范化知识蒸馏过程并提高性能,我们提出了一种基于注意力的蒸馏策略,该策略自适应地权衡不同的编码器,并强调有价值的视觉token,从而减轻了复制来自多个教师的全面但不同特征的负担。在流行的视觉语言模型(VLM)如LLaVA和LLaVA-NeXT上的综合实验验证了我们方法的有效性。代码已开源。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)为了融合不同视觉基础模型的优势,通常采用多个视觉编码器,这显著增加了计算成本和模型复杂度。如何将多个视觉编码器的能力整合到一个高效的VLM中,同时保持其性能,是一个亟待解决的问题。
核心思路:MoVE-KD的核心思想是通过知识蒸馏,将多个“教师”视觉编码器的知识迁移到一个“学生”编码器中。为了避免不同教师之间的知识冲突,并保留各自的独特特征,MoVE-KD采用混合专家(MoEs)结构,并结合低秩适应(LoRA)方法,使学生模型能够根据输入特征选择性地学习不同教师的知识。
技术框架:MoVE-KD框架包含多个预训练的视觉编码器(教师模型)和一个待训练的视觉编码器(学生模型)。首先,输入图像经过所有教师模型和学生模型进行编码。然后,利用MoEs和LoRA机制,学生模型选择性地学习不同教师模型的特征表示。最后,通过一个基于注意力的知识蒸馏策略,将教师模型的知识迁移到学生模型。
关键创新:MoVE-KD的关键创新在于其混合专家(MoEs)和低秩适应(LoRA)的结合使用,以及基于注意力的知识蒸馏策略。MoEs允许学生模型根据输入特征选择性地学习不同教师的知识,避免了知识冲突。LoRA降低了训练参数量,提高了训练效率。基于注意力的知识蒸馏策略能够自适应地权衡不同教师的贡献,并强调重要的视觉token,从而提高蒸馏效果。
关键设计:MoVE-KD的关键设计包括:1) 使用MoEs结构,其中每个专家对应一个教师模型,通过门控网络选择激活的专家;2) 使用LoRA对学生模型进行微调,降低训练成本;3) 设计基于注意力的知识蒸馏损失函数,该损失函数包括特征蒸馏损失和注意力蒸馏损失,其中注意力蒸馏损失用于对齐学生模型和教师模型的注意力图。
🖼️ 关键图片
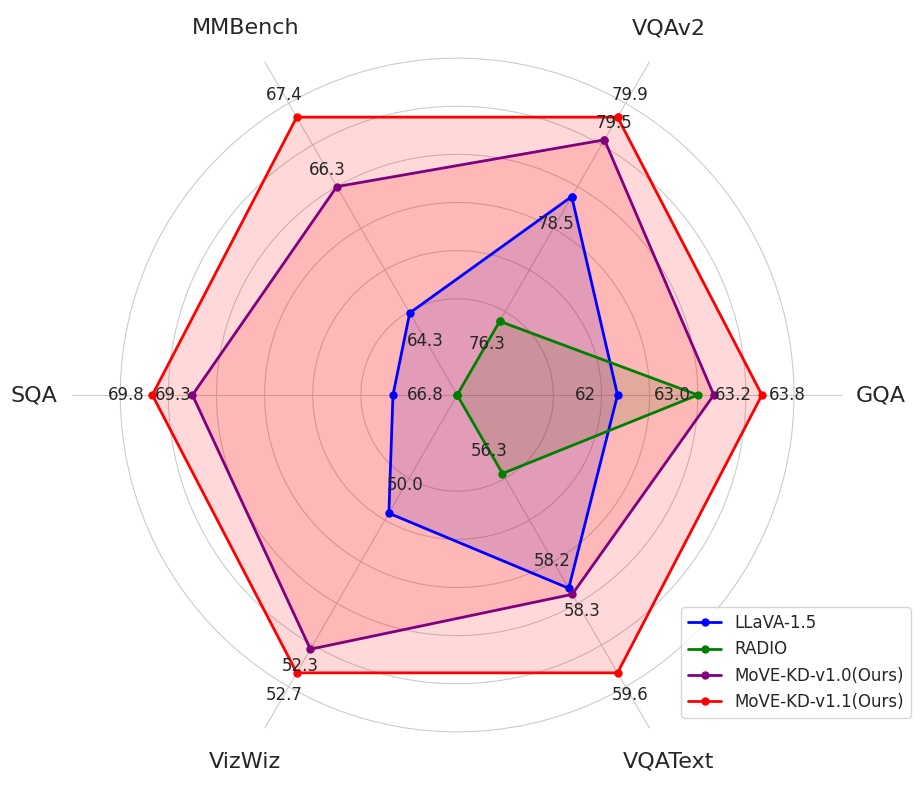

📊 实验亮点
实验结果表明,MoVE-KD在LLaVA和LLaVA-NeXT等VLM上取得了显著的性能提升。例如,在视觉问答任务中,MoVE-KD在保持甚至超过原有模型性能的同时,显著降低了计算成本。与直接使用多个视觉编码器相比,MoVE-KD在参数量和推理速度上具有明显优势。
🎯 应用场景
MoVE-KD可应用于各种需要高效视觉语言理解的任务,例如图像描述、视觉问答、视觉推理等。通过将多个视觉编码器的知识整合到一个轻量级模型中,MoVE-KD可以降低计算成本,提高部署效率,使其更适用于资源受限的设备和场景。该方法也有助于构建更强大的通用视觉语言模型。
📄 摘要(原文)
Visual encoders are fundamental components in vision-language models (VLMs), each showcasing unique strengths derived from various pre-trained visual foundation models. To leverage the various capabilities of these encoders, recent studies incorporate multiple encoders within a single VLM, leading to a considerable increase in computational cost. In this paper, we present Mixture-of-Visual-Encoder Knowledge Distillation (MoVE-KD), a novel framework that distills the unique proficiencies of multiple vision encoders into a single, efficient encoder model. Specifically, to mitigate conflicts and retain the unique characteristics of each teacher encoder, we employ low-rank adaptation (LoRA) and mixture-of-experts (MoEs) to selectively activate specialized knowledge based on input features, enhancing both adaptability and efficiency. To regularize the KD process and enhance performance, we propose an attention-based distillation strategy that adaptively weighs the different encoders and emphasizes valuable visual tokens, reducing the burden of replicating comprehensive but distinct features from multiple teachers. Comprehensive experiments on popular VLMs, such as LLaVA and LLaVA-NeXT, validate the effectiveness of our method. Our code is available at: https://github.com/hey-cjj/MoVE-KD.