Google is all you need: Semi-Supervised Transfer Learning Strategy For Light Multimodal Multi-Task Classification Model
作者: Haixu Liu, Penghao Jiang, Zerui Tao
分类: cs.CV, cs.AI
发布日期: 2025-01-03
💡 一句话要点
提出一种半监督迁移学习策略,用于轻量级多模态多任务分类模型,提升图像标签精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多标签分类 多模态融合 卷积神经网络 自然语言处理 图像标注 半监督学习 迁移学习
📋 核心要点
- 现有图像分类方法难以有效处理具有多重含义的图像,尤其是在标签数量较多时。
- 论文提出融合图像识别与自然语言处理的多模态分类器,利用文本信息增强图像理解,提升标签预测准确性。
- 实验结果初步验证了所提分类器的准确性和效率,表明其在自动图像标签系统中的应用潜力。
📝 摘要(中文)
本研究提出了一种鲁棒的多标签分类系统,旨在为单张图像分配多个标签,从而解决图像可能与多个类别相关联的复杂性问题(范围从1到19,不包括12)。我们提出了一个多模态分类器,该分类器融合了先进的图像识别算法与自然语言处理(NLP)模型,并结合了一个融合模块来整合这些不同的模态。整合文本数据的目的是通过提供仅靠视觉分析无法完全捕获的上下文理解来提高标签预测的准确性。我们提出的分类模型结合了用于图像处理的卷积神经网络(CNN)和用于分析文本描述(即标题)的NLP技术。该方法包括严格的训练和验证阶段,每个模型组件都通过消融实验进行验证和分析。初步结果表明了分类器的准确性和效率,突出了其作为自动图像标签系统的潜力。
🔬 方法详解
问题定义:论文旨在解决图像多标签分类问题,即一张图像可能对应多个标签。现有方法在处理复杂图像,特别是当图像具有多个相关标签时,准确率较低。痛点在于仅依靠图像视觉信息难以充分理解图像的语义信息,导致标签预测不准确。
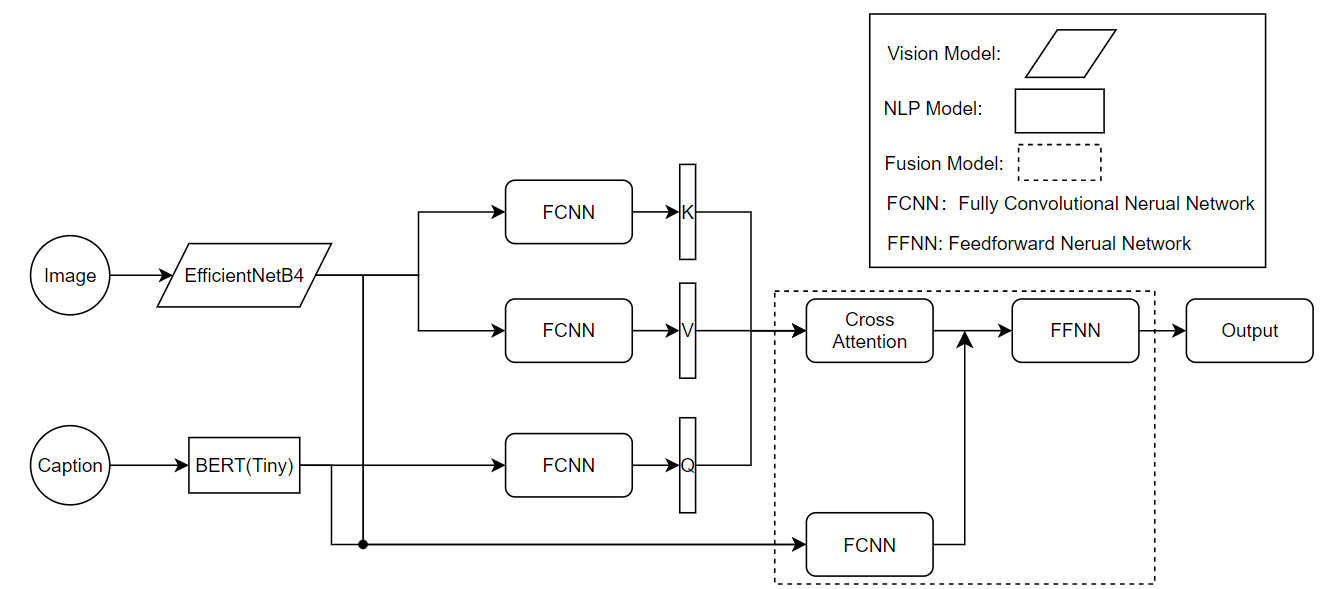
核心思路:论文的核心思路是利用多模态信息融合,将图像的视觉信息与文本描述(例如图像的标题或描述)相结合,从而更全面地理解图像的语义。通过融合图像和文本信息,模型可以更好地捕捉图像的多重含义,提高多标签分类的准确性。
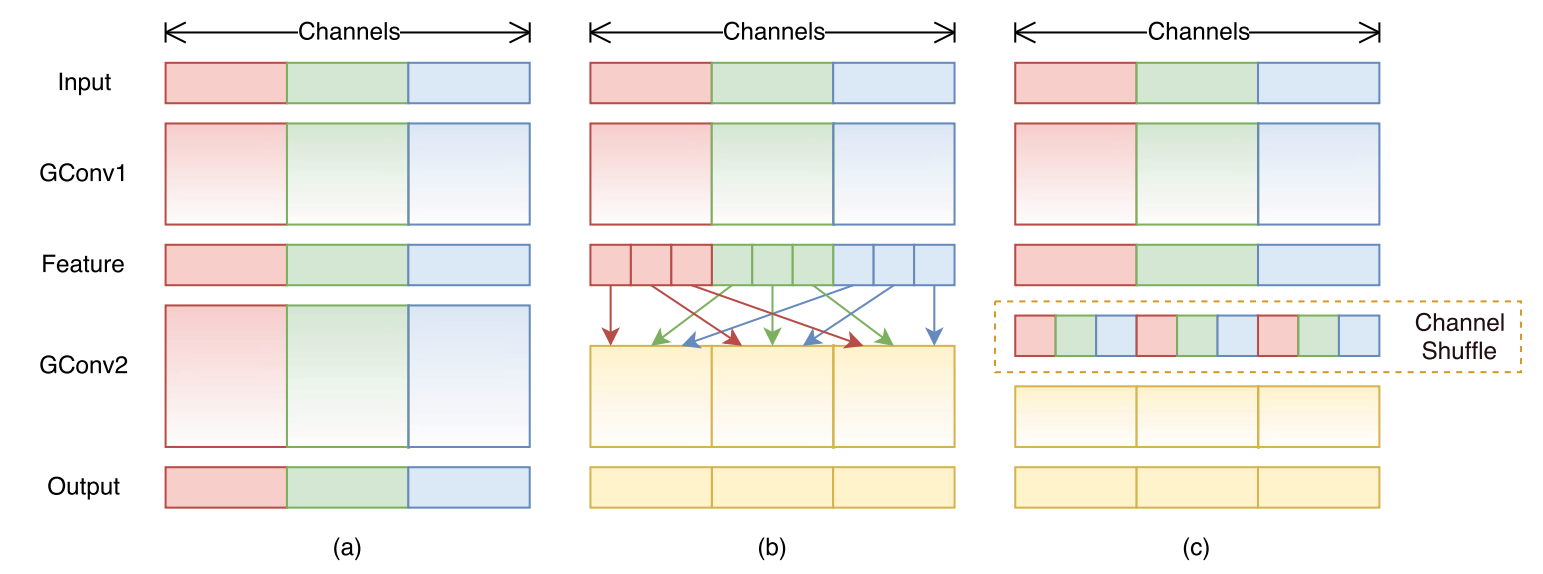
技术框架:整体框架包含图像处理模块、文本处理模块和融合模块。图像处理模块使用卷积神经网络(CNN)提取图像的视觉特征。文本处理模块使用自然语言处理(NLP)技术分析文本描述,提取文本特征。融合模块将图像特征和文本特征进行融合,得到最终的图像表示,用于多标签分类。模型经过训练和验证阶段,并使用消融实验分析每个模块的贡献。
关键创新:关键创新在于多模态信息的融合方式。论文提出了一种特定的融合模块,用于有效地整合图像和文本特征。这种融合方式能够充分利用两种模态的信息,提高分类性能。具体融合方式未知,需要进一步阅读论文细节。
关键设计:论文使用了卷积神经网络(CNN)进行图像特征提取,并使用了自然语言处理(NLP)技术进行文本特征提取。具体的CNN网络结构和NLP模型未知,需要进一步阅读论文细节。损失函数和优化算法的选择也未知,需要进一步阅读论文细节。
🖼️ 关键图片
📊 实验亮点
论文的初步实验结果表明,所提出的多模态分类器具有较高的准确性和效率。通过融合图像和文本信息,模型能够更准确地预测图像的多个标签。具体的性能数据和对比基线未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动图像标注、图像检索、内容审核等领域。例如,在电商平台上,可以自动为商品图片添加标签,方便用户搜索和浏览。在社交媒体平台上,可以自动识别图片内容,进行内容审核和推荐。该研究有助于提高图像处理的自动化程度和智能化水平。
📄 摘要(原文)
As the volume of digital image data increases, the effectiveness of image classification intensifies. This study introduces a robust multi-label classification system designed to assign multiple labels to a single image, addressing the complexity of images that may be associated with multiple categories (ranging from 1 to 19, excluding 12). We propose a multi-modal classifier that merges advanced image recognition algorithms with Natural Language Processing (NLP) models, incorporating a fusion module to integrate these distinct modalities. The purpose of integrating textual data is to enhance the accuracy of label prediction by providing contextual understanding that visual analysis alone cannot fully capture. Our proposed classification model combines Convolutional Neural Networks (CNN) for image processing with NLP techniques for analyzing textual description (i.e., captions). This approach includes rigorous training and validation phases, with each model component verified and analyzed through ablation experiments. Preliminary results demonstrate the classifier's accuracy and efficiency, highlighting its potential as an automatic image-labeling system.