D$^3$-Human: Dynamic Disentangled Digital Human from Monocular Video
作者: Honghu Chen, Bo Peng, Yunfan Tao, Juyong Zhang
分类: cs.CV, cs.GR
发布日期: 2025-01-03
备注: Project Page: https://ustc3dv.github.io/D3Human/
💡 一句话要点
D$^3$-Human:提出解耦的动态数字人重建方法,解决单目视频中服装遮挡问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 数字人重建 单目视频 解耦建模 隐式表示 显式表示
📋 核心要点
- 现有单目视频人体重建方法难以有效解耦服装与人体,限制了其在动画制作等领域的应用。
- D$^3$-Human结合显式和隐式表示,利用hmSDF分割可见服装和身体,实现解耦重建。
- 实验表明,D$^3$-Human能高质量重建穿着不同服装的人体,并可直接应用于服装迁移和动画。
📝 摘要(中文)
本文提出D$^3$-Human,一种从单目视频中重建动态解耦数字人几何体的方法。以往的单目视频人体重建主要集中于重建未解耦的服装人体或仅重建服装,难以直接应用于动画制作等应用。解耦服装和身体重建的挑战在于服装对身体的遮挡。为此,在重建过程中必须保证可见区域的细节和不可见区域的合理性。我们提出的方法结合了显式和隐式表示来建模解耦的服装人体,利用显式表示的鲁棒性和隐式表示的灵活性。具体来说,我们将可见区域重建为SDF,并提出了一种新的人体流形有符号距离场(hmSDF)来分割可见的服装和可见的身体,然后合并可见和不可见的身体。大量的实验结果表明,与现有的重建方案相比,D$^3$-Human可以实现高质量的穿着不同服装的人体的解耦重建,并且可以直接应用于服装转移和动画。
🔬 方法详解
问题定义:论文旨在解决从单目视频中重建解耦的动态数字人几何体的问题。现有的方法要么重建未解耦的服装人体,要么只重建服装,无法同时保证服装和身体的细节,并且难以应用于动画制作等需要灵活编辑的应用场景。服装对身体的遮挡是主要的技术难点。
核心思路:论文的核心思路是结合显式和隐式表示的优势,利用显式表示的鲁棒性来重建可见区域,并利用隐式表示的灵活性来推断不可见区域。通过显式表示保证可见区域的细节,通过隐式表示保证不可见区域的合理性。
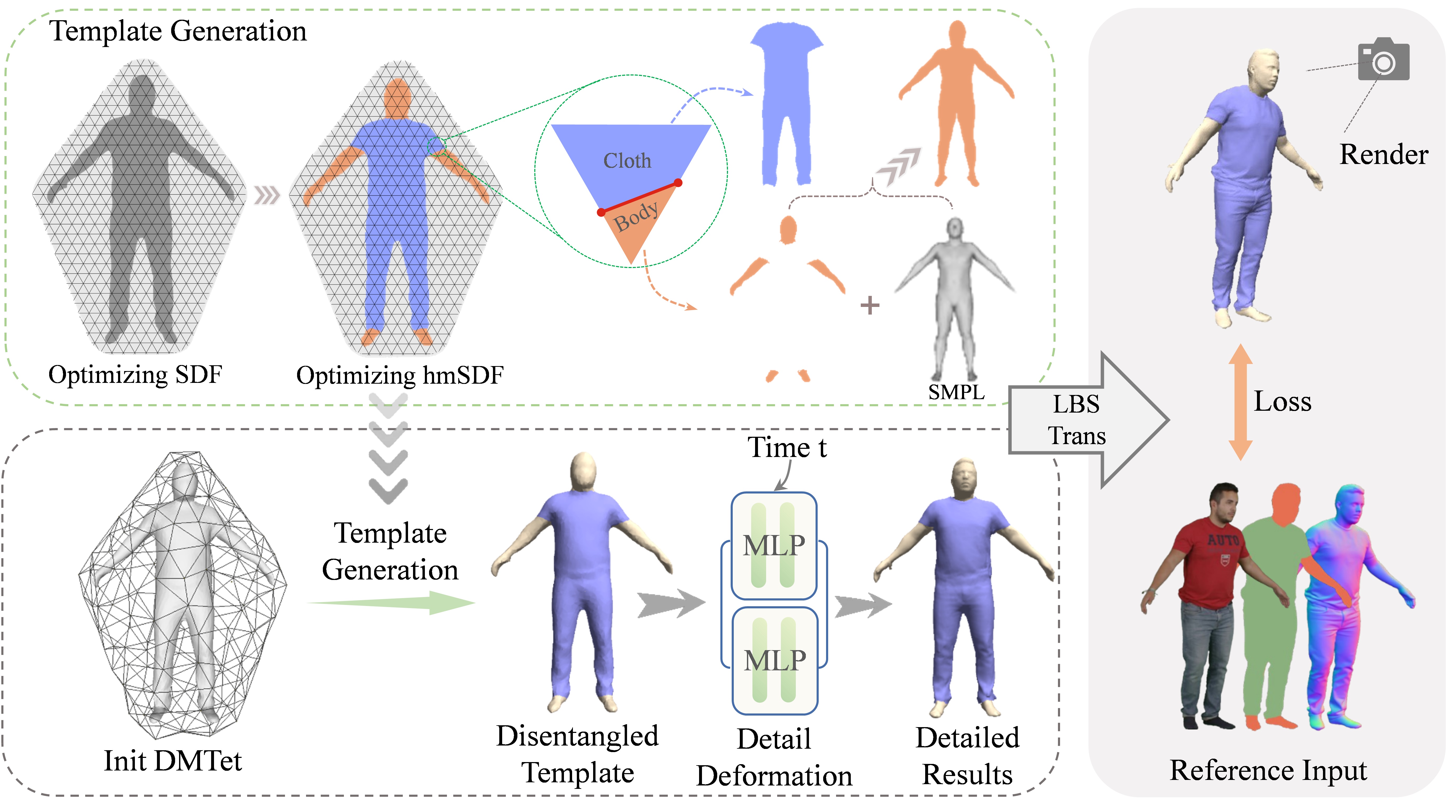
技术框架:D$^3$-Human的整体框架包括以下几个主要步骤:1. 从单目视频中提取人体姿态和轮廓。2. 将可见区域重建为有符号距离场(SDF)。3. 提出人体流形有符号距离场(hmSDF)来分割可见的服装和可见的身体。4. 将可见和不可见的身体合并,得到完整的身体模型。5. 对服装进行建模和重建。
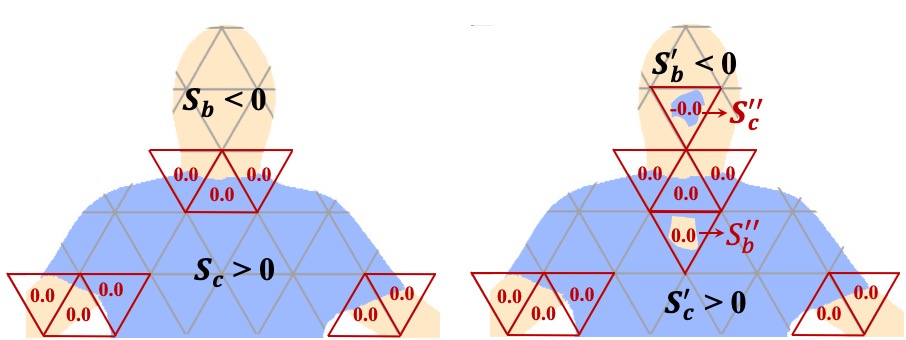
关键创新:该方法最重要的创新点在于提出了人体流形有符号距离场(hmSDF),用于分割可见的服装和可见的身体。hmSDF能够有效地利用人体先验知识,从而更准确地分割服装和身体,克服了服装遮挡带来的困难。
关键设计:hmSDF的设计是关键。具体来说,hmSDF是一个隐式函数,它将空间中的点映射到一个有符号的距离值,该值表示该点到人体流形的距离。通过训练一个神经网络来学习hmSDF,可以实现对服装和身体的分割。损失函数的设计也至关重要,需要同时考虑可见区域的重建误差和不可见区域的合理性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,D$^3$-Human在解耦服装和身体重建方面优于现有方法。与基线方法相比,D$^3$-Human能够生成更高质量的服装和身体模型,尤其是在服装细节和身体形状的准确性方面有显著提升。此外,D$^3$-Human重建的数字人可以直接应用于服装迁移和动画,验证了其在实际应用中的有效性。
🎯 应用场景
D$^3$-Human具有广泛的应用前景,例如:动画制作(角色建模、服装设计、动画生成),虚拟现实/增强现实(虚拟形象定制、互动体验),电商(虚拟试衣、服装展示),游戏开发(角色创建、服装模拟)等。该研究能够提升数字人建模的效率和质量,为相关产业带来实际价值,并推动数字人技术的进一步发展。
📄 摘要(原文)
We introduce D$^3$-Human, a method for reconstructing Dynamic Disentangled Digital Human geometry from monocular videos. Past monocular video human reconstruction primarily focuses on reconstructing undecoupled clothed human bodies or only reconstructing clothing, making it difficult to apply directly in applications such as animation production. The challenge in reconstructing decoupled clothing and body lies in the occlusion caused by clothing over the body. To this end, the details of the visible area and the plausibility of the invisible area must be ensured during the reconstruction process. Our proposed method combines explicit and implicit representations to model the decoupled clothed human body, leveraging the robustness of explicit representations and the flexibility of implicit representations. Specifically, we reconstruct the visible region as SDF and propose a novel human manifold signed distance field (hmSDF) to segment the visible clothing and visible body, and then merge the visible and invisible body. Extensive experimental results demonstrate that, compared with existing reconstruction schemes, D$^3$-Human can achieve high-quality decoupled reconstruction of the human body wearing different clothing, and can be directly applied to clothing transfer and animation.