GPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
作者: Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-01-02 (更新: 2025-03-11)
备注: Project page: https://gpt4scene.github.io/
💡 一句话要点
GPT4Scene:利用视觉语言模型理解视频中的3D场景,提升具身智能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 视觉语言模型 鸟瞰图 视觉提示 具身智能 视频理解 全局-局部对应 零样本学习
📋 核心要点
- 现有视觉语言模型在3D空间理解方面存在局限性,尤其是在缺乏全局-局部对应关系时,性能显著下降。
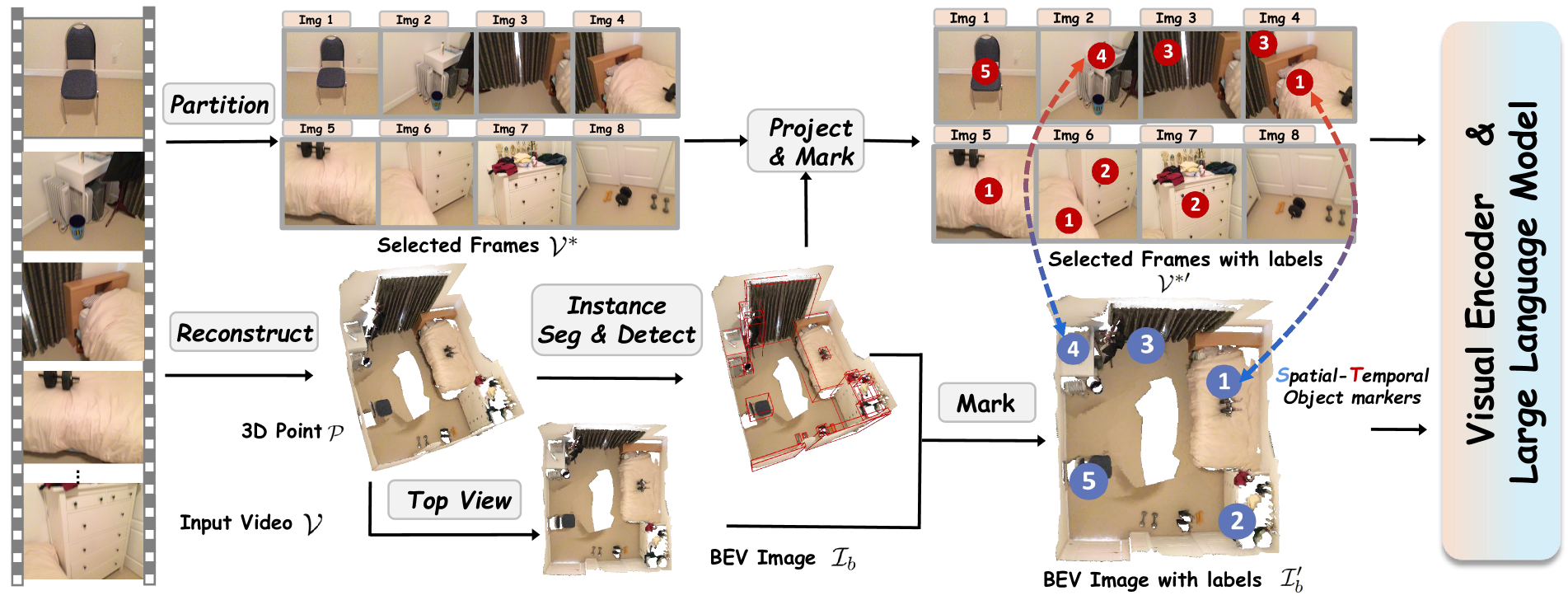
- GPT4Scene通过构建鸟瞰图(BEV)并标记对象ID,建立视频帧与BEV图像之间的全局-局部对应关系,从而提升3D场景理解能力。
- 实验结果表明,GPT4Scene在零样本评估中优于闭源VLMs,并且通过微调开源VLMs,在3D理解任务上实现了最先进的性能。
📝 摘要(中文)
近年来,2D视觉语言模型(VLMs)在图像-文本理解任务中取得了显著进展。然而,它们在3D空间理解方面的性能仍然有限,而3D空间理解对于具身智能至关重要。最近的研究利用3D点云和多视角图像作为输入,取得了有希望的结果。本文提出了一种纯粹基于视觉的解决方案,灵感来源于人类感知,仅依赖视觉线索进行3D空间理解。本文实证研究了VLMs在3D空间知识方面的局限性,发现其主要缺点在于场景和单个帧之间缺乏全局-局部对应关系。为了解决这个问题,我们引入了GPT4Scene,这是一种新颖的视觉提示范式,用于VLM训练和推理,有助于构建全局-局部关系,从而显著提高室内场景的3D空间理解能力。具体来说,GPT4Scene从视频中构建鸟瞰图(BEV)图像,并在帧和BEV图像中标记一致的对象ID。然后,模型输入连接的BEV图像和带有标记的视频帧。在零样本评估中,GPT4Scene的性能优于GPT-4o等闭源VLMs。此外,我们准备了一个包含165K文本注释的处理过的视频数据集,用于微调开源VLMs,从而在所有3D理解任务上实现了最先进的性能。令人惊讶的是,经过GPT4Scene范式训练后,VLMs在推理过程中始终得到改进,即使没有对象标记提示和BEV图像作为显式对应关系。这表明所提出的范式有助于VLMs发展理解3D场景的内在能力,这为无缝扩展预训练VLMs以进行3D场景理解铺平了道路。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)在理解3D场景时,尤其是在仅依赖视觉信息的情况下,表现不佳。它们缺乏将局部视频帧信息与全局场景布局联系起来的能力,导致对3D空间关系的理解不足。现有方法通常依赖于额外的3D信息(如点云)或多视角图像,限制了其在纯视觉场景下的应用。
核心思路:GPT4Scene的核心思路是通过引入鸟瞰图(BEV)作为全局场景的表示,并结合视觉提示,来弥合VLMs在局部帧信息和全局场景布局之间的差距。通过在视频帧和BEV图像中标记一致的对象ID,模型可以学习建立帧与场景之间的对应关系,从而提升对3D空间关系的理解。
技术框架:GPT4Scene的整体框架包括以下几个步骤:1) 从输入视频中构建BEV图像;2) 在视频帧和BEV图像中标记一致的对象ID;3) 将带有标记的视频帧和BEV图像连接起来,作为VLMs的输入;4) 使用包含文本注释的视频数据集对VLMs进行微调。在推理阶段,可以移除对象标记提示和BEV图像,利用模型学习到的内在3D场景理解能力。
关键创新:GPT4Scene的关键创新在于其视觉提示范式,它通过显式地构建全局-局部对应关系,帮助VLMs学习理解3D场景。与现有方法相比,GPT4Scene仅依赖于视觉信息,无需额外的3D数据或多视角图像。此外,GPT4Scene还提出了一种新的训练策略,即使在没有显式提示的情况下,也能提升VLMs的3D场景理解能力。
关键设计:在构建BEV图像时,需要选择合适的视角和分辨率,以保证场景信息的完整性和清晰度。对象ID的标记需要保证一致性,可以使用人工标注或自动跟踪算法。在微调VLMs时,可以使用交叉熵损失函数或对比学习损失函数,以鼓励模型学习帧与场景之间的对应关系。数据集包含165K文本注释的视频数据。
🖼️ 关键图片


📊 实验亮点
GPT4Scene在零样本评估中优于GPT-4o等闭源VLMs,证明了其有效性。通过在包含165K文本注释的视频数据集上微调开源VLMs,GPT4Scene在所有3D理解任务上实现了最先进的性能。更重要的是,经过GPT4Scene范式训练后,VLMs即使在没有对象标记提示和BEV图像的情况下,也能持续提升3D场景理解能力。
🎯 应用场景
GPT4Scene在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,GPT4Scene可以提高车辆对复杂交通场景的理解能力,从而提高驾驶安全性。在虚拟现实和增强现实领域,GPT4Scene可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
In recent years, 2D Vision-Language Models (VLMs) have made significant strides in image-text understanding tasks. However, their performance in 3D spatial comprehension, which is critical for embodied intelligence, remains limited. Recent advances have leveraged 3D point clouds and multi-view images as inputs, yielding promising results. However, we propose exploring a purely vision-based solution inspired by human perception, which merely relies on visual cues for 3D spatial understanding. This paper empirically investigates the limitations of VLMs in 3D spatial knowledge, revealing that their primary shortcoming lies in the lack of global-local correspondence between the scene and individual frames. To address this, we introduce GPT4Scene, a novel visual prompting paradigm in VLM training and inference that helps build the global-local relationship, significantly improving the 3D spatial understanding of indoor scenes. Specifically, GPT4Scene constructs a Bird's Eye View (BEV) image from the video and marks consistent object IDs across both frames and the BEV image. The model then inputs the concatenated BEV image and video frames with markers. In zero-shot evaluations, GPT4Scene improves performance over closed-source VLMs like GPT-4o. Additionally, we prepare a processed video dataset consisting of 165K text annotation to fine-tune open-source VLMs, achieving state-of-the-art performance on all 3D understanding tasks. Surprisingly, after training with the GPT4Scene paradigm, VLMs consistently improve during inference, even without object marker prompting and BEV image as explicit correspondence. It demonstrates that the proposed paradigm helps VLMs develop an intrinsic ability to understand 3D scenes, which paves the way for a seamless approach to extending pre-trained VLMs for 3D scene understanding.